SWARM parallelism
Представим, что мы хотим учить большие модели, а покупать себе кластер дорого и очень не хочется. Но мы можем позволить себе снять спотовых виртуалок на Vast.ai или AWS. К сожалению, они ненадежные, расположены в разных концах света и могут иметь обычные gpu на борту без (A,H)100.
Авторы предлагают использовать свой новый подход для обучения больших моделей в нестабильной среде — SWARM parallelism (Stochatistically Wired Adaptively Rebalanced Model parallelism).
Традиционный model parallelism подразумевает под собой выполнение подмножества слоев большой модели (а иногда подмножества нейронов слоя большой модели) на отдельных gpu. Понятно, что из этого вытекает другая проблема — большой объем обмена данными между устройствами, так что чаще всего он используется в гомогенных суперлокальных кластерах GPU. Но опять же, что если такого нет? Именно эту проблему пытаются решить авторы статьи с помощью нового подхода.
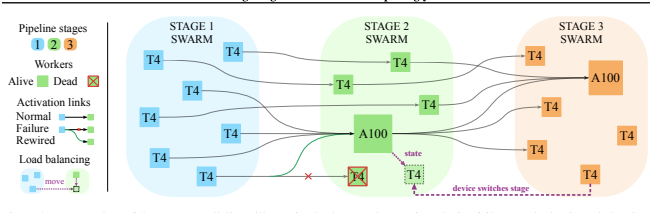
Ключевое понятие всего подхода — рой. Это такая логическая группа машин с видеокартами, которые обслуживают определенную часть модели. Допустим, мы учим GPT-3, которая состоит из довольно похожих слоев, что идет нам на пользу — мы можем разделить модель на несколько частей, регулируя размеры и ожидаемое потребление памяти GPU.
Каждому рою назначим свою часть модели. Он будет получать данные из предшествующего роя, считать активации и передавать их следующему рою. У каждого участника роя есть две очереди — одна для входных данных, другая для посчитанных им активаций. Первая очередь необходима для того, чтобы продолжать получать данные от роя-предшественника, даже если видеокарта занята, и поддерживать стабильную утилизацию. Вторая нужна для того, чтобы не терять данные при фейлах последующих роев и балансировать нагрузку.
Если участник роя падает, то его "коллеги" могут данные принять и обработать. За счет того, что рои относительно большие, такие падения не влияют на надежность системы в целом.
А как тогда обновлять веса модели и считать градиенты?
Делаем All Reduce в каждом рое отдельно после батча, предварительно получив градиенты от соседнего роя.
Каждый участник роя держит очереди для входящих и исходящих запросов, чтобы поддерживать утилизацию на высоком уровне.
Ключевые фишки подхода:
- Stochastic Wiring:
Собственно, каждая нода роя знает всех своих "коллег" за счет поддержания актуальной таблицы участников с помощью DHT (Distributed Hash Table). А еще на каждой ноде крутится процесс, который считает скорость обработки запросов и сравнивает ее с другими участниками. Таким образом, она может балансировать нагрузку и отправлять запросы на самые быстрые машины. Похожим образом работают современные продвинутые балансировщики нагрузки с использованием Interleaved Weighted Round Robin механизма. Если в обычном Round Robin мы просто ходим по кругу по всем доступным машинам, то в IWRR мы, дополнительно, учитываем вес (скорость обработки) и загруженность машины. - Adaptive swarm rebalancing:
Каждые T секунд отдельный процесс оценивает загруженность роев по размеру очередей для входящих запросов. Так мы можем понять, какой из роев перегружен, а какой — наоборот простаивает. Ну и дальше наименее загруженный участник из простаивающего роя может спокойно переключиться в загруженный, просто попросив свежие веса у участников этого роя.
Конечно же, надо с чем-нибудь сравниться, чтобы оценить плюсы.
Сравнивали с:
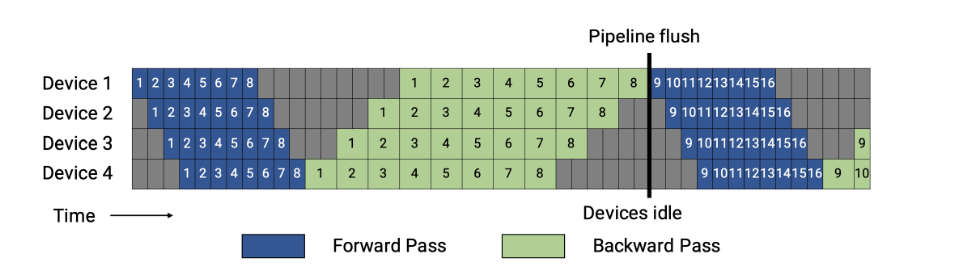
- Gpipe — распил батча на микробатчи + распил модели на несколько gpu. Ждем пока все микробатчи пройдут по кругу gpu, только потом делаем backward pass;
- 1F1B — Gpipe с хитрым хаком в виде backward pass по микробатчу, сразу после успешного прохождения им круга (картинка сравнения работы будет ниже);
- Zero-Offload — просто выгружаем иногда в RAM оптимизатор или даже саму модель, чтобы посчитать со спокойной душой и с бОльшей памятью градиенты.

Сетапили эксперимент просто — взяли GPT-3 like слои и одинаковые машины.
Замеряли две самые главные метрики — training throughput (насколько быcтро обрабатывается батч) и время, затраченное на All-reduce. Также протестировали подходы в разных условиях — с добавленной задержкой между серверами и без (RTT+100ms, что по сути почти разные континенты, но иногда это соседние дата-центры, просто сетевики не справились с настройкой).
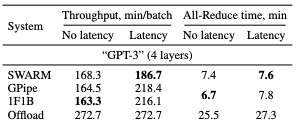
Вкратце по выводам:
- SWARM выгоден для моделей от 1 миллиарда параметров (Square-Cube Law);
- Аутперформит GPipe и Offload по скорости работы в нестабильной среде;
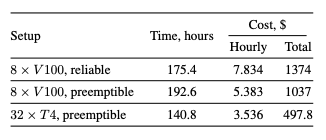
- Может быть быстрее/дешевле, чем обычный DDP/FSDP/Zero/подставьте свое. Авторы обучили Albert-Large на WikiText, DDP на 8 V100 против SWARM 32 T4. Результаты представлены ниже, почти в 3 раза дешевле с точки зрения расходов на облако!
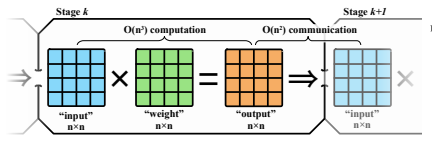
Коротко про Square-Cube Law — обучение бОльших моделей может потреблять меньше сети. Потому что произведение двух матриц размера nxn стоит нам примерно O(n^3) операций, а передача данных по сети — O(n^2) операций (отсюда и отсылка к Square-Cube Law). То есть, если вы учите реально большие модели, то передача данных перестает быть для вас проблемой.