Сегментация руки с нуля: рассказывает менеджер по работе с разметчиками
November 05, 2020Я менеджер по работе с разметчиками в LabelMe. Наша команда периодически сталкивается с довольно интересными вызовами, о которых мне хочется рассказать. Уверен, многие начинающие дата-сайентисты найдут эту информацию полезной.
Приступим. Для нашего дела весьма распространены задачи по Computer Vision - Semantic segmentation. Зачастую заказчик предоставляет оригиналы изображений, которые нужно сегментировать, но сбор данных для обучения машины, как правило, самостоятельный.
Задача: разметить руки.
Окей. Значит ищем изображения.
На помощь приходит Яндекс.Толока. При помощи этой краудсорс-платформы можно получить данные большого количества людей за короткий срок.
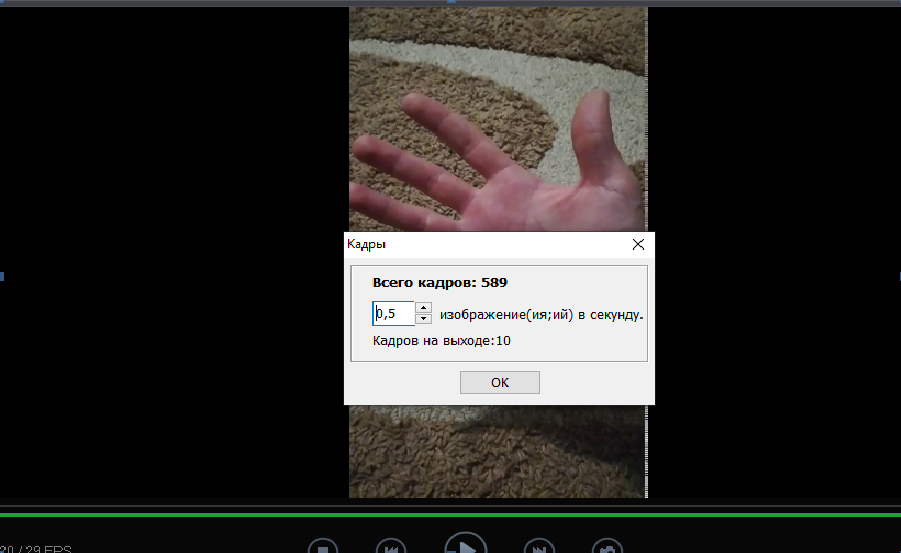
Создаем простое задание на 700 человек. За сутки нам будет представлено около 1400 видеороликов с руками.

После этого мы проводим кадрирование видео с определенной периодичностью: разбив частоту смены кадров из расчета 1 кадр на каждые 2 секунды, мы получим около 16 000 изображений со всех видео. Данный этап зависит от требуемого числа конечных масок.
Сегментация – это процесс разделения изображения на отдельные группы. Каждая из них соответствует одному объекту, одновременно определяя его тип в каждой области.
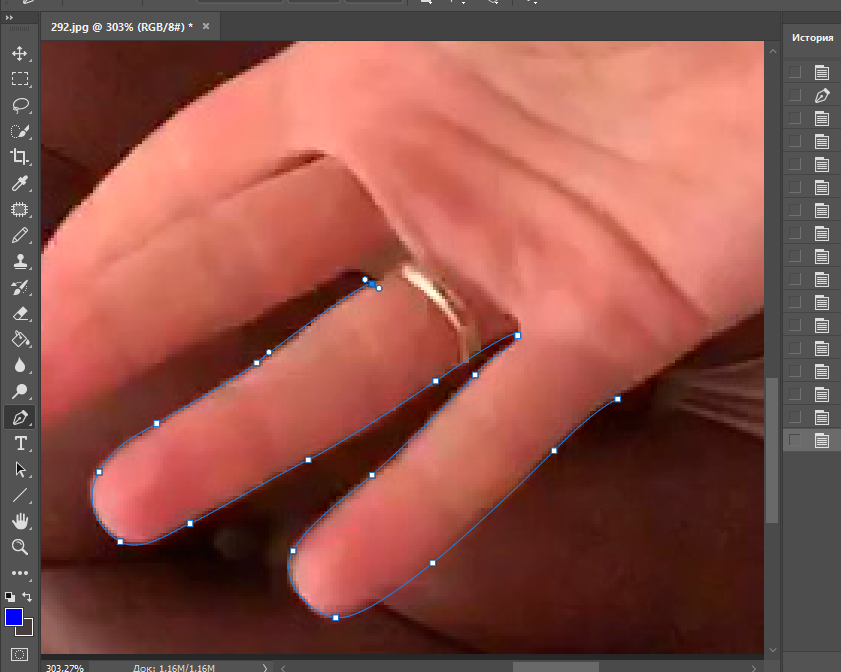
Давайте посмотрим на пример ниже:

В этом случае мы сегментировали руки и каждый палец отдельным классом.
Несмотря на существование большого списка инструментов для сегментирования, мы используем Adobe Photoshop, и вот почему:
1)Adobe Photoshop содержит в себе много тонкостей в настройке инструментов, позволяющих каждому разметчику настроить интерфейс под себя и выполнить разметку быстрее.
2)Если исполнитель-разметчик — человек со стороны и искать его планируется на фриланс-площадках, то будет довольно проблематично убедить его поставить сторонние программы, а потом еще объяснять как работать с этим инструментом.
Нужно внимательно контролировать как разметчики поняли задание: однородность данных является ключевым моментом в машинном обучении. Если один из разметчиков будет выделять пальцы до косточек, а остальные анатомически, моделька обучится некорректно.

