SQL для начинающих: 10 правил построения «точных» запросов
https://t.me/ai_machinelearning_big_data
«Точный» SQL-запрос возвращает «чистые» данные в необходимом и достаточном количестве, при этом потребляет как можно меньше памяти и справляется за минимальное время. Скорость работы с базой влияет на производительность. Потребление памяти может негативно сказаться даже на безопасности. Всё это прямо и косвенно влияет на прибыль компании. В статье разберёмся, как не допускать ошибок.
Для наших целей понадобятся тестовые данные. Будем работать с базой данных Oracle Database. Примеры в статье будут приводиться на языке SQL, PL/SQL. Нам важен подход, который можно адаптировать под другую реляционную систему управления базами данных — РСУБД.
Тестовые данные
⚒ Создадим тестовую таблицу 1:
CREATE SEQUENCE TEST_DATA_1_SEQ
NOMAXVALUE
NOMINVALUE
NOCYCLE
/
CREATE TABLE TEST_DATA_1
(
TEST_DATA_1_ID NUMBER DEFAULT TEST_DATA_1_SEQ.NEXTVAL NOT NULL
,TYPE VARCHAR2(64) NOT NULL
,VALUE VARCHAR2(128) NOT NULL
,PC_USR VARCHAR2(30) DEFAULT USER NOT NULL
,PC_DT TIMESTAMP(6) DEFAULT SYSTIMESTAMP NOT NULL
)
/
ALTER TABLE TEST_DATA_1
ADD CONSTRAINT TEST_DATA_1_PK PRIMARY KEY (TEST_DATA_1_ID)
USING INDEX
/
ALTER TABLE TEST_DATA_1
ADD CONSTRAINT TEST_DATA_1_TYPE_CHK CHECK (TYPE in ('CITY', 'DATE', 'EMPLOYEE', 'STOCK MARKET'))
/
CREATE UNIQUE INDEX TEST_DATA_1_UIDX1 ON TEST_DATA_1 (VALUE)
/
COMMENT ON TABLE TEST_DATA_1 IS 'Тестовые данные 1'
/
⚒ Заполним тестовую таблицу 1 данными:
/* Добавление данных */
INSERT INTO TEST_DATA_1 (TYPE, VALUE) VALUES ('CITY', 'МОСКВА');
INSERT INTO TEST_DATA_1 (TYPE, VALUE) VALUES ('CITY', 'САНКТ-ПЕТЕРБУРГ');
INSERT INTO TEST_DATA_1 (TYPE, VALUE) VALUES ('EMPLOYEE', 'СОТРУДНИК 1. ПОЛ М. ВОЗРАСТ 18');
INSERT INTO TEST_DATA_1 (TYPE, VALUE) VALUES ('EMPLOYEE', 'СОТРУДНИК 2. ПОЛ Ж. ВОЗРАСТ 19');
INSERT INTO TEST_DATA_1 (TYPE, VALUE) VALUES ('EMPLOYEE', 'СОТРУДНИК 3. ПОЛ Ж. ВОЗРАСТ 20');
INSERT INTO TEST_DATA_1 (TYPE, VALUE) VALUES ('DATE', '01 января 2000');
INSERT INTO TEST_DATA_1 (TYPE, VALUE) VALUES ('DATE', '02 января 2000');
INSERT INTO TEST_DATA_1 (TYPE, VALUE) VALUES ('DATE', '01.01.2001');
INSERT INTO TEST_DATA_1 (TYPE, VALUE) VALUES ('DATE', '02.01.2001');
INSERT INTO TEST_DATA_1 (TYPE, VALUE) VALUES ('DATE', '03.01.2001');
INSERT INTO TEST_DATA_1 (TYPE, VALUE) VALUES ('DATE', '04.01.2001');
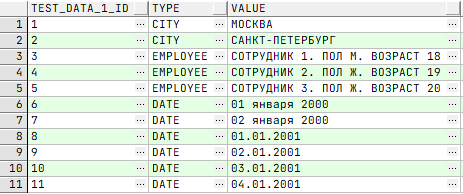
