Создание лучших виртуальных фонов для видеозвонков, удаленного присутствия и дополненной реальности
Pavel KuznetsovПеревод сделан в лаборатории CV Центра ИИ Контура.
Creating better virtual backdrops for video calling, remote presence, and AR
Wenliang Zhao, Georgy Marrero, Peizhao Zhang, Tao Xu, Chuck Zhang, Vignesh Ramanathan, Meta*, February 8, 2022
У Контура есть свой сервис видеозвонков — Толк, и мы делаем для него виртуальный фон. В процессе разработки модели мы используем опыт таких компаний как Google и Meta AI*.
Это перевод статьи команды исследователей из Meta AI*, в которой описаны различные подходы, которые помогли улучшить качество виртуального фона в сервисах и приложениях компании.
Приятного чтения!
С начала пандемии COVID-19 многие из нас привыкли видеть или использовать виртуальные фоны и фильтры для фона во время видеочатов с друзьями, коллегами или семьей. Изменение нашего фона во время видеозвонков дает нам больший контроль над нашим окружением, помогая устранять отвлекающие факторы, защищать конфиденциальность людей и пространства вокруг нас и даже оживлять наши виртуальные встречи и презентации. Но фильтры для фона не всегда работают оптимально и должным образом. Большинство из нас сталкивались с такими фильтрами для фона, которые, например, ошибочно закрывают чье-то лицо во время движения или не способны отличить руку от стола.
Чтобы улучшить размытие фона, виртуальный фон и многие другие эффекты дополненной реальности (AR) в продуктах и сервисах Meta*, мы развернули недавно усовершенствованные модели искусственного интеллекта для сегментации изображений — задачи компьютерного зрения по разделению различных частей фото или видео. Межфункциональная группа исследователей и инженеров из Meta AI*, Reality Labs и других подразделений компании создала новые модели сегментации, которые сейчас используются для видеозвонков в реальном времени в Spark AR в нескольких приложениях: Portal, Messenger и Instagram*. Мы также улучшили модели сегментации для двух человек, работающие на сегодняшний день в Instagram* и Messenger.
Эти системы теперь более эффективны, более стабильны и более универсальны, и это поможет повысить качество и согласованность эффектов фильтрации фона в наших продуктах. Например, наши улучшенные модели сегментации теперь можно использовать для нескольких людей, для всего тела человека, а также для людей, закрытых объектом, таким как диван или стол. Помимо видеозвонков, улучшенная сегментация также может привнести новые измерения в дополненную и виртуальную реальность (AR/VR) за счет объединения виртуальной среды с людьми и объектами в реальном мире. Это будет особенное значение, поскольку мы создаем новый иммерсивный опыт для метавселенной.
Работая над совершенствованием сегментации изображений, мы сосредоточились на трех важных задачах:
- Обучение наших моделей искусственного интеллекта хорошей работе в самых разных обстоятельствах, таких как условия слабого освещения, различия в оттенках кожи, ситуации, когда тона кожи похожи на цвета фона, менее распространенные позы тела (например, кто-то наклоняется вперед, чтобы завязать шнурки или потягивается), окклюзии и движения.
- Улучшение гладкости границ, стабильности и общей согласованности. Эти качества меньше обсуждаются в существующей исследовательской литературе, но исследования пользователей показали, что они сильно влияют на опыт людей при использовании фоновых эффектов.
- Обеспечение достаточной эффективности и гибкости наших моделей для хорошей работы на миллиардах смартфонов, используемых в настоящее время по всему миру, а не только на небольшой их части, которая представляет собой устройства текущего поколения с передовыми процессорами. Модели также должны были поддерживать очень разные соотношения сторон, чтобы хорошо работать на ноутбуках, устройствах для видеовызовов Meta* Portal, а также в портретном и ландшафтном режимах на телефонах.
Проблемы сегментации людей в реальном мире
В то время как концепция сегментации изображения проста для понимания, достижение высокоточной сегментации человека сопряжено со значительными трудностями. Чтобы создать хороший продукт, модель должна быть хорошо согласованной и работать без задержек. Артефакты, вызванные неправильным выводом сегментации, могут отвлекать людей, использующих приложения с виртуальным фоном во время видеозвонка. Что еще более важно, ошибки сегментации могут привести к нежелательному показу физического окружения людей при использовании фоновых эффектов.
