Как это было или сбор а-ля дампа SQL.RU
MurCode
Предыстория
Начнём с самого начала: с марта по июнь 2022 вместо какой-либо полезной информации по всем страницам сайта загружалась одинаковая заглушка "Проводятся технические работы бла-бла". Понятное дело, что "технические работы" это лишь формальное сокрытие реальной причины. Работы не могут тянуться месяцами и тем более администрация сайта не оповещать сообщество о новостях...
Как и многие другие энтузиасты, мы начали пробовать всем известное решение для получения информации. Используем сервис, который хранит архивные версии страниц различных сайтов https://web.archive.org
Вариант #1
Был найден такой вариант API для поиска нужных timestamp:
http://web.archive.org/cdx/search/cdx?url=sql.ru/forum/*&output=json&from=20220101&to=20220223
1) output=txt или json
2) from= yyyyMMddhhmmss. Можно указать только год, остальное опустить
3) &limit=999999. Задаём пределы
Позже был найден вариант получше. Можно сразу одним запросом утянуть огромный файл Json порядка 70 Мб со всеми timestamp. Далее необходимо было бы его проанализировать и вытащить нужные ссылки для скачивания и парсинга: http://web.archive.org/web/timemap/json?url=......
Было найдено примерно 600 тыс. ссылок форума. Сервис архиватора очень медленный. Работа предстояла адская, не говоря о том, что скачать такой объём информации было само по себе испытанием.
Но существовал ещё один способ...
Вариант #2