/* Извлечение всех данных */
SELECT t1.*
FROM TEST_DATA_1 t1;
/* Удаление всех данных без проверок */ TRUNCATE TABLE TEST_DATA_1;
⚒ Создадим тестовую таблицу 2:
CREATE SEQUENCE TEST_DATA_2_SEQ
NOMAXVALUE
NOMINVALUE
NOCYCLE
/
CREATE TABLE TEST_DATA_2
(
TEST_DATA_2_ID NUMBER DEFAULT TEST_DATA_2_SEQ.NEXTVAL NOT NULL
,TEST_DATA_1_ID NUMBER NOT NULL
,TYPE VARCHAR2(64) NOT NULL
,VALUE VARCHAR2(128) NOT NULL
,PC_USR VARCHAR2(30) DEFAULT USER NOT NULL
,PC_DT TIMESTAMP(6) DEFAULT SYSTIMESTAMP NOT NULL
)
/
ALTER TABLE TEST_DATA_2
ADD CONSTRAINT TEST_DATA_2_PK PRIMARY KEY (TEST_DATA_2_ID)
USING INDEX
/
ALTER TABLE TEST_DATA_2
ADD CONSTRAINT TEST_DATA_2_TYPE_CHK CHECK (TYPE in ('STREET', 'DATE', 'EMPLOYEE', 'STOCK MARKET'))
/
CREATE UNIQUE INDEX TEST_DATA_2_UIDX1 ON TEST_DATA_2 (TEST_DATA_1_ID, VALUE)
/
COMMENT ON TABLE TEST_DATA_2 IS 'Тестовые данные 2'
/
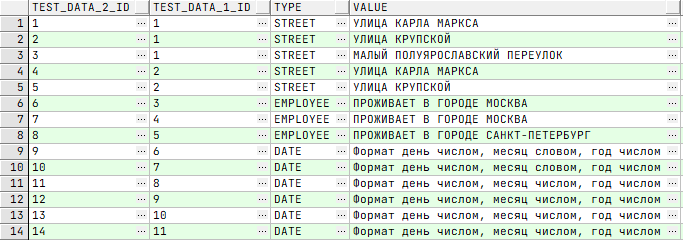
⚒ Заполним тестовую таблицу 2 данными:
/* Добавление данных */ INSERT INTO TEST_DATA_2 (TEST_DATA_1_ID, TYPE, VALUE) VALUES (1 /*ID МОСКВА*/, 'STREET', 'УЛИЦА КАРЛА МАРКСА'); INSERT INTO TEST_DATA_2 (TEST_DATA_1_ID, TYPE, VALUE) VALUES (1 /*ID МОСКВА*/, 'STREET', 'УЛИЦА КРУПСКОЙ'); INSERT INTO TEST_DATA_2 (TEST_DATA_1_ID, TYPE, VALUE) VALUES (1 /*ID МОСКВА*/, 'STREET', 'МАЛЫЙ ПОЛУЯРОСЛАВСКИЙ ПЕРЕУЛОК'); INSERT INTO TEST_DATA_2 (TEST_DATA_1_ID, TYPE, VALUE) VALUES (2 /*ID САНКТ-ПЕТЕРБУРГ*/, 'STREET', 'УЛИЦА КАРЛА МАРКСА'); INSERT INTO TEST_DATA_2 (TEST_DATA_1_ID, TYPE, VALUE) VALUES (2 /*ID САНКТ-ПЕТЕРБУРГ*/, 'STREET', 'УЛИЦА КРУПСКОЙ'); INSERT INTO TEST_DATA_2 (TEST_DATA_1_ID, TYPE, VALUE) VALUES (3 /*ID СОТРУДНИК 1*/, 'EMPLOYEE', 'ПРОЖИВАЕТ В ГОРОДЕ МОСКВА'); INSERT INTO TEST_DATA_2 (TEST_DATA_1_ID, TYPE, VALUE) VALUES (4 /*ID СОТРУДНИК 2*/,'EMPLOYEE', 'ПРОЖИВАЕТ В ГОРОДЕ МОСКВА'); INSERT INTO TEST_DATA_2 (TEST_DATA_1_ID, TYPE, VALUE) VALUES (5 /*ID СОТРУДНИК 3*/,'EMPLOYEE', 'ПРОЖИВАЕТ В ГОРОДЕ САНКТ-ПЕТЕРБУРГ'); INSERT INTO TEST_DATA_2 (TEST_DATA_1_ID, TYPE, VALUE) VALUES (6 /*ID 01 января 2000*/, 'DATE', 'Формат день числом, месяц словом, год числом'); INSERT INTO TEST_DATA_2 (TEST_DATA_1_ID, TYPE, VALUE) VALUES (7 /*ID 02 января 2000*/, 'DATE', 'Формат день числом, месяц словом, год числом'); INSERT INTO TEST_DATA_2 (TEST_DATA_1_ID, TYPE, VALUE) VALUES (8 /*ID 01.01.2001*/, 'DATE', 'Формат день числом, месяц числом, год числом'); INSERT