По этим причинам для развертывания моделей сегментации человека в продакшн важно достичь высокой точности — более 90 процентов Intersection over Union (IoU), широко используемой метрики для измерения совпадения между прогнозом сегментации изображения и истинной маской. Из-за огромного разнообразия возможных случаев преодолеть последние остающиеся 10 процентов в IoU экспоненциально труднее, чем первые 90. Мы обнаружили, что когда IoU достигает 90 процентов, метрика становится насыщенной и не может отражать дальнейшие улучшения временной согласованности и стабильности границ. Поэтому мы разработали систему оценки для видео совместно с несколькими показателями для фиксации этих дополнительных измерений.
Разработка стратегий обучения и оценки в реальном мире
Модели искусственного интеллекта учатся на данных, которые им предоставляются, поэтому недостаточно просто использовать примеры видеозвонков, где люди сидят неподвижно в хорошо освещенных комнатах. Чтобы создать высокоточные модели сегментации для широкого спектра случаев, нам нужно было использовать много других видов примеров.
Мы использовали модель ClusterFit от Meta AI*, чтобы извлечь из нашего набора данных широкий спектр примеров относительно пола, оттенка кожи, возраста, позы тела, движения, сложности фона, количества людей и т.д.
Метрики на статических изображениях не отражают точность модели в режиме реального времени, поскольку модели в режиме реального времени обычно имеют режим трекинга, который основывается на временной информации. Чтобы измерить качество наших моделей в режиме реального времени, мы разработали количественную систему оценки видео, которая вычисляет метрики на каждом кадре при инференсе модели.
В отличие от стандартных академических задач по сегментации, качество нашей модели сегментации людей лучше всего оценивается ее производительностью в повседневных ситуациях. Если эффект выглядит резким, отвлекающим или иным образом некорректным, то производительность модели по сравнению с каким-либо конкретным показателем будет незначительной. Поэтому мы опросили пользователей наших продуктов, задав вопрос о качестве наших сегментационных приложений. Мы обнаружили, что неплавные и неоднозначные границы больше всего влияют на впечатление пользователей. Чтобы зафиксировать этот сигнал, мы дополнили нашу методологию метрикой, Boundary IoU, новой оценкой сегментации, созданной исследователями Meta AI* для измерения качества границ. Boundary IoU становится более интересным, когда общий IoU близок к насыщению, т.е. выше 90 процентов.
Кроме того, дрожание (временная несогласованность) на границе также портит впечатление. Мы измеряем временную согласованность с помощью двух методов. Во-первых, мы предполагаем, что смежные видеокадры идентичны друг другу, и любое расхождение в предсказаниях указывает на временную несогласованность модели. Во-вторых, мы рассматриваем передний план между смежными видеокадрами. Оптический поток может помочь нам преобразовать предсказание кадра N в N+1. Затем мы можем сравнить это преобразованное предсказание с исходным предсказанием на кадре N+1 и использовать IoU для подсчета расхождения. В обоих случаях мы используем IoU для измерения расхождений.
