Scraping директорий на Python
wr3dmast3r|RAВсем привет! С вами wr3dmast3r, и сегодня мы напишем простой скрапер директорий сайта. Приступим.
Скрипт протестирован на версии Python 3.10.8

Импортируем нужные библиотеки:
import re import requests from typing import List, Set, Dct from urllib.parse import urljoin, urlparse from requests.exceptions import ConnectionError
Для работы скрипта нам понадобится несколько функций.
Первая функция будет основана на регулярном выражении которое позволяет получить массив всех ссылок на заданной странице:
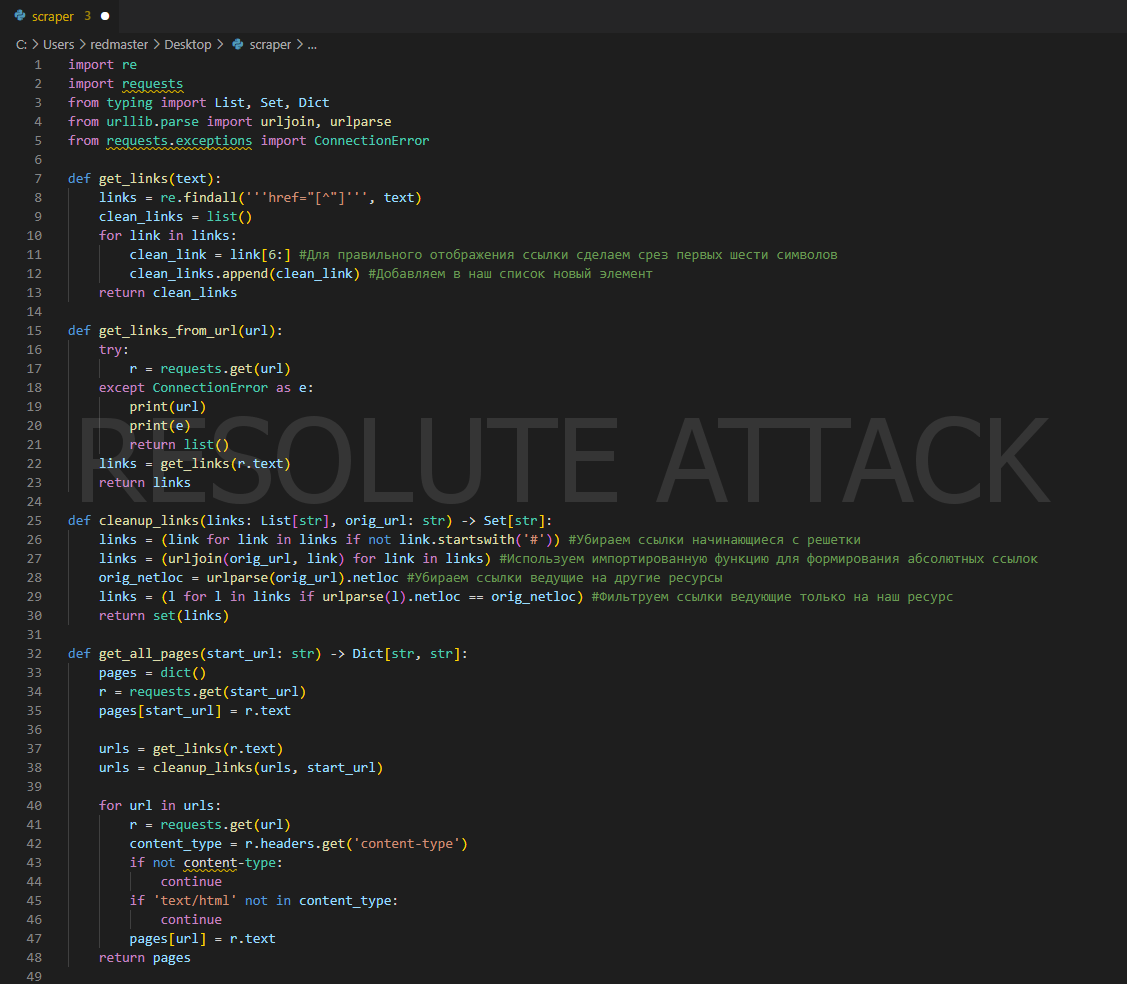
def get_links(text):
links = re.findall('''href="[^"]''', text)
clean_links = list()
for link in links:
clean_link = link[6:]
clean_links.append(clean_link)
return clean_links
Вторая функция проверяет доступность get-запроса на url и в случае доступности отправяет наш запрос:
def get_links_from_url(url):
try:
r = requests.get(url)
except ConnectionError as e:
print(url)
print(e)
return list()
links = get_links(r.text)
return links
Третья функция превращает полученные ссылки в коллекцию множества элементов:
def cleanup_links(links: List[str], orig_url: str) -> Set[str]:
links = (link for link in links if not link.startswith('#'))
links = (urljoin(orig_url, link) for link in links)
orig_netloc = urlparse(orig_url).netloc
links = (l for l in links if urlparse(l).netloc == orig_netloc)
return set(links)
Четвертая функция создает словарь из полученных ссылок для удобного отображения:
def get_all_pages(start_url: str) -> Dict[str, str]:
pages = dict()
r = requests.get(start_url)
pages[start_url] = r.text
urls = get_links(r.text)
urls = cleanup_links(urls, start_url)
for url in urls:
r = requests.get(url)
content_type = r.headers.get('content-type')
if not content-type:
continue
if 'text/html' not in content_type:
continue
pages[url] = r.text
return pages
В результате наш код выглядит примерно так:
Вызовем наши функции:
l = get_links_from_url('https://www.wildberries.ru/')
print(cleanup_links(l, 'https://www.wildberries.ru/'))
pages = get_all_pages('https://www.wildberries.ru/')
print(pages.keys())
Результат работы скрипта:
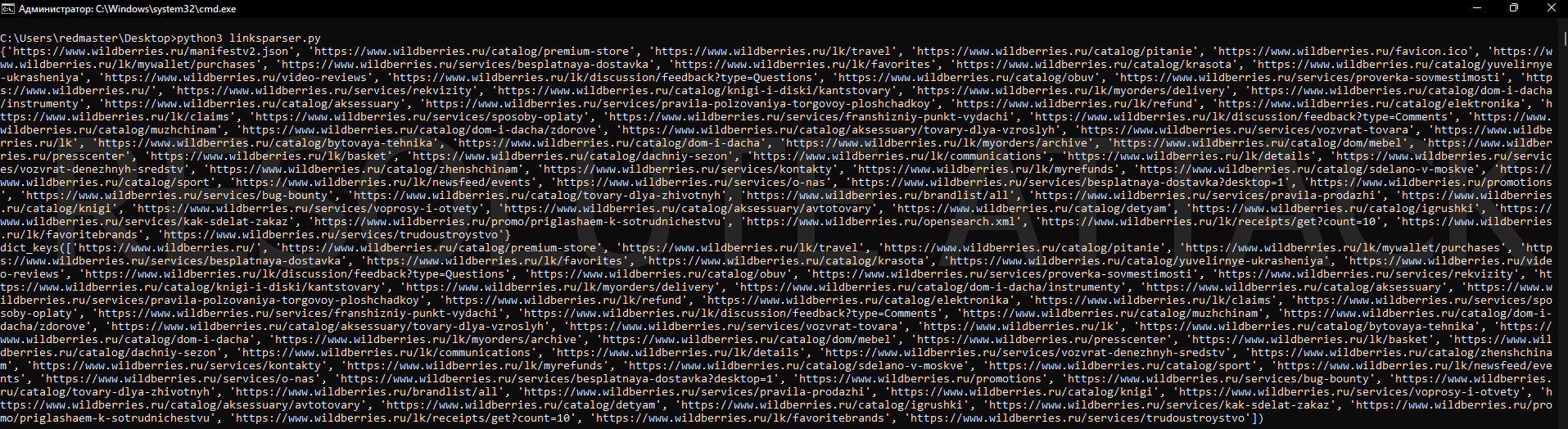
В итоге мы написали скрипт, который выдает нам все доступные на сайте страницы в удобном формате.
До новых встреч. C любовью от RESOLUTE ATTACK!