INTO TEST_DATA_2 (TEST_DATA_1_ID, TYPE, VALUE) VALUES (9 /*ID 02.01.2001*/, 'DATE', 'Формат день числом, месяц числом, год числом'); INSERT INTO TEST_DATA_2 (TEST_DATA_1_ID, TYPE, VALUE) VALUES (10 /*ID 03.01.2001*/, 'DATE', 'Формат день числом, месяц числом, год числом'); INSERT INTO TEST_DATA_2 (TEST_DATA_1_ID, TYPE, VALUE) VALUES (11 /*ID 04.01.2001*/, 'DATE', 'Формат день числом, месяц числом, год числом'); /* Извлечение всех данных */ SELECT t2.* FROM TEST_DATA_2 t2;
/* Удаление всех данных без проверок */ TRUNCATE TABLE TEST_DATA_2;
1. Объявляя имена таблиц, обращайся к записям через псевдонимы таблиц
Допустим, есть таблица с некоторым количество колонок. К ней можно обратиться двумя разными способами:
⚠️ Опасный подход:
SELECT TYPE
,VALUE
FROM TEST_DATA_1;
✅ Безопасный подход заключается в обращении через псевдоним:
SELECT t1.TYPE AS TYPE
,t1.VALUE AS VALUE
FROM TEST_DATA_1 t1;
Псевдоним (анг. Alias) — это имя, назначенное источнику данных в SQL-запросе при использовании выражения в качестве источника данных или для упрощения ввода и прочтения инструкции SQL. Это полезно, если имя источника слишком длинное или его трудно вводить.
Псевдонимы можно использовать для переименования таблиц и колонок. В отличие от настоящих имён, они могут не соответствовать ограничениям базы данных и содержать до 255 знаков (включая пробелы, цифры и специальные символы).
В случае извлечения данных из одной таблицы без псевдонимов можно обойтись. Рисков нет. Синтаксический анализатор базы данных однозначно знает, данные из какой колонки таблицы запрашиваются. Но рекомендуется всё же использовать их — чтобы выработать привычку.
В случае извлечения данных из нескольких таблиц отказ от использования псевдонимов увеличивает риск получения некорректного результата. Допустим, что у таблиц есть колонки с одинаковым именем. Когда данные извлекаются и SQL-запрос звучит как: «Получаю записи из таблиц колонку А», то о какой колонке «А» идёт речь: из первой или второй таблицы? Если для таблицы назначен псевдоним, то SQL-запрос может звучать уже так: «Получаю записи из таблицы Т1 колонку А».
К SQL-запросу, возможно, придётся вернуться через какое-то время, чтобы внести в него изменения. В таких случаях подсказки в виде псевдонима (alias) помогут определить нужную колонку. Практически со стопроцентной уверенностью будет понятно, из какой таблицы что извлекали.