Смотрели различные страницы по теме форума, хотелось понять, что именно с ним случилось. И наткнулись на сайте 4PDA на любопытную APK "неофициальный клиент для форума SQL.RU". Я припоминал, что действительно такой клиент существовал и решил установить его. Вдруг там можно будет увидеть новости по сайту. Для работы требуется действительная учётная запись на форуме. После авторизации я увидел список форумов и самое интересное, список топиков и сообщения... Невероятно, но всё загружалось и работало!
Что же дальше
А давайте подглянем, как именно клиент получает доступ к сообщениям форума. Для этих целей использую NetCapture прямо с телефона.
Нам опять повезло, трафик идёт по протоколу HTTP, не HTTPS!

Расшифровка HTTPS трафика на последних версиях Android трудозатратна, т.к. есть проблемы с подменой сертификата и отключением SSL Pining не имея рута на устройстве. Google всячески "оберегает" пользователей и закрывает возможности, которые нужны разработчикам и исследователям
После того, как был собран сетевой дамп и изучен попробуем собрать тестовый стенд, сначала через HTTP отладчик
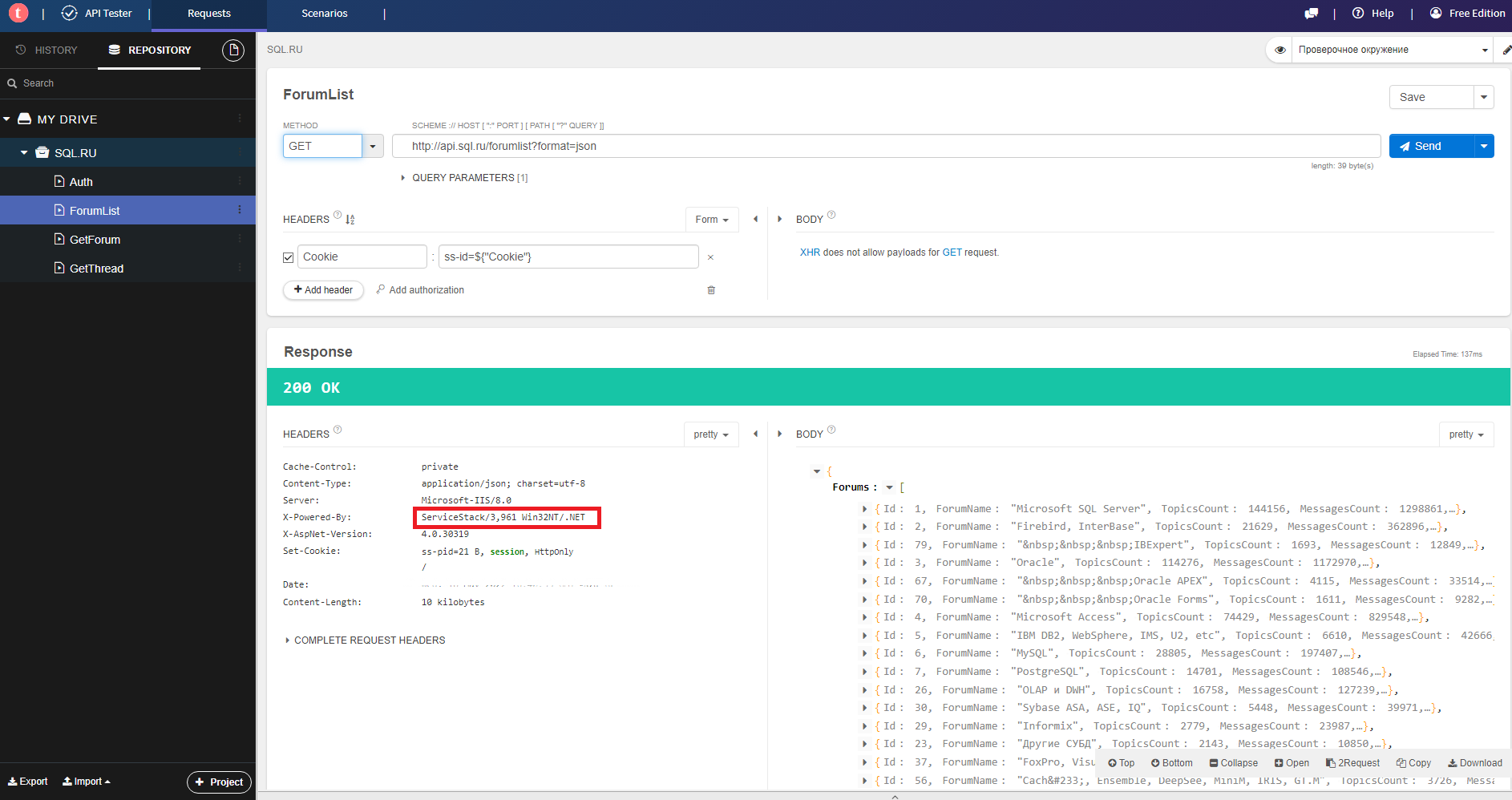
Было выявлено, что на сайте есть отдельная служба на базе ServiceStack, которая генерирует API для клиентов. После небольшого анализа увидим формат как формируется вызов методов:
Форматы: csv, xml, json
1) Авторизация:
http://api.sql.ru/auth?username=<Login>&password=<Password>&format=json
Cookie: ss-id=*****
2) Список форумов: http://api.sql.ru/forumlist?format=json
3) Список топиков из форума: http://api.sql.ru/forum/<ForumID>/<Page>?format=json
Page = 1..N
4) Список сообщений из топика: http://api.sql.ru/thread/<ThreadID>/<Page>?format=json
Page = 1..N
Давайте же всё скачаем. Пишем утилитку для многопоточной выгрузки данных. Один класс качает данные, маппим полученные json в классы и отдаём классу для записи в базу данных SQLite.