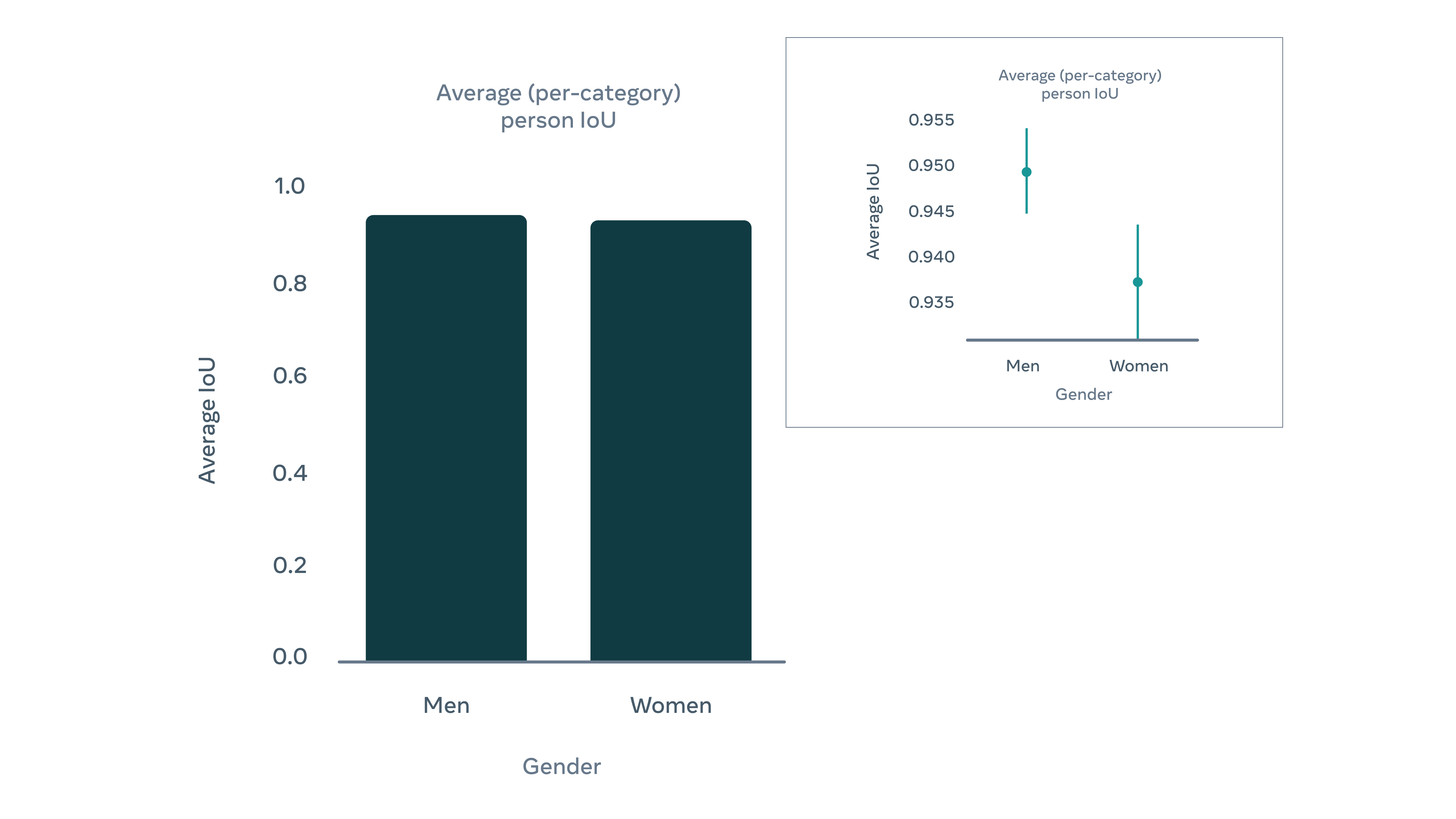
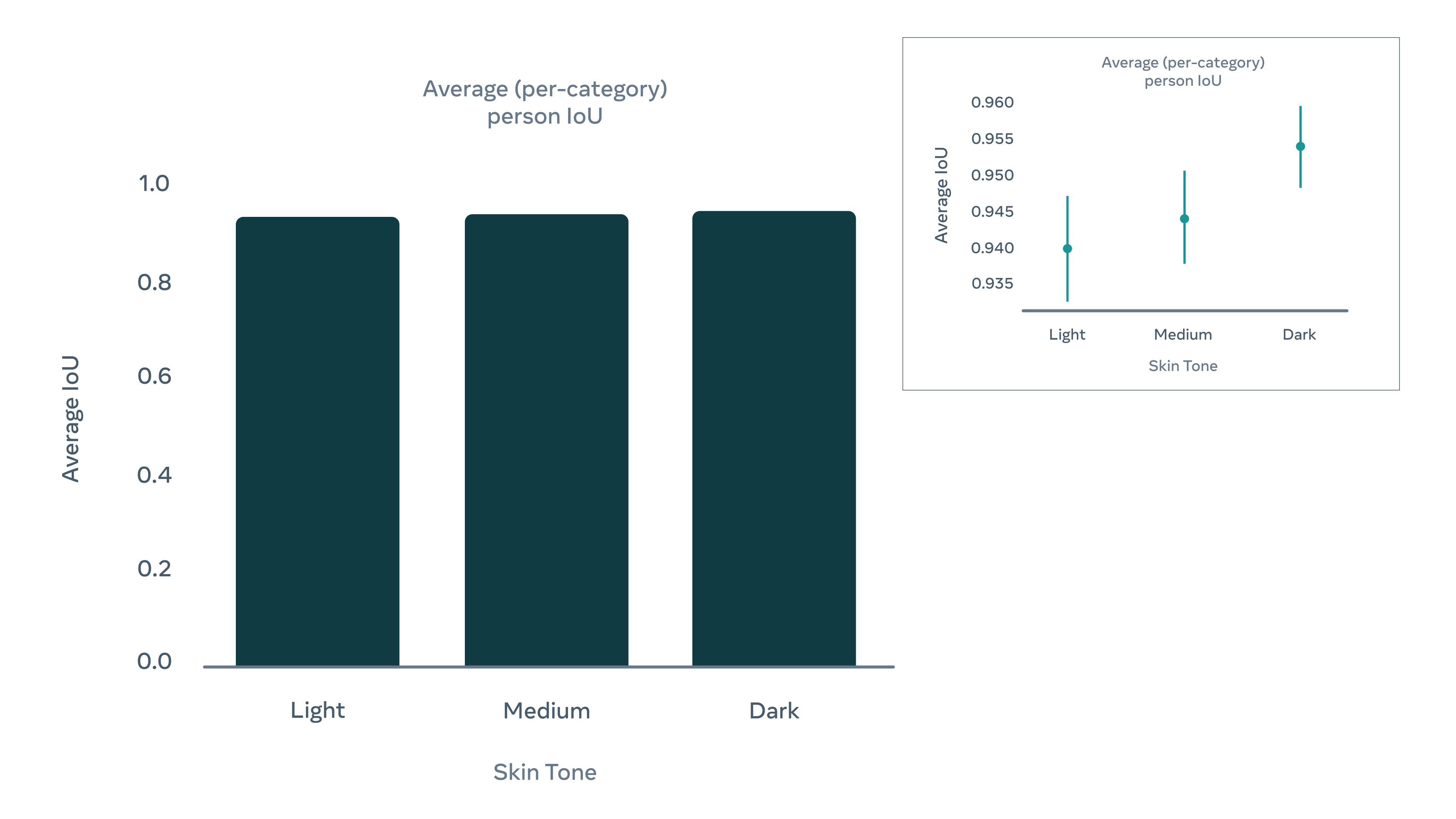
Также мы проанализировали наши модели на предмет различий в их работе среди конкретных групп людей. Мы разметили видео для оценки метаданными из более чем 100 классов (более чем 30 категорий), включая три оттенка кожи (определяемые путем кластеризации типов кожи по шкале Фицпатрика) и две категории бинарного пола. Модель показала сходную точность работы как для категорий оттенка кожи, так и для двух категорий пола. Несмотря на некоторые очень незначительные различия между категориями, которые мы приоритизируем в нашей текущей работе, модель демонстрирует хорошую производительность во всех подкатегориях.