⚠️ Опасный подход:
SELECT TEST_DATA_1.TYPE
,TEST_DATA_1.VALUE
,TEST_DATA_2.TYPE
,TEST_DATA_2.VALUE
FROM TEST_DATA_1
,TEST_DATA_2
WHERE TEST_DATA_1.TEST_DATA_1_ID = TEST_DATA_2.TEST_DATA_1_ID;

✅ Безопасный подход заключается в обращении через псевдоним:
SELECT t1.TYPE AS TYPE_1 /* Колонка TYPE из таблицы TEST_DATA_1 */
,t1.VALUE AS VALUE_1 /* Колонка VALUE из таблицы TEST_DATA_1 */
,t2.TYPE AS TYPE_2 /* Колонка TYPE из таблицы TEST_DATA_2 */
,t2.VALUE AS VALUE_2 /* Колонка VALUE из таблицы TEST_DATA_2 */
FROM TEST_DATA_1 t1
,TEST_DATA_2 t2
WHERE t1.TEST_DATA_1_ID = t2.TEST_DATA_1_ID;
2. Извлекай только те данные, которые планируешь использовать
База данных зачастую является неотъемлемой частью приложения. По мере усложнения функционала в отдельной взятой таблице может увеличиваться количество колонок.
Рассмотрим пример «Карточка сотрудника». У нас есть таблица «Сотрудник» с колонками ФИО, пол, возраст. Данные из них извлекаются и выводятся на форму «Карточка сотрудника». SQL-запрос можно написать следующим образом: «Извлекаю все колонки из таблицы по указанному сотруднику». В таком случае извлекаются все колонки.
⚠️ Опасный подход заключается в извлечении всех данных:
SELECT t1.* FROM TEST_DATA_1 t1 WHERE t1.TEST_DATA_1_ID = 3 /* ID EMPLOYEE = СОТРУДНИК 1 */;

В будущем могут появиться дополнительные колонки в базе данных — например, описание должностных обязанностей или адрес проживания — в рамках нового информационного потока использования базы данных. То есть вне «Карточки сотрудника».
/* Добавление новой колонки в таблицу */ ALTER TABLE TEST_DATA_1 ADD DESCRIPTION VARCHAR2(4000) / /* Обновление данных в таблице */ UPDATE TEST_DATA_1 t1 SET T1.DESCRIPTION = 'ДОПОЛНИТЕЛЬНЫЕ ДАННЫЕ ПО СОТРУДНИКУ 1' WHERE t1.TEST_DATA_1_ID = 3 /* ID EMPLOYEE = СОТРУДНИК 1 */; /* Извлечение данных из таблицы */ SELECT t1.* FROM TEST_DATA_1 t1 WHERE t1.TEST_DATA_1_ID = 3 /* ID EMPLOYEE = СОТРУДНИК 1 */;

В результате данные по новым полям заполняются уже не только формой «Карточки сотрудника». И SQL-запрос получения информации для формы начинает работать медленнее. Причина в том, что приходится извлекать данные из большего количества колонок.
Деградация скорости получения данных может происходить постепенно или резко — но в самый неподходящий момент. Зачастую это связано с тем, что поля свободного ввода данных могут быть большими. То есть база данных должна больше информации подгрузить в память и потом отдать клиенту, приложение которого не готово к такому потоку данных.
Рассмотрим пример «Телефон». На телефоне пользователя установлено приложение. Сам телефон старый. Пользователь не выполнял обновления программного обеспечения (ПО), но замечает, что с какого-то момента времени приложение начало работать медленнее. У другого пользователя на новом телефоне то же приложение работает быстро. Ошибка «плавающая», но для разработчика неприятная.
Как правило, дело в том, как написано приложение. Данных извлекается больше, чем надо, и более современный телефон, у которого памяти больше, этого не заметит. Но старый не может себе этого позволить.
Чтобы таких неожиданностей не возникало, нужно извлекать строго те данные, которые требуется использовать и показывать на форме. В данном случае нужно было написать: «Извлекаю колонки ФИО, возраст, пол из таблички сотрудника, с фильтрацией по сотруднику».
✅ Безопасный подход заключается в получении нужных данных:
SELECT t1.TYPE AS TYPE_1 /* Колонка TYPE из таблицы TEST_DATA_1 */
,t1.VALUE AS VALUE_1 /* Колонка VALUE из таблицы TEST_DATA_1 */
FROM TEST_DATA_1 t1
WHERE t1.TEST_DATA_1_ID = 3 /* ID EMPLOYEE = СОТРУДНИК 1 */;

3. По максимуму используй данные, которые извлёк из таблицы
Каждый SQL-запрос к базе данных чего-то стоит. В тот момент, когда данные извлечены и находятся в памяти, надо по максимуму использовать то, что получено, чтобы оптимизировать время и ресурсы.