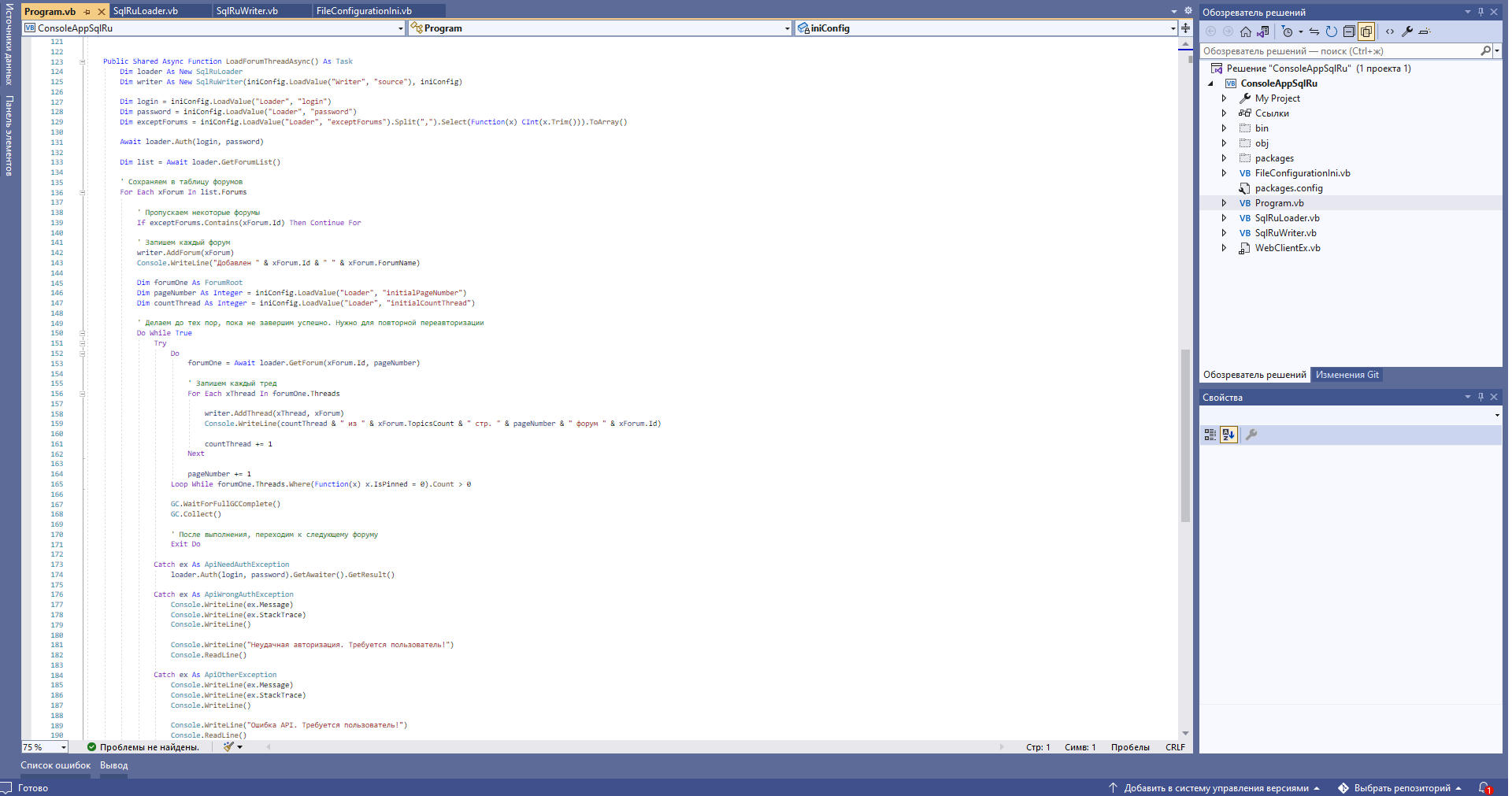
База данных SQLite выбрана по причине быстрого развёртывания и в итоге она осталась в качестве целевого решения. Поднастроены были опции синхронизации, чтобы выжать больше скорости. Журнал транзакций был переведен в WAL, чтобы несколько потоков могли почти без боли писать. Почему "почти"? Открытие новых транзакций шло постоянно, не прекращаясь и не давая "отдохнуть" базе данных. После каждых N тысяч записей производилась пауза на потоках, давая возможность сделать чекпоинт и перенести данные из WAL-файла в DB-файл.
