SQL-запросы, которые вы рано или поздно погуглите
https://t.me/sqlhub
Разобрали на примерах самые популярные SQL-запросы, связанные с модификацией таблиц, изменением записей и условиями,
В этой статье отвечу на вопросы, которые возникают у новичков в SQL, в частности в PostgreSQL и BigQuery. Мы не будем обсуждать совсем базовые SELECT, CREATE или DROP.
Для удобства восприятия будем использовать тестовые данные. Первая таблица players содержит данные о пользователях и дате установки мобильной игры:
|playerId|name |installationDate|game |os | |--------|----------------|----------------|----------|----------| |9e8a0174|Трофимова Алёна |2023-07-30 |basketball|iOS 16 | |3e2e04ad|Семенова Алиса |2022-07-21 |consumer |iOS 13 | |642eafb2|Абрамова Диана |2022-06-06 |curtain |iOS 15 | |8c231f49|Ефимова Ульяна |2022-06-21 |conductor |Android 12| |a085caf1|Захаров Михаил |2023-04-11 |appear |Android 11| |c4deb869|Николаева Марта |2022-03-31 |possible |iOS 11 |
вторая, levels, — даты прохождения игроком с определенным ID того или иного уровня:
|playerId|level|completionDate| |--------|-----|--------------| |7b50274d|6 |2023-05-17 | |b0c9a9da|20 |2022-02-19 | |09b3d5b5|15 |2022-07-22 | |52b3bfa9|11 |2022-02-18 | |3e2e04ad|17 |2022-08-17 | |642eafb2|17 |2022-04-14 | |8c231f49|20 |2022-05-30 | |a085caf1|20 |2023-02-24 | |36545ec1|16 |2022-08-10 | |44e9653f|3 |2023-06-02 |
Я буду верстать в BigQuery на таком же датасете, так что использую соответствующий диалект.
Разница между INNER JOIN и OUTER JOIN
Допустим, геймдев-студия хочет объединить эти две таблицы, чтобы в дальнейшем вычислить глубину прохождения. Как вы уже догадались, такую операцию можно провести только по столбцу playerId (идентификатор игрока). Давайте вспомним, какие виды слияния существуют:

INNER JOIN
Это тип объединения по умолчанию, и он оставит наименьшее число строк. Слово INNER можно опустить:
SELECT p.playerId, installationDate, game, level, completionDate FROM `project.tutorials.players` AS p JOIN `project.tutorials.levels` AS l ON p.playerId = l.playerId;
Посмотрим, что здесь происходит:
- В строках 1-6 мы выбираем только необходимые столбцы;
- 7-8: командой AS задаем псевдонимы таблицам;
- 8: определяем логику объединения по совпадающим playerId. Это означает также, что мы сохраним данные только об первом попавшемся уровне.
Получим всего четыре строки:
|playerId|name |installationDate|game |level|completionDate| |--------|--------------|----------------|---------|-----|--------------| |3e2e04ad|Семенова Алиса|2022-07-21 |consumer |17 |2022-08-17 | |642eafb2|Абрамова Диана|2022-06-06 |curtain |17 |2022-04-14 | |8c231f49|Ефимова Ульяна|2022-06-21 |conductor|20 |2022-05-30 | |a085caf1|Захаров Михаил|2023-04-11 |appear |20 |2023-02-24 |
OUTER JOIN
Этот тип объединения, напротив, куда «добрее» и в случае FULL-объединения сохранит записи обо всех игроках и всех пройденных уровнях:
SELECT p.playerId, installationDate, game, level, completionDate FROM `project.tutorials.players` AS p FULL OUTER JOIN `project.tutorials.levels` AS l ON p.playerId = l.playerId;
У нас появятся записи, где playerId пуст, поскольку попросили мы идентификаторы только из первой таблицы:
|playerId|installationDate |game |level |completionDate| |--------|----------------------------|----------|---------|--------------| | | | |6 |2023-05-17 | |642eafb2|2022-06-06 |curtain |17 |2022-04-14 | | | | |11 |2022-02-18 | | | | |20 |2022-02-19 | | | | |16 |2022-08-10 | |c4deb869|2022-03-31 |possible | | | |8c231f49|2022-06-21 |conductor |20 |2022-05-30 | | | | |15 |2022-07-22 | |a085caf1|2023-04-11 |appear |20 |2023-02-24 | |3e2e04ad|2022-07-21 |consumer |17 |2022-08-17 | |9e8a0174|2023-07-30 |basketball| | | | | | |3 |2023-06-02 |
ВРЕЗКА. В моей практике LEFT / RIGHT-джойны пригождаются реже, но все равно порой бывает полезно получить такую выборку. К примеру, это поможет впоследствии вычислить тех, кто вообще дошел до конца игры.
Как обновить запись?
Если, скажем, в данные закралась ошибка, мы можем изменить одну или несколько строк таким образом:
UPDATE `project.tutorials.players` SET installationDate = '2023-08-23'WHERE game = 'curtain'
Запрос выбирает все, где game равен ‘curtain’, и задает там новую дату установки – 23 августа 2023 г.