Оптимизация модели
Архитектура
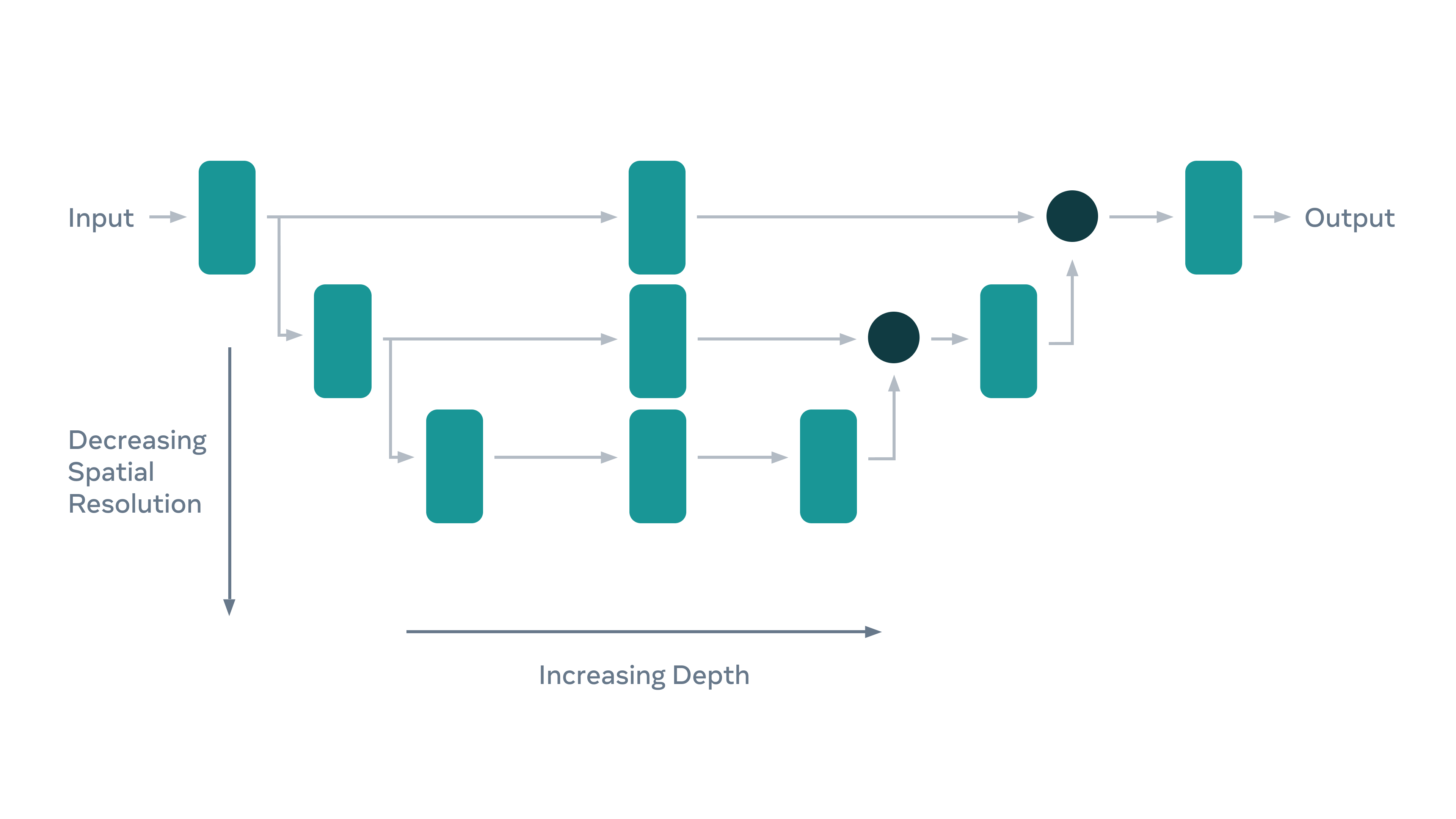
Для оптимизации наших моделей мы используем FBNet V3 в качестве бэкбона. Архитектура представляет собой структуру энкодер-декодер со слиянием слоев одинакового пространственного разрешения. Мы спроектировали тяжелый энкодер с легким декодером, который обеспечивает лучшее качество по сравнению с симметричным дизайном архитектуры. Архитектура получена при помощи поиска нейронной архитектуры и хорошо оптимизирована для высокой скорости инференса на устройстве.
Обучение с эффективным использованием данных
Мы использовали большую офлайн модель PointRend для создания псевдоистинной разметки для неаннотированных данных, чтобы увеличить объем обучающей выборки. Также мы использовали полуконтролируемую модель «ученик-учитель», чтобы устранить смещение в псевдоразметке.
