Shading ландшафта
Lizzy Fox - https://t.me/infinity_world_developer_diary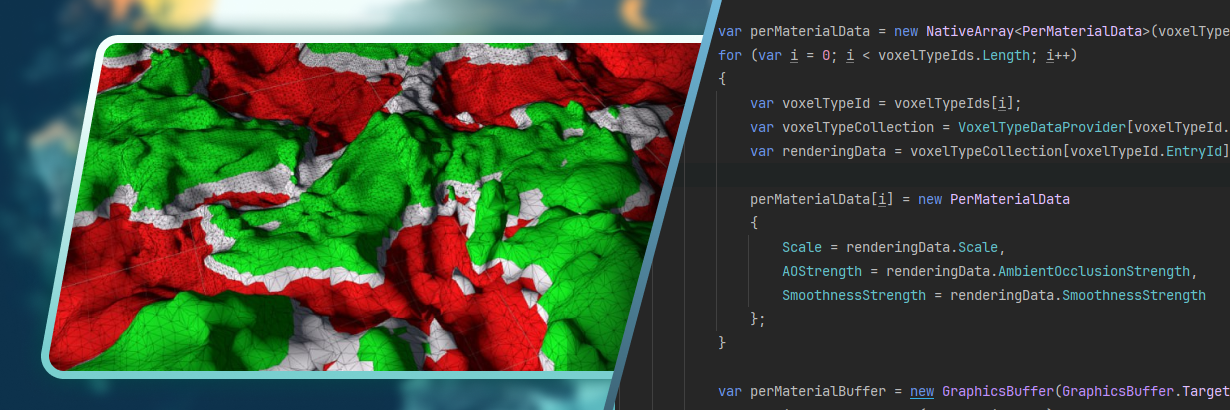
Как же я рисую ландшафт?

Вы могли заметить, что ландшафт уже не просто залит одним цветом, а вполне себе затекстурен, причем смешивание плавное. Есть поддержка множества материалов (до 32 на чанк и 4 на пиксель), материалы могут быть разными. Хотя так было не всегда...
Первые попытки
В самом начале, я рассматривала материалы ландшафта как отдельные сабмеши. То есть каждый воксель мог иметь материал и определял индекс сабмеша для каждого чанка. Как именно?
Когда я генерирую ландшафт мне необходимо оценить каждый воксель, который потенциально может содержать поверхность. Вместе с генерацией SDF значения и его градиента можно еще оценить и потенциальный материал. На этом этапе материал представляет из себя просто идентификатор, который точно определяет к какому биому (набору типов вокселей и правил генерации) он относится и к какому конкретно типу вокселя из этого биома.
Набор типов вокселей для каждого чанка всегда уникальный, так как внутри одного чанка могут смешиваться разные материалы из разных биомов. Это очень важно понимать, потому что вся архитектура генерации строится основываясь на уникальности данных в каждом взятом чанке.
Но как хранить этот набор материалов? Я использую спарс-массив, потому что мне требуется не только быстро составить этот уникальный набор (повторения невозможны), но и быстро потом находить по индексу (порядок важен). Индекс - это локальный индекс в спарс-массиве per chunk от 0 до N, где N - максимальное количество материалов в чанке. Этот самый индекс и определяет индекс сабмеша в чанке.