Теперь players выглядит так:
|playerId|name |installationDate|game |os |device| |--------|---------------|----------------|----------|----------|------| |3e2e04ad|Семенова Алиса |2022-07-21 |consumer |iOS 13 | | |9e8a0174|Трофимова Алёна|2023-07-30 |basketball|iOS 16 | | |a085caf1|Захаров Михаил |2023-04-11 |appear |Android 11| | |8c231f49|Ефимова Ульяна |2022-06-21 |conductor |Android 12| | |c4deb869|Николаева Марта|2022-03-31 |possible |iOS 11 | | |642eafb2|Абрамова Диана |2023-08-23 |curtain |iOS 15 | |
Как добавить столбец?
У нас были playerId, name, installationDate, game, os, а теперь аналитики студии добавляют модель устройства, чтобы изучить его влияние на проходимость:
ALTER TABLE `project.tutorials.players` ADD COLUMN device STRING
Запрос добавляет столбец, в который может поместиться название устройства (iPhone, Samsung и проч.):
|playerId|name |installationDate|game |os |device| |--------|----------------------------|----------------|----------|----------|------| |9e8a0174|Трофимова Алёна Львовна |2023-07-30 |basketball|iOS 16 | | |3e2e04ad|Семенова Алиса Николаевна |2022-07-21 |consumer |iOS 13 | | |642eafb2|Абрамова Диана Никитична |2022-06-06 |curtain |iOS 15 | | |8c231f49|Ефимова Ульяна Давидовна |2022-06-21 |conductor |Android 12| | |a085caf1|Захаров Михаил Александрович|2023-04-11 |appear |Android 11| | |c4deb869|Николаева Марта Гордеевна |2022-03-31 |possible |iOS 11 | |
ВРЕЗКА. Когда такие вопросы становятся самыми популярными на Stack Overflow, понимаешь, что у SQL документация менее удобочитаема, чем тред на форуме.
Как удалить дубликаты?
Команда разработчиков хочет подчистить данные об игроках и выберет только уникальных. Удивительно, как часто возникает такая потребность, и как «костыляет» ее решение в BigQuery:
SELECT DISTINCT * FROM `project.tutorials.players`
Здесь мы просто выделили уникальные (distinct) записи, но как удалить дубликаты? Мы создаём новую таблицу: жмем кнопку Save Results / BigQuery Table:
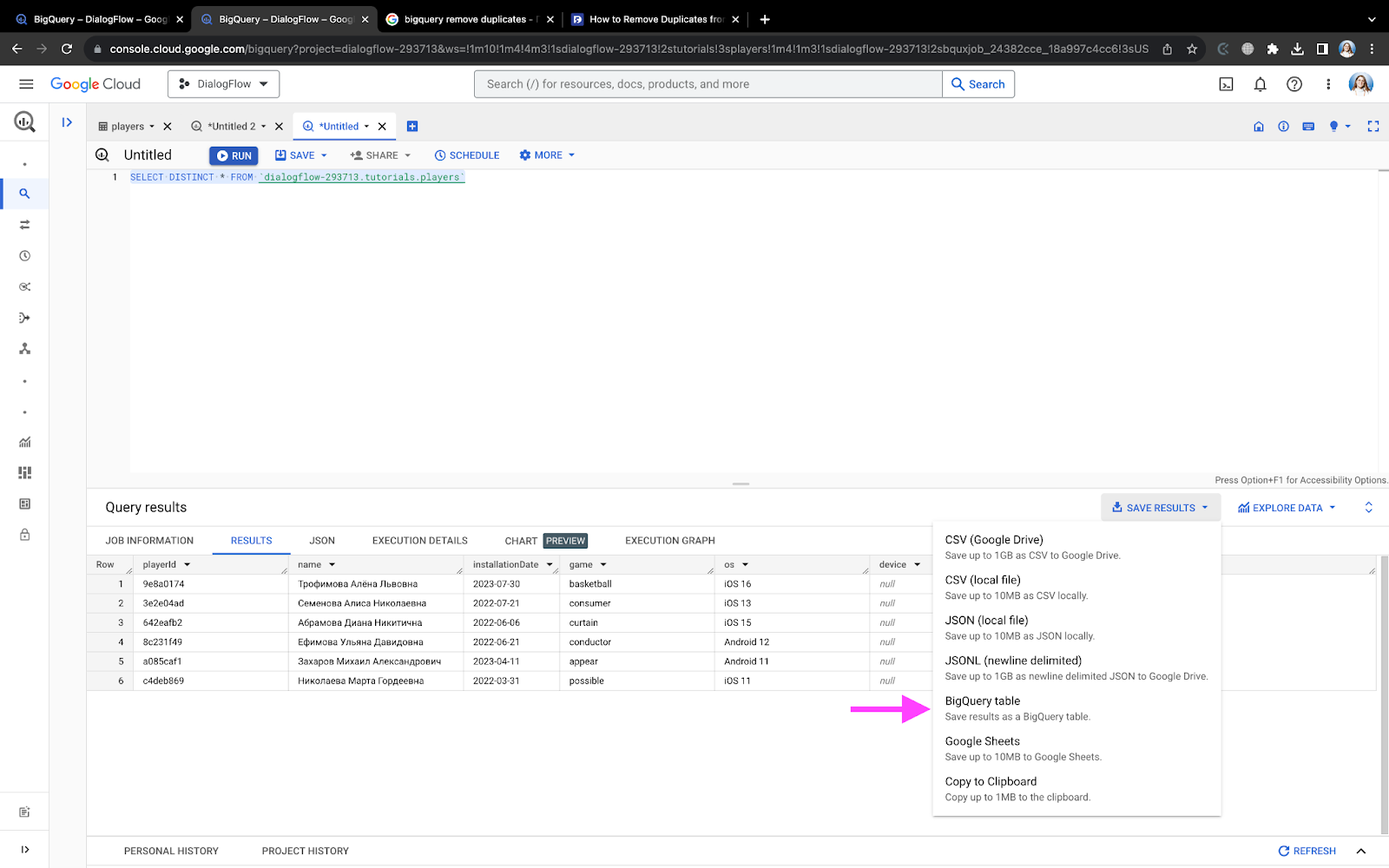
Вставка нескольких записей одновременно
C этой командой многие разработчики знакомятся в ходе обучения. Но вопрос: «Как добавить несколько записей?» — все равно остается популярным.
INSERT INTO players
(playerId, name, installationDate, game)
VALUES
('0e95168a', 'Алексеев Максим Артёмович', 2022-01-21, 'brief'),
('0e951a86', 'Петров Михаил Сергеевич', 2022-12-08, 'applaud'),
('0e951d7e', 'Мартынов Даниил Алексеевич', 2022-10-15, 'rocket'),
('0e95206c', 'Фадеева Тамара Тимуровна', 2022-05-08, 'glorious');
В коде выше мы указываем порядок столбцов, согласно которому будут вноситься новые строки – от идентификатора пользователя (playerId) до названия игры (game). Затем перечисляем новые записи в нужном порядке: ‘0e95168a’, ‘Алексеев Максим Артёмович’, 2022-01-21, ‘brief’.
Если уж приходится вставлять ряды таким способом, можно воспользоваться онлайн-генератором SQL вроде filldb.info. Этот сервис позволяет не только сгенерировать игрушечные данные с тонкими настройками, но и связать таблицы между собой.
Условия
Создатели SQL Рэймонд Бойс и Дональд Чемберлин добавили условные ветвления в язык. И вышло нетривиально. Если аналитик хочет изучить бестселлеры ‘basketball’ и ‘curtain’, то выделить записи, касающиеся только этих игр, можно с помощью CASE-выражения:
123456789SELECT CAST(
CASE
WHEN game = 'basketball'
THEN1WHEN game = 'curtain'THEN1 ELSE 0
ENDASINT) AS isPopularGame, playerIdFROM `project.tutorials.players`
Давайте изучим построчно, что здесь происходит:
- В строке 8 определим тип нового столбца (INT) и назовем его isPopularGame;
- 3-6: потребуем выставлять значение 1 для двух популярных игр;
- 7: выставим ноль для всех остальных игр;
- 2: мы используем CAST … AS INT, чтобы единицы и ноли, что мы присваиваем новому столбцу, стали целочисленным столбцом
Мы получим такой лаконичный ответ:
|isPopularGame|playerId| |-------------|--------| |1 |9e8a0174| |0 |3e2e04ad| |1 |642eafb2| |0 |8c231f49| |0 |a085caf1| |0 |c4deb869|
Кстати, в BI-системах вроде Tableau или Google Looker CASE-выражение играет важную роль: с его помощью создаются временные вычисляемые столбцы, которые нужны только на одном дашборде без затрат на хранение данных. К примеру, в том же Looker мы можем создать такой для группировки по типу операционной системы (iOS / Android):
CASE
WHEN REGEXP_CONTAINS('iOS') THEN 'iOS'
WHEN REGEXP_CONTAINS('Android') THEN 'Android'
ELSE 'Нет данных'
END
Оператор IF – ELSE
Если-выражени тоже реализованы, но используются в конструкциях попроще. Допустим, аналитик проекта хочет выделить из общего массива игроков тех, что пришли недавно:
SELECT playerId, name, IF(installationDate < '2023-01-01', 'true', 'false') AS recentInstallation FROM `project.tutorials.players`
Мы получим дополненные столбцом recentInstallation данные:
|playerId|name |recentInstallation| |--------|---------------|------------------| |9e8a0174|Трофимова Алёна|false | |3e2e04ad|Семенова Алиса |false | |642eafb2|Абрамова Диана |true | |8c231f49|Ефимова Ульяна |true | |a085caf1|Захаров Михаил |false | |c4deb869|Николаева Марта|true |
Запрос сработает, только если столбец installationDate типа TIMESTAMP (‘2023-04-12 01:12:22’). Для сравнения дат, выраженных целым числом (20230412), строкой (‘2023-04-12’) используется CAST.