После обращения к таблице Table1, нужно постараться написать SQL-запрос так, чтобы не пришлось извлекать данные из неё несколько раз. Это не всегда возможно, но попытаться стоит.
⚠️ Опасный подход:
SELECT t1.TYPE AS TYPE_1
,t1.VALUE AS VALUE_1
,t2.VALUE AS VALUE_2
FROM TEST_DATA_1 t1
,TEST_DATA_2 T2
WHERE T1.TEST_DATA_1_ID = T2.TEST_DATA_1_ID
AND t2.VALUE = 'ПРОЖИВАЕТ В ГОРОДЕ МОСКВА'
UNION ALL
SELECT t1.TYPE AS TYPE_1
,t1.VALUE AS VALUE_1
,t2.VALUE AS VALUE_2
FROM TEST_DATA_1 t1
,TEST_DATA_2 T2
WHERE T1.TEST_DATA_1_ID = T2.TEST_DATA_1_ID
AND t2.VALUE = 'ПРОЖИВАЕТ В ГОРОДЕ САНКТ-ПЕТЕРБУРГ'
ORDER BY VALUE_1;

/* План запроса */
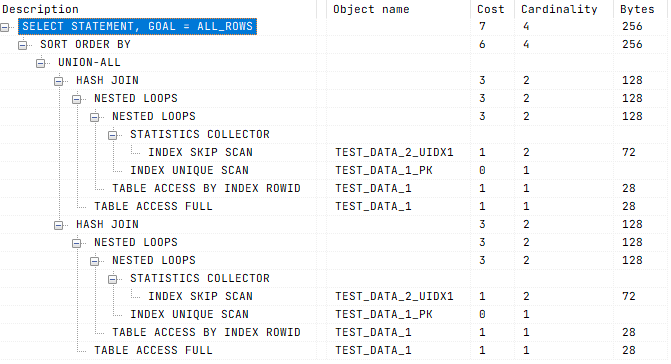
✅ Безопасный подход заключается в использовании полученных данных максимально продуктивно:
SELECT t1.TYPE AS TYPE_1
,t1.VALUE AS VALUE_1
,t2.VALUE AS VALUE_2
FROM TEST_DATA_1 t1
,TEST_DATA_2 T2
WHERE T1.TEST_DATA_1_ID = T2.TEST_DATA_1_ID
AND t2.VALUE IN ('ПРОЖИВАЕТ В ГОРОДЕ МОСКВА', 'ПРОЖИВАЕТ В ГОРОДЕ САНКТ-ПЕТЕРБУРГ')
ORDER BY VALUE_1;

/* План запроса */
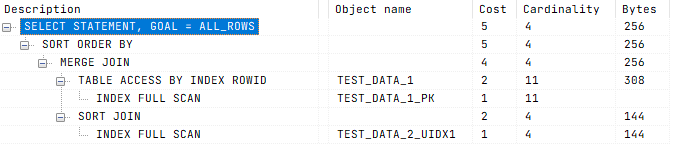
Неоптимальный SQL-запрос может выполняться дольше, уронить инфраструктуру и даже повлиять на безопасность системы.