Передискретизация в зависимости от соотношения сторон
Традиционная модель глубокого обучения преобразует картинку в маленькое квадратное изображение в качестве входных данных для сети. Из-за этой передискретизации возникают различные искажения. А так как изображения имеют разное соотношение сторон, то и искажения тоже разные. Наличие искажений и их вариации заставляют сеть изучать низкоуровневые признаки, неустойчивые к различным соотношениям сторон. Ограничения, вызванные такими искажениями, усиливаются в сегментационных приложениях. Например, когда большинство обучающих изображений имеют портретное соотношение, модель работает намного хуже на пейзажных изображениях и видео. Чтобы решить эту проблему, мы адаптировали метод передискретизации в зависимости от соотношения сторон, предложенный в Detectron 2, который группирует изображения с одинаковыми соотношениями сторон и передискретизирует их все до одинакового размера.

Собственный паддинг
Передискретизация, зависящая от соотношения сторон, требует паддинга для групп изображений с одинаковым соотношением сторон, но обычно используемый метод заполнения нулями создает артефакты. Более того, артефакты распространяются на другие области, когда сеть становится глубже. Мы используем повторение, для удаления этих артефактов. В недавнем исследовании мы обнаружили, что отражение в слоях свертки может еще больше улучшить качество модели за счет минимизации распространения артефактов, но соответственно увеличиваются временные затраты. Пример артефакта и результат при его удалении показан ниже.

Трекинг
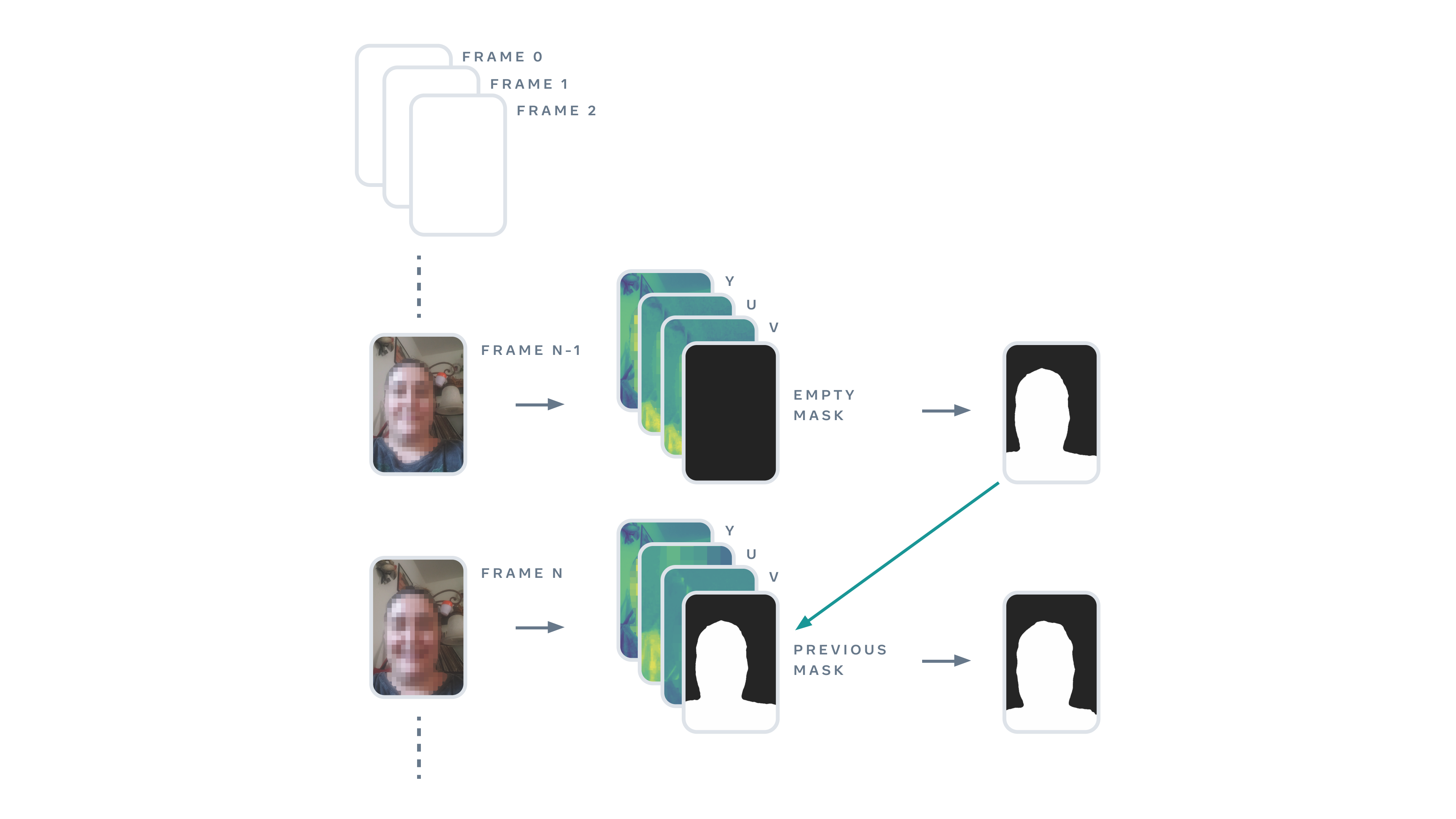
Временная несогласованность представляет из себя несоответствие предсказания от кадра к кадру, известное как мерцание (flickering), ухудшающее работу для пользователя. Чтобы улучшить временную согласованность, мы разработали процесс детекции с маской. Он включает три канала из текущего кадра (YUV), а также четвертый канал. Для первого кадра четвертый канал представляет собой пустую матрицу, а для следующих кадров четвертый канал — это предсказание предыдущего кадра. Мы обнаружили, что эта стратегия трекинга значительно улучшает временную согласованность. Мы также переняли некоторые идеи современных моделей трекинга, таких как CRVOS и инвариантной к преобразованиям CNN стратегии моделирования, чтобы получить стабильную во времени модель сегментации.
Граничная кросс энтропия
