Создание и тренировка Нейронной Сети с нуля в Python 2 часть
Пример тренировки нейронной сети — минимизация потерь, Часть 1
Предположим, у нас есть следующие параметры:
Имя/NameВес/Weight (фунты)Рост/Height (дюймы)Пол/Gender Alice13365FBob16072MCharlie15270MDiana12060FДавайте натренируем нейронную сеть таким образом, чтобы она предсказывала пол заданного человека в зависимости от его веса и роста.
Мужчины Male будут представлены как 0, а женщины Female как 1. Для простоты представления данные также будут несколько смещены.
Имя/NameВес/Weight (минус 135)Рост/Height (минус 66)Пол/Gender Alice-2-11Bob2560Charlie1740Diana-15-61Для оптимизации здесь произведены произвольные смещения135и66. Однако, обычно для смещения выбираются средние показатели.
Потери
Перед тренировкой нейронной сети потребуется выбрать способ оценки того, насколько хорошо сеть справляется с задачами. Это необходимо для ее последующих попыток выполнять поставленную задачу лучше. Таков принцип потери.
В данном случае будет использоваться среднеквадратическая ошибка (MSE) потери:
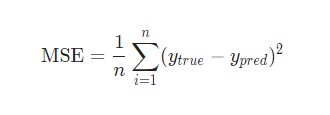
Давайте разберемся:
n– число рассматриваемых объектов, которое в данном случае равно 4. ЭтоAlice,Bob,CharlieиDiana;y– переменные, которые будут предсказаны. В данном случае это пол человека;ytrue– истинное значение переменной, то есть так называемый правильный ответ. Например, дляAliceзначениеytrueбудет1, то естьFemale;ypred– предполагаемое значение переменной. Это результат вывода сети.
(ytrue - ypred)2 называют квадратичной ошибкой (MSE). Здесь функция потери просто берет среднее значение по всем квадратичным ошибкам. Отсюда и название ошибки. Чем лучше предсказания, тем ниже потери.
Лучшие предсказания = Меньшие потери.
Тренировка нейронной сети = стремление к минимизации ее потерь.
Пример подсчета потерь в тренировки нейронной сети
Скажем, наша сеть всегда выдает 0. Другими словами, она уверена, что все люди — Мужчины. Какой будет потеря?
Python код среднеквадратической ошибки (MSE)
Ниже представлен код для подсчета потерь:
Python
1
2
3
4
5
6
7
8
9
10
11
12
import numpy as np
def mse_loss(y_true, y_pred):
# y_true и y_pred являются массивами numpy с одинаковой длиной
return ((y_true - y_pred) ** 2).mean()
y_true = np.array([1, 0, 0, 1])
y_pred = np.array([0, 0, 0, 0])
print(mse_loss(y_true, y_pred)) # 0.5
При возникновении сложностей с пониманием работы кода стоит ознакомиться с quickstart в NumPy для операций с массивами.
Тренировка нейронной сети — многовариантные исчисления, Часть 2
Текущая цель понятна – это минимизация потерь нейронной сети. Теперь стало ясно, что повлиять на предсказания сети можно при помощи изменения ее веса и смещения. Однако, как минимизировать потери?
В этом разделе будут затронуты многовариантные исчисления. Если вы не знакомы с данной темой, фрагменты с математическими вычислениями можно пропускать.
