SELF-DISCOVER
Возможность строить рассуждения стала, возможно, вторым главным фактором (наряду с размером), который привел LLM к мировому господству. Фраза “Let’s think step by step”, добавленная к промпту, оказалась способна заметно улучшить качество модели.
Сразу же расцвели десятки новых подходов — какие-то разбивают задачу на части, какие-то строят обобщения, какие-то её переформулируют. Подходов масса и каждый оказывается лучше других на каких-то определенных задачах. Вот тут-то и заметили проблему авторы из Google DeepMind и Калифорнийского университета. Схем рассуждения много и все они хороши, но не хватает последнего куска пазла. Авторы предложили фреймворк Self-Discover, который объединяет все придуманные техники рассуждений и учит модель самой выбирать подходящие под конкретную задачу варианты.

В Self-Discover когда модель получает задание, она сначала изучает, как должны быть устроены рассуждения в данном конкретном случае. Эти метарассуждения состоят из трёх мета-промптов, которые 1. выбирают, 2. адаптируют 3. реализуют схему рассуждений. Все три шага реализуются последовательно с помощью LLM. Затем, подобранную схему рассуждений применяют для собственно генерации ответа.
Всего в Self-Discover подключено 39 возможных модулей рассуждения. Туда, конечно, входит “Let’s think step by step”, а еще промпты для разбиения на подзадачи, креативного мышления, систематического и другие. Они почти полностью скопированы из сентябрьской работы от Google DeepMind. Там авторы создали систему Promptbreeder, которая “скрещивала” эти 39 промптов в эволюционном процессе, чтобы улучшить рассуждения. Но вернёмся к Self-Discover. Из 39 модулей выбирается 3 наиболее подходящих. Затем система переформулирует эти промпты в более подходящем для задания виде. Наконец, из этих адаптированных описаний формируется план действий.
Выбор трех подходов из 39 происходит на основе примеров заданий. Например, рефлективное мышление подойдут для научных теорий, а креативное — для задачи продолжить рассказ. Само описание подхода изначально дано довольно широко и расплывчато, поэтому шаг с перефразированием под конкретную задачу важен. Например, под какую-то арифметическую задачку был выбран общий подход “break the problem into subproblems”. Теперь его нужно актуализировать под арифметику: “calculate each arithmetic operation in order”. Составление плана действий после этого происходит также с помощью примеров — написанных человеком схем рассуждений для других задач.