Не очень выглядит, правда? Резкие переходы, углы, а вдалеке так совсем ужасно.
Дальнейшие исследования
Через какое-то время я вернулась к задаче текстуринга ландшафта. Долго размышляла, как можно реализовать смешивание различных материалов, ведь хочется, чтобы каждый материал обладал множеством свойств. Где-то материал должен быть диффузным, где-то - отдавать металлом (руда например), где-то - быть мокрым, а где-то иметь эффект проваливания (снег и грязь).
В итоге я пришла к мысли, что материал необходимо рассматривать как набор настроек и идентификаторов текстур, а шейдер должен быть один. А после просмотра презентации от Hello Games по игре No Man's Sky на GDC я поняла, чего мне не хватало.
Вроде бы простая истина, но чтобы до нее дойти пришлось потратить немало сил.
Что это значит для задачи по материалам? А то, что в смешивании материалов мы также должны оперировать вокселями!
Давайте представим, что как и раньше у каждого вокселя есть материал. Мы знаем, что при генерации поверхности мы оцениваем воксели и их материалы. Но оцениваем мы как? По SDF и не каждую точку пространства (что невозможно), а с определенным шагом. Значит, первое, что мы должны сделать, так это сказать: "у вокселя теперь N материалов, которые наиболее часто встречаются в нем".
Я выбрала N = 4, так как 4 идентификатора материала легко упаковать в вектор и столько материалов дают уже достаточную детальность.
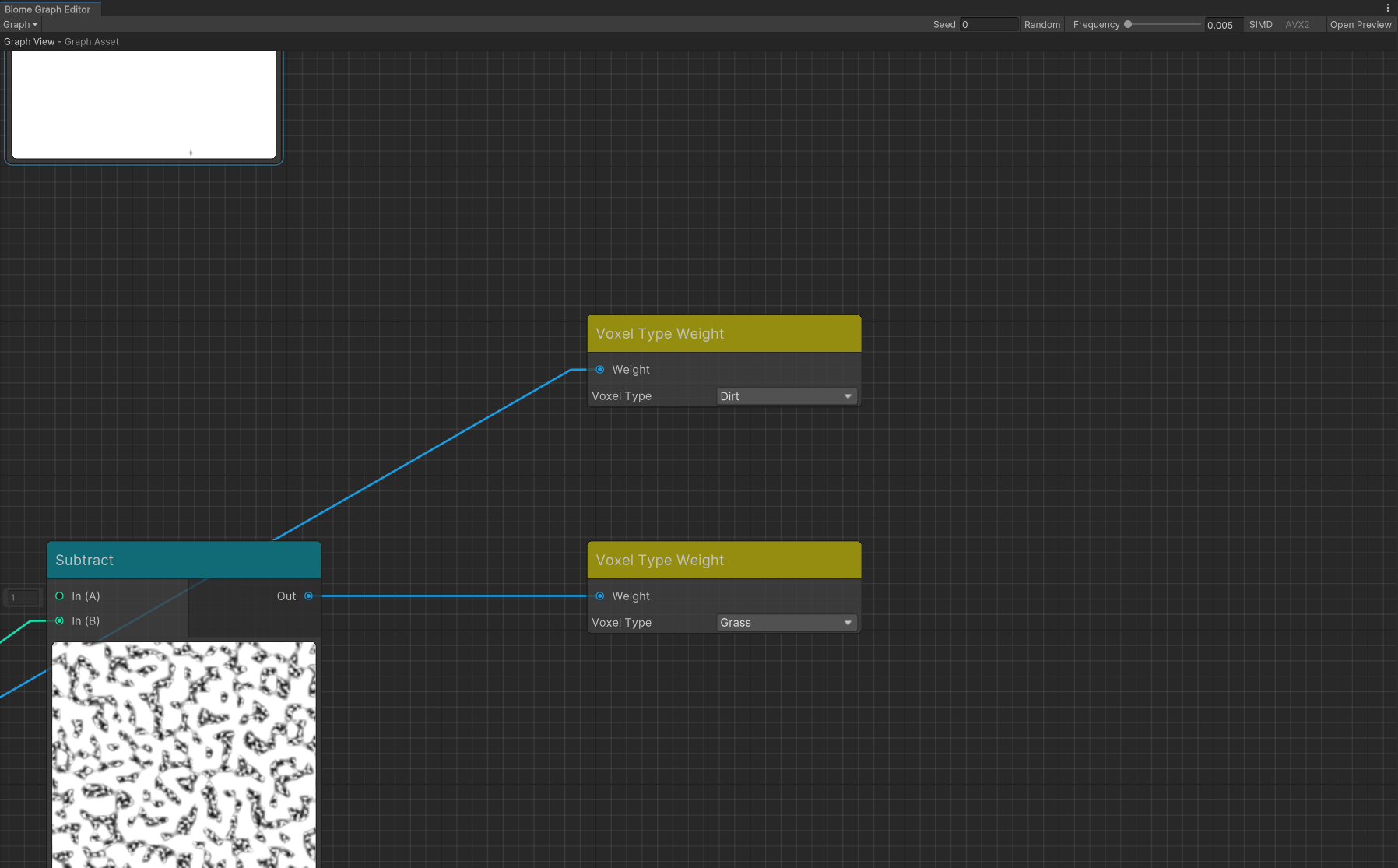
Дальше, на этапе генерации вершин, мы работаем уже с набором вокселей. Когда выбираем где же должна быть вершина, для нее также выбираем самые часто встречающиеся (с большим весом) материалов из всех вокселей, от которых она зависит.
Каждая вершина зависит от 9 вокселей (угловые и центральный), то есть получается набор из 36 материалов на вершину!
Детальность повышается и это радует.

Но в вершине данные о материалов я не храню. Проблем тут несколько:
- надо дублировать вершины, чтобы хранить разные веса и индексы материалов для разных треугольников;
- дополнительные данные в вершине, хотя они относятся к примитиву (треугольнику);
- нельзя не интерполировать данные между вершинами.
Поэтому в вершинах остался только вектор весов для выбранных материалов, а вот индексы ушли в per primitive buffer (StructuredBuffer<>), доступ к которому совершается в шейдере с помощью unity_InstanceID идентификатора.

На скриншоте выше видно, что данные в каждом треугольнике уникальные, а наборы материалов (их индексов) не отсортированы. На самом деле, сортировать их необязательно, но, чтобы переиспользовать часть данных, например текстурные массивы, при совпадении набора материалов, лучше отсортировать.

На основе этого буфера я также собираю per material данные: текстурные массивы, буфер настроек для каждого материала (ambient occlusion strength, smoothness strength, metallic strength и т.п.).
Пост о текстурных массивах и с какой проблемой я столкнулась находится вот тут.
Остается применить различные шейдинг-техники, смешивание по высоте например, стохастику для того, чтобы убрать паттерн тайлинга.