Для простоты давайте представим, что в наборе данных рассматривается только Alice:
Имя/NameВес/Weight (минус 135)Рост/Height (минус 66)Пол/GenderAlice-2-11Затем потеря среднеквадратической ошибки будет просто квадратической ошибкой для Alice:
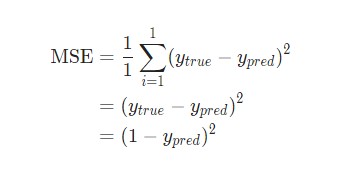
Еще один способ понимания потери – представление ее как функции веса и смещения. Давайте обозначим каждый вес и смещение в рассматриваемой сети:
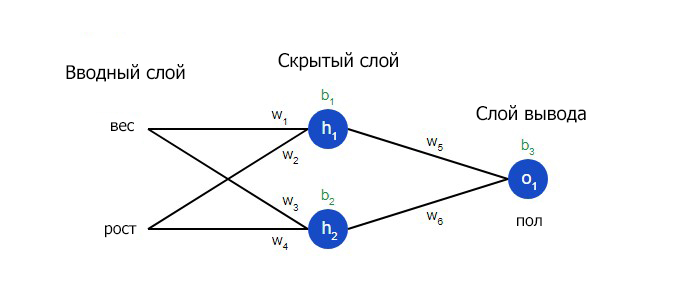
Затем можно прописать потерю как многовариантную функцию:

Представим, что нам нужно немного отредактировать w1. В таком случае, как изменится потеря L после внесения поправок в w1?
На этот вопрос может ответить частная производная
. Как же ее вычислить?
Здесь математические вычисления будут намного сложнее. С первой попытки вникнуть будет непросто, но отчаиваться не стоит. Возьмите блокнот и ручку – лучше делать заметки, они помогут в будущем.
Для начала, давайте перепишем частную производную в контексте
:
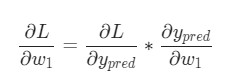
Данные вычисления возможны благодаря дифференцированию сложной функции.
Подсчитать
можно благодаря вычисленной выше L = (1 - ypred)2:
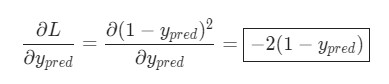
Теперь, давайте определим, что делать с
. Как и ранее, позволим h1, h2, o1 стать результатами вывода нейронов, которые они представляют. Дальнейшие вычисления:
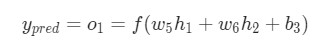
Как было указано ранее, здесь f является функцией активации сигмоида.
Так как w1 влияет только на h1, а не на h2, можно записать:
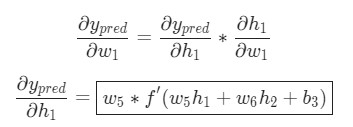
Использование дифференцирования сложной функции.
Те же самые действия проводятся для
:
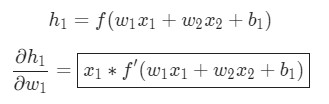
Еще одно использование дифференцирования сложной функции.
В данном случае х1 — вес, а х2 — рост. Здесь f′(x) как производная функции сигмоида встречается во второй раз. Попробуем вывести ее:
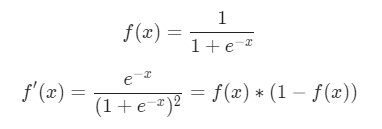
Функция f'(x) в таком виде будет использована несколько позже.
Вот и все. Теперь
разбита на несколько частей, которые будут оптимальны для подсчета:
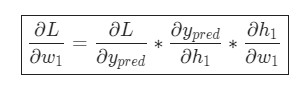
Эта система подсчета частных производных при работе в обратном порядке известна, как метод обратного распространения ошибки, или backprop.
У нас накопилось довольно много формул, в которых легко запутаться. Для лучшего понимания принципа их работы рассмотрим следующий пример.
Пример подсчета частных производных
В данном примере также будет задействована только Alice:
Имя/NameВес/Weight (минус 135)Рост/Height (минус 66)Пол/GenderAlice-2-11Здесь вес будет представлен как 1, а смещение как 0. Если выполним прямое распространение (feedforward) через сеть, получим:
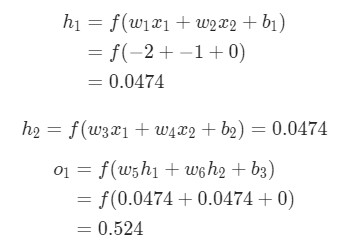
Выдачи нейронной сети ypred = 0.524. Это дает нам слабое представление о том, рассматривается мужчина Male (0), или женщина Female (1). Давайте подсчитаем
:

Напоминание: мы вывели f '(x) = f (x) * (1 - f (x)) ранее для нашей функции активации сигмоида.У нас получилось! Результат говорит о том, что если мы собираемся увеличить w1, L немного увеличивается в результате.
Тренировка нейронной сети: Стохастический градиентный спуск
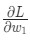
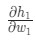
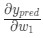
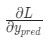
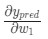
У нас есть все необходимые инструменты для тренировки нейронной сети. Мы используем алгоритм оптимизации под названием стохастический градиентный спуск (SGD), который говорит нам, как именно поменять вес и смещения для минимизации потерь. По сути, это отражается в следующем уравнении:
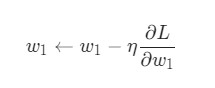
η является константой под названием оценка обучения, что контролирует скорость обучения. Все что мы делаем, так это вычитаем
из w1:
- Если
- положительная,
w1уменьшится, что приведет к уменьшениюL. - Если
- отрицательная,
w1увеличится, что приведет к уменьшениюL.
Если мы применим это на каждый вес и смещение в сети, потеря будет постепенно снижаться, а показатели сети сильно улучшатся.
Наш процесс тренировки будет выглядеть следующим образом:
- Выбираем один пункт из нашего набора данных. Это то, что делает его стохастическим градиентным спуском. Мы обрабатываем только один пункт за раз;
- Подсчитываем все частные производные потери по весу или смещению. Это может быть
- ,
- и так далее;
- Используем уравнение обновления для обновления каждого веса и смещения;
- Возвращаемся к первому пункту.
Давайте посмотрим, как это работает на практике.
Создание нейронной сети с нуля на Python
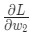
Наконец, мы реализуем готовую нейронную сеть:
Имя/NameВес/Weight (минус 135)Рост/Height (минус 66)Пол/GenderAlice-2-11Bob2560Charlie1740Diana-15-61
import numpy as np
def sigmoid(x):
# Функция активации sigmoid:: f(x) = 1 / (1 + e^(-x))
return 1 / (1 + np.exp(-x))
def deriv_sigmoid(x):
# Производная от sigmoid: f'(x) = f(x) * (1 - f(x))
fx = sigmoid(x)
return fx * (1 - fx)
def mse_loss(y_true, y_pred):
# y_true и y_pred являются массивами numpy с одинаковой длиной
return ((y_true - y_pred) ** 2).mean()
class OurNeuralNetwork:
"""
Нейронная сеть, у которой:
- 2 входа
- скрытый слой с двумя нейронами (h1, h2)
- слой вывода с одним нейроном (o1)
*** ВАЖНО ***:
Код ниже написан как простой, образовательный. НЕ оптимальный.
Настоящий код нейронной сети выглядит не так. НЕ ИСПОЛЬЗУЙТЕ этот код.
Вместо этого, прочитайте/запустите его, чтобы понять, как работает эта сеть.
"""
def __init__(self):
# Вес
self.w1 = np.random.normal()
self.w2 = np.random.normal()
self.w3 = np.random.normal()
self.w4 = np.random.normal()
self.w5 = np.random.normal()
self.w6 = np.random.normal()
# Смещения
self.b1 = np.random.normal()
self.b2 = np.random.normal()
self.b3 = np.random.normal()
def feedforward(self, x):
# x является массивом numpy с двумя элементами
h1 = sigmoid(self.w1 * x[0] + self.w2 * x[1] + self.b1)
h2 = sigmoid(self.w3 * x[0] + self.w4 * x[1] + self.b2)
o1 = sigmoid(self.w5 * h1 + self.w6 * h2 + self.b3)
return o1
def train(self, data, all_y_trues):
"""
- data is a (n x 2) numpy array, n = # of samples in the dataset.
- all_y_trues is a numpy array with n elements.
Elements in all_y_trues correspond to those in data.
"""
learn_rate = 0.1
epochs = 1000 # количество циклов во всём наборе данных
for epoch in range(epochs):
for x, y_true in zip(data, all_y_trues):
# --- Выполняем обратную связь (нам понадобятся эти значения в дальнейшем)
sum_h1 = self.w1 * x[0] + self.w2 * x[1] + self.b1
h1 = sigmoid(sum_h1)
sum_h2 = self.w3 * x[0] + self.w4 * x[1] + self.b2
h2 = sigmoid(sum_h2)
sum_o1 = self.w5 * h1 + self.w6 * h2 + self.b3
o1 = sigmoid(sum_o1)
y_pred = o1
# --- Подсчет частных производных
# --- Наименование: d_L_d_w1 представляет "частично L / частично w1"
d_L_d_ypred = -2 * (y_true - y_pred)
# Нейрон o1
d_ypred_d_w5 = h1 * deriv_sigmoid(sum_o1)
d_ypred_d_w6 = h2 * deriv_sigmoid(sum_o1)
d_ypred_d_b3 = deriv_sigmoid(sum_o1)
d_ypred_d_h1 = self.w5 * deriv_sigmoid(sum_o1)
d_ypred_d_h2 = self.w6 * deriv_sigmoid(sum_o1)
# Нейрон h1
d_h1_d_w1 = x[0] * deriv_sigmoid(sum_h1)
d_h1_d_w2 = x[1] * deriv_sigmoid(sum_h1)
d_h1_d_b1 = deriv_sigmoid(sum_h1)
# Нейрон h2
d_h2_d_w3 = x[0] * deriv_sigmoid(sum_h2)
d_h2_d_w4 = x[1] * deriv_sigmoid(sum_h2)
d_h2_d_b2 = deriv_sigmoid(sum_h2)
# --- Обновляем вес и смещения
# Нейрон h1
self.w1 -= learn_rate * d_L_d_ypred * d_ypred_d_h1 * d_h1_d_w1
self.w2 -= learn_rate * d_L_d_ypred * d_ypred_d_h1 * d_h1_d_w2
self.b1 -= learn_rate * d_L_d_ypred * d_ypred_d_h1 * d_h1_d_b1
# Нейрон h2
self.w3 -= learn_rate * d_L_d_ypred * d_ypred_d_h2 * d_h2_d_w3
self.w4 -= learn_rate * d_L_d_ypred * d_ypred_d_h2 * d_h2_d_w4
self.b2 -= learn_rate * d_L_d_ypred * d_ypred_d_h2 * d_h2_d_b2
# Нейрон o1
self.w5 -= learn_rate * d_L_d_ypred * d_ypred_d_w5
self.w6 -= learn_rate * d_L_d_ypred * d_ypred_d_w6
self.b3 -= learn_rate * d_L_d_ypred * d_ypred_d_b3
# --- Подсчитываем общую потерю в конце каждой фазы
if epoch % 10 == 0:
y_preds = np.apply_along_axis(self.feedforward, 1, data)
loss = mse_loss(all_y_trues, y_preds)
print("Epoch %d loss: %.3f" % (epoch, loss))
# Определение набора данных
data = np.array([
[-2, -1], # Alice
[25, 6], # Bob
[17, 4], # Charlie
[-15, -6], # Diana
])
all_y_trues = np.array([
1, # Alice
0, # Bob
0, # Charlie
1, # Diana
])
# Тренируем нашу нейронную сеть!
network = OurNeuralNetwork()
network.train(data, all_y_trues)
Теперь мы можем использовать нейронную сеть для предсказания полов:
# Делаем предсказания
emily = np.array([-7, -3]) # 128 фунтов, 63 дюйма
frank = np.array([20, 2]) # 155 фунтов, 68 дюймов
print("Emily: %.3f" % network.feedforward(emily)) # 0.951 - F
print("Frank: %.3f" % network.feedforward(frank)) # 0.039 - M