⚒ Рассмотрим тестовый пример:
/*
* Тестовый пример
* Каждый случай запроса выполняется 1 000 000 раз в “холостую”
*/
declare
start_time pls_integer;
end_time pls_integer;
begin
/* 1 Случай */
start_time := dbms_utility.get_time;
for indx in 1 .. 1000000 loop
for cur in (select t1.TYPE as TYPE_1
,t1.VALUE as VALUE_1
,t2.VALUE as VALUE_2
from TEST_DATA_1 t1
,TEST_DATA_2 T2
where T1.TEST_DATA_1_ID = T2.TEST_DATA_1_ID
and t2.VALUE = 'ПРОЖИВАЕТ В ГОРОДЕ МОСКВА'
union all
select t1.TYPE as TYPE_1
,t1.VALUE as VALUE_1
,t2.VALUE as VALUE_2
from TEST_DATA_1 t1
,TEST_DATA_2 T2
where T1.TEST_DATA_1_ID = T2.TEST_DATA_1_ID
and t2.VALUE = 'ПРОЖИВАЕТ В ГОРОДЕ САНКТ-ПЕТЕРБУРГ'
order by VALUE_1) loop
null;
end loop;
end loop;
end_time := dbms_utility.get_time;
dbms_output.put_line('execution time 1 --> ' || (end_time - start_time) / 100 || ' sec');
/* 2 Случай */
start_time := dbms_utility.get_time;
for indx in 1 .. 1000000 loop
for cur in (select t1.TYPE as TYPE_1
,t1.VALUE as VALUE_1
,t2.VALUE as VALUE_2
from TEST_DATA_1 t1
,TEST_DATA_2 T2
where T1.TEST_DATA_1_ID = T2.TEST_DATA_1_ID
and t2.VALUE in ('ПРОЖИВАЕТ В ГОРОДЕ МОСКВА', 'ПРОЖИВАЕТ В ГОРОДЕ САНКТ-ПЕТЕРБУРГ')
order by VALUE_1) loop
null;
end loop;
end loop;
end_time := dbms_utility.get_time;
dbms_output.put_line('execution time 2 --> ' || (end_time - start_time) / 100 || ' sec');
end;
/
/*
* Результат выполнения
* Важно не время, которое зависит от ресурсов на ПК, а разница выполнения
*/
/*
Done in 64,516 seconds
*/
execution time 1 --> 46.83 sec
execution time 2 --> 17.67 sec
Рассмотрим пример «Работа ЦОД». Есть Центр Обработки Данных (ЦОД). В нём, на одном из ресурсов внутри приложения, выполняется некий SQL-запрос, который постепенно использует всю доступную память без ограничений. И приложениям, которые стоят на том же ресурсе, со временем перестаёт хватать памяти на стабильную работу. Это может привести к их падению.
Конечно, многое будет зависеть от качества приложений. Например, если во время падения они закрываются нетипично, подвисают или не отвечают на запросы пользователя — и выходят за рамки границ безопасности — хакеры могут этим пользоваться для входа в систему. И тем самым её скомпрометировать.
4. Проверяй запросы SQL на индексы
SQL-запросы бывают простые и сложные. Иногда извлекается мало данных, иногда — много. Если таблица большая, и в ней очень разнообразные данные, то в зависимости от того, как обращаться к этим данным, использовать индекс или нет, можно потерять время.
Рассмотрим пример «Брокерская биржа». В рамках отдельного процесса извлекаются данные для покупки-продажи акций. Используя оптимизированный SQL-запрос, можно быстро получать информацию, по какой цене торгуется каждая акция. И делать прогноз — покупать или продавать.
Если SQL-запрос не оптимизирован, извлечение данных занимает больше времени. И пользователь вынужден ждать, хотя мог за это время сделать что-то, что принесло бы ему деньги.
Индексы — это инструмент оптимизации извлечения данных. Конечно, это не панацея, и если таблица маленькая, по ней проще пройти прямым перебором и получить данные.