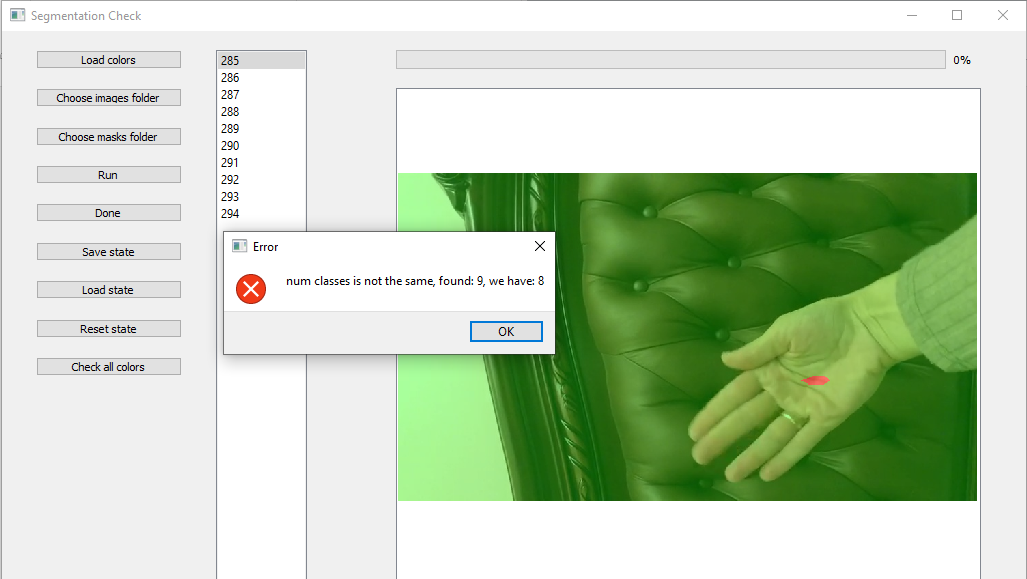
Кроме того, на масках могут оказаться пиксели не того цвета или вовсе лишних цветов. Это связано с стандартными настройками Adobe Photoshop. При заливке области программа сглаживает края заливки и происходит смешивание цветов. Такое случается если разметчик невнимательно прочитал инструкцию и забыл отключить сглаживание и ретушь при заливке. Или выставил не 100% значение непрозрачности.
На этот случай у нас есть скрипт, который проверяет цвета пикселей и мы программно проверяем каждую маску на наличие лишних цветов. Если возникает проблема, то возвращаем маску разметчику для исправлений.
Если лишних пикселей в масках не оказалось, тогда приступаем к проверке аккуратности при обводке контура.
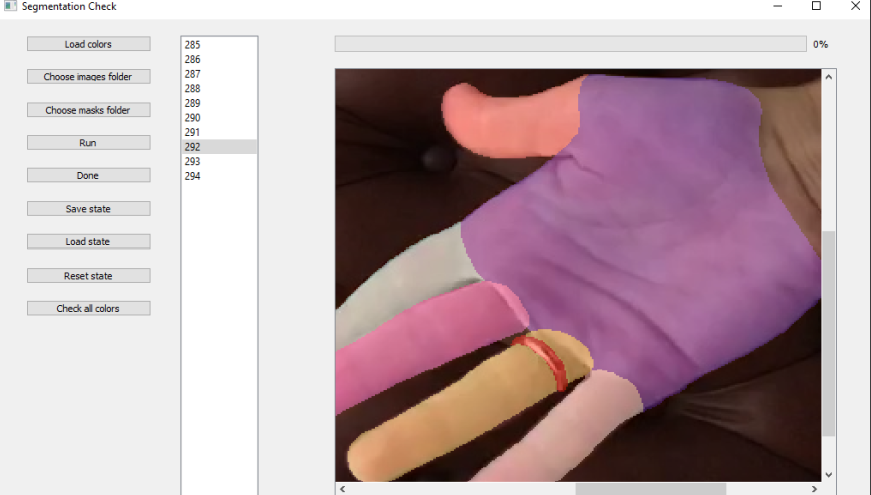
По завершении проверки следует убедиться, что каждой маске соответствует оригинал и название.

В примере выше видно, что двух масок не хватает. Доделаем их, проверим итоговый вариант и датасет готов.
Спасибо за внимание! В следующей статье напишу о том, как LabelMe собирали 100 000 изображений лиц со строгими критериями отбора.
Если остались вопросы — задавай их в комментариях. С радостью отвечу.