Слова как векторы
БиомолекулаВместо one-hot кодирования современные модели используют технологию векторизации (представления слова в виде набора чисел), которую называют эмбеддинг. Здесь важно сделать оговорку, что эмбеддинг — это одновременно и процесс превращения слова в вектор, и полученный вектор.
Что позволяет различить значения слова предложении? С этим помогает контекст — слова, которые находятся в непосредственной близости от определенного слова. Именно эту идею — учет контекста для векторизации слов — используют разработчики более современных языковых моделей.
Ученые начали с подсчета, как часто пары слов встречаются вместе в обучающей выборке. В результате получалась большая таблица «совстречаемости» размером N⨉N, где N — число слов в словаре. В каждой клеточке такой таблицы записана вероятность встретить два слова из обучающей выборки недалеко друг от друга. Чтобы учесть контекст слова в его эмбеддинге, можно включить в него эмбеддинги соседних слов. При этом мы хотим, чтобы часто встречающиеся вместе слова сильно влияли на эмбеддинги друг друга, а редко встречающиеся — слабо: так можно учесть контекст. Самый простой способ добиться такого поведения — скомбинировать one-hot эмбеддинги нашего слова и его соседей, «взвешенные» на частоту совстречаемости.
Но такой статистический подход не решил всех проблем. Помимо неспособности «запоминать», что было сказано в тексте несколько предложений назад, матрицы совстречаемости не позволяли восстанавливать семантическую связь между словами.
Объясним, что такое семантическая связь, на классическом примере. Как связаны между собой эти четыре слова: «король», «королева», «мужчина» и «женщина»? Нам интуитивно понятно, что король и королева — это мужчина и женщина в королевском статусе. Поэтому «условная» разница между королем и королевой для нас такая же, как и разница между мужчиной и женщиной. И мы, конечно, хотим, чтобы эмбеддинги этих четырех слов сохраняли эту семантическую связь. Добиться этого позволили модели word2vec.
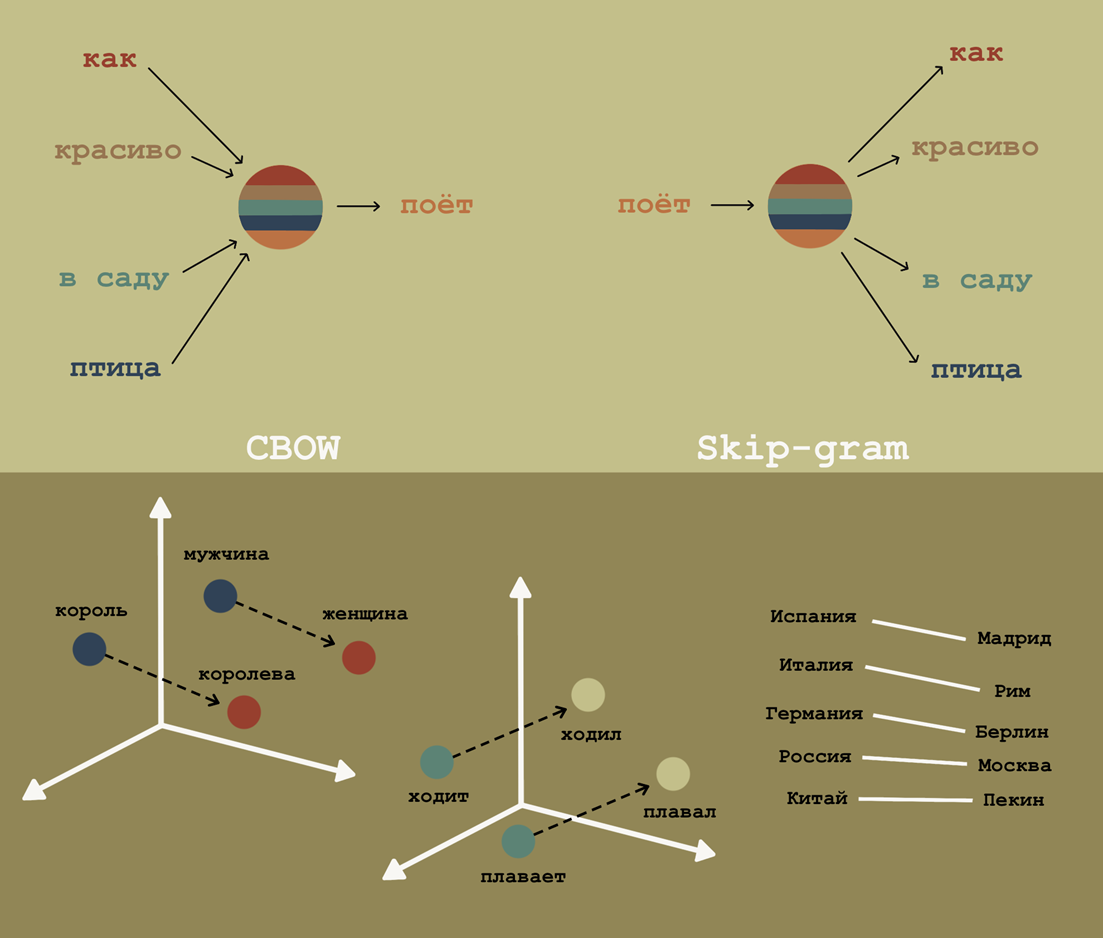
Снизу: Как отличить мужчину от женщины? Модель word2vec поможет! Она сохраняет связи не только между четверкой слов «король», «королева», «мужчина» и «женщина», но и позволяет восстановить связь между временными формами слов или между страной и ее столицей. В интернете можно найти множество «калькуляторов» word2vec, которые по тройке слов восстанавливают четвертое.
Как это все связано с биологией? Мы уже научили языковые модели работать с текстом, что открывает огромный простор для покорения мира белковых молекул. Подробнее об использовании языковых моделей для изучения биомолекул читайте в статье.