Периодически авторизация отпадает и приходится делать перелогин, а рабочие потоки должны в это время ждать. Также не с первого раза всё было гладко записано, где-то необходимо было обогащать данные ключами. Данные из JSON 1 в 1 не могли быть сохранены в таблицы базы данных. Но после некоторых попыток данные с огромной скоростью полились в базу данных.
Сообщения за старые даты, к примеру за 2010 год и ранее читались из сервиса медленнее, чем за свежие даты. Скорее всего там или разные партиции с данными (разные диски для хранения), либо какие-то специфичные индексы, что старые данные тяжело выбираются.
На всё про всё ушло около 1,5 суток. Это время на выгрузку данных отлаженным загрузчиком до сохранения всего в базу данных
Что получилось
Файл базы данных весил: 8 Гб.
Всего сохранили: 52 форума, 858 839 тем, 8 138 283 сообщений
Форум "ПТ" не загрузили, т.к. пользователю под которым проводилась работа он не доступен. Выполнили чистку данных, частично перенастроили внутренние ссылки на топики так, чтобы они были доступны внутри домена MurCode. Добавлены индексы и построен FTS индекс по темам, авторам и текстам сообщений.
На текущий момент файл базы данных вырос до 12 Гб. Поиск выполняется на некоторых кейсах очень медленно, но при повторном запросе данные читаются практически мгновенно. Скорее всего дело в кеше самого SQLite, этот вопрос пока для меня открытый. Опыта по SQLite пока не хватает, чтобы обойти эту проблему.
Дамп ли это
Нет, это несовсем дамп. Во первых, таблицы с пользователями как таковой не существует, она искуственно была воссоздана в проекте. Авторизацию по ней нельзя сделать. Поэтому старые сообщения будут лежать как "знания" для поколенний, а новые пользователи смогут уже управлять своими сообщениями.
Во-вторых, сообщения с решениями содержат кусочки кода с подсветкой синтаксиса в виде готовой HTML-вёрстки. Это уже отрендеренные данные для отправки в браузер. В сообщениях не содержатся так называемые BBCode, поэтому сделать, например, какую-то иную подсветку синтаксиса или исправить размер шрифтов невозможно, это касается и других элементов: цитаты, таблицы, курсивы и т.д.
Для цитат в качестве обходного решения через CSS селекторы изменена цветовая палитра и шрифты очень грубо. Для нормального решения, надо сделать зачистку HTML вёрстки и сгенерировать BB коды, но на это не хватит наших ресурсов. Для новых сообщений конечно будет сохранятся всё с кодами и рендериться/кешироваться в момент запроса страницы топика.
Из всего это следует, что залить эту выгрузку в некий готовый движок форума теоретически можно, но нужно провести ещё большой анализ. А пока...
Резюме
Сейчас форум создан полностью на самописном решении VB.NET + ASP.NET + IIS 8.5. Это даёт преимущества: форум на текущий момент был поднят достаточно быстро и выполняет свою задачу, даёт пользователю найти решения. Есть немало и недостатков: добавление авторизации, системы модерации, рендеринга сообщений с использование bb-кодов и прочий форумный функционал надо писать руками и на это требуется очень много времени, которого у нас нет...
Видется такой путь развития: сайт подготовлен для обработки поисковыми движками, автоматически генерируются кодом SiteMaps, SEO, OpenGraph и прочие необходимые теги для индексации. Пока будут топики индексироваться, люди возможно начнут интересоваться форумом и к тому моменту будет большое количество желающих общаться на форуме. Сейчас желающих мало и не хочется делать функционал форума, который будет не востребован и потратить время почти в пустую...
Возможно у кого-то появится иное видение проекта или захочет нам помочь? Буду рад выслушать ваши идеи и пожелания. Спасибо, кто осилил много буков и дочитал до конца :)