Добавим в тестовую таблицу 1 новые данные:
/* Добавление новых данных */
INSERT INTO TEST_DATA_1 (TYPE, VALUE) VALUES ('STOCK MARKET', 'АКЦИЯ 1. СТОИМОСТЬ 101 РУБ');
INSERT INTO TEST_DATA_1 (TYPE, VALUE) VALUES ('STOCK MARKET', 'АКЦИЯ 2. СТОИМОСТЬ 102 РУБ');
INSERT INTO TEST_DATA_1 (TYPE, VALUE) VALUES ('STOCK MARKET', 'АКЦИЯ 3. СТОИМОСТЬ 103 РУБ');
INSERT INTO TEST_DATA_1 (TYPE, VALUE) VALUES ('STOCK MARKET', 'АКЦИЯ 4. СТОИМОСТЬ 104 РУБ');
⚠️ Опасный подход заключается в игнорировании использования индексов:
/* Извлечение всех данных TYPE = STOCK MARKET */
SELECT t1.TYPE AS TYPE_1
,t1.VALUE AS VALUE_1
FROM TEST_DATA_1 t1
WHERE t1.TYPE = 'STOCK MARKET';
/* План запроса */

Добавим в тестовую таблицу 1 новый индекс
/* Добавление нового индекса */ CREATE INDEX TEST_DATA_1_IDX1 ON TEST_DATA_1 (TYPE) /
✅ Безопасный подход заключается в использовании индексов:
/* Извлечение всех данных TYPE = STOCK MARKET */
SELECT t1.TYPE AS TYPE_1
,t1.VALUE AS VALUE_1
FROM TEST_DATA_1 t1
WHERE t1.TYPE = 'STOCK MARKET';
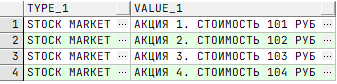
/* План запроса */

Рассмотрим пример «Доставка почты». Показательный пример работы индексов — доставка почты из точки А в одном городе, в точку Б в другом. Зная, куда конкретно нужно доставить посылку, мы можем идти по индексам и определить, где и когда повернуть, чтобы довезти посылку за максимально короткое время. Если везти посылку на машине, то это сокращает расход топлива — а значит, и материальные издержки на доставку.
В противном случае можно сворачивать не там, спрашивать дорогу у прохожих, которые знают её плохо. И, вместо того чтобы доставить посылку за Время Т1, опоздать на Время Т2. В итоге покупатель ждёт, а продавец теряет деньги.
Индексы помогают ускорить извлечение данных.
5. Начинай запрос SQL с таблицы с меньшим набором записей
Допустим, нам нужно соединить две таблицы: с маленьким количеством записей и с большим. Стоит сделать следующее:
- начинать извлечение данных из таблицы с меньшим набором данных;
- продолжать извлечение данных из таблицы с большим набором данных.
⚒ Добавим в тестовую таблицу 2 новые данные:
/* Добавление новых данных */
declare
l_type test_data_2.type%type := 'STOCK MARKET';
l_value_2 test_data_2.value%type := '';
l_sql varchar2(128) := '';
begin
/* Извлечение данных из тестовой таблицы 1 */
for cur_t1 in (select t1.test_data_1_id as test_data_1_id
,t1.type as type_1
,t1.value as value_1
from TEST_DATA_1 t1
where type = l_type) loop
/* Цикл до 1 000 000 на каждую полученную запись из тестовой таблицы 1 */
for indx in 1 .. 1000000 loop
l_value_2 := cur_t1.value_1 || '. ' || 'ЗАПИСЬ ' || indx;
l_sql := 'INSERT INTO TEST_DATA_2 (TEST_DATA_1_ID, TYPE, VALUE) VALUES (' || --
cur_t1.TEST_DATA_1_ID || ', ' || --
'''' || l_type || ''', ' || --
'''' || l_value_2 || ''')';
/* Выполнение динамического запроса */
execute immediate l_sql;
end loop;
end loop;
end;
/
/* Общее число записей в таблице TEST_DATA_1 */
SELECT COUNT(1) AS CNT
FROM TEST_DATA_1
/

/* Общее число записей в таблице TEST_DATA_2 */ SELECT COUNT(1) AS CNT FROM TEST_DATA_2 /
/* Добавление нового индекса для таблицы TEST_DATA_1 */
CREATE INDEX TEST_DATA_1_IDX2 ON TEST_DATA_1 (TEST_DATA_1_ID, TYPE)
/
/* Добавление нового индекса для таблицы TEST_DATA_2 */
CREATE INDEX TEST_DATA_2_IDX1 ON TEST_DATA_2 (TEST_DATA_1_ID, TYPE)
/
CREATE INDEX TEST_DATA_2_IDX2 ON TEST_DATA_2 (TEST_DATA_1_ID)
/
CREATE INDEX TEST_DATA_2_IDX3 ON TEST_DATA_2 (TYPE)
/
/* Сбор статистики после добавления данных */
declare
l_user varchar2(30 char) := user;
begin
/* Для таблицы TEST_DATA_1 */
DBMS_STATS.GATHER_TABLE_STATS(ownname => l_user --
,tabname => 'TEST_DATA_1'
,cascade => true);
/* Для таблицы TEST_DATA_2 */
DBMS_STATS.GATHER_TABLE_STATS(ownname => l_user --
,tabname => 'TEST_DATA_2'
,cascade => true);
end;
/
Если поступить наоборот, то мы потеряем время, потому что перебирать данные из большей таблицы дольше.