Создание плавных и четких границ имеет решающее значение для AR приложений сегментации. Помимо стандартной кросс-энтропийной функции потерь для сегментации, нам также необходимо учитывать взвешенные потери на границах. Авторы U-Net и большинства более поздних вариантов рекомендуют взвешенный тримэп лосс для улучшения качества модели, учитывая наблюдение, что внутренние области объектов легче сегментировать. Тем не менее, одним из ограничений тримэп лосса является то, что он вычисляет граничную область только на основе истинной маски, поэтому это асимметричный лосс, нечувствительный к ложноположительным срабатываниям. Вдохновленные Boundary IoU, мы применяем их метод извлечения граничных областей как для истинной маски, так и для предсказания, и вычисляем кросс-энтропийную функцию потерь в этих областях. Модель, обученная с помощью граничной кросс-энтропии, значительно превосходит базовую. Помимо того, что граничная область в окончательном выводе маски стала более четкой, ложно положительные срабатывания новых моделей случаются реже, что ожидаемо в соответствии с теорией.
Производительность
Все наши модели обучаются офлайн с использованием PyTorch, а затем развертываются в рабочей среде с помощью платформы Spark AR. Мы используем PyTorch Lite для оптимизации инференса модели глубокого обучения на устройстве. Поскольку варианты использования и оборудование для приложений и устройств различаются, мы разрабатываем разные модели, чтобы удовлетворить этим требованиям. После 1,5 лет разработки наша команда успешно улучшила модели сегментации людей в нескольких приложениях и устройствах Facebook*.
Создание лучших моделей сегментации для видеочатов и многого другого
Мы значительно улучшили наши модели сегментации, но работа еще продолжается. Мы надеемся создать эффекты, основанные на сегментации, которые будут безупречно адаптироваться к самым сложным, вызывающим трудности и необычным случаям использования. В частности, мы продолжаем работать над новыми способами улучшения стабильности границ и временной последовательности, которые являются важными для приложений сегментации человека в AR/VR. Мы работаем над созданием продвинутых методов трекинга, которые обеспечат более последовательное предсказание, особенно на краях объектов.
Мы также продолжим совершенствовать наши инструменты для оценки эффективности моделей в различных аспектах разнообразия людей по всему миру.
Мы надеемся, что, поделившись подробностями о нашей работе, мы поможем другим исследователям и инженерам в создании лучших сегментационных приложений, которые будут хорошо работать для всех пользователей.
*Деятельность Meta Platforms Inc. по реализации продуктов – социальных сетей Facebook и Instagram на территории Российской Федерации запрещена как экстремистская.