⚒ Рассмотрим тестовый пример:
/*
* Тестовый пример
* Каждый случай запроса выполняется 100 раз в “холостую”
* Запросы усложнены и их можно упростить, добиваясь большей производительности и схожего результата
* Попробуйте поэкспериментировать
*/
declare
start_time pls_integer;
end_time pls_integer;
begin
/* 1 Случай. От большего к меньшему */
start_time := dbms_utility.get_time;
for indx in 1 .. 100 loop
for cur in (select t1.type as type_1
,t1.value as value_1
,t2_.type_2 as type_2
,t2_.value_2_min as value_2_min
,t2_.value_2_max as value_2_max
,t2_.value_2_cnt as value_2_cnt
from (select t2.TEST_DATA_1_ID as TEST_DATA_1_ID
,t2.TYPE as TYPE_2
,min(t2.VALUE) as VALUE_2_MIN
,max(t2.VALUE) as VALUE_2_MAX
,count(t2.VALUE) as VALUE_2_CNT
from TEST_DATA_2 t2
where t2.type = 'STOCK MARKET'
group by t2.TEST_DATA_1_ID
,t2.TYPE
order by t2.TEST_DATA_1_ID) t2_
join TEST_DATA_1 t1
on t1.TEST_DATA_1_ID = t2_.TEST_DATA_1_ID
and t1.type = 'STOCK MARKET'
order by t1.value) loop
null;
end loop;
end loop;end_time := dbms_utility.get_time;
dbms_output.put_line('execution time 1 --> ' || (end_time - start_time) / 100 || ' sec');
/* 2 Случай. От меньшего к большему */
start_time := dbms_utility.get_time;
for indx in 1 .. 100 loop
for cur in (select t1_.type_1 as type_1
,t1_.value_1 as value_1
,t2.type as type_2
,min(t2.value) as value_2_min
,max(t2.value) as value_2_max
,count(t2.value) as value_2_cnt
from (select t1.TEST_DATA_1_ID as TEST_DATA_1_ID
,t1.TYPE as TYPE_1
,t1.VALUE as VALUE_1
from TEST_DATA_1 t1
where t1.TYPE = 'STOCK MARKET'
order by t1.value) t1_
join TEST_DATA_2 t2
on t2.TEST_DATA_1_ID = t1_.TEST_DATA_1_ID
and t2.TYPE = 'STOCK MARKET'
group by t1_.type_1
,t1_.value_1
,t2.type) loop
null;
end loop;
end loop;
end_time := dbms_utility.get_time;
dbms_output.put_line('execution time 2 --> ' || (end_time - start_time) / 100 || ' sec');
end;
/
/*
* Результат выполнения
* Важно не время, которое зависит от ресурсов на ПК, а разница выполнения
* Каждый вариант возвращает одинаковые данные
*/

/* Executed in 269,203 seconds */ execution time 1 --> 149.49 sec execution time 2 --> 119.68 sec
Рассмотрим пример «Очередь клиентов». Есть поток клиентов, каждого из которых нужно обслужить. Операторы, заполняя форму «Анкета» задают серию вопросов. Один из них, влияет на дальнейший ход общения: «Вам исполнилось 18 лет?». Если клиент отвечает нет, то оператор прекращает общение, иначе продолжает задавать вопросы.
Если оператор задаст вопрос про возраст в конце общения, то любой потенциальный клиент должен будет заполнить всю анкету, даже если в этом нет смысла. Рациональный подход в общении с клиентами помогает операторам за одно и то же время обслужить большее число клиентов. С базами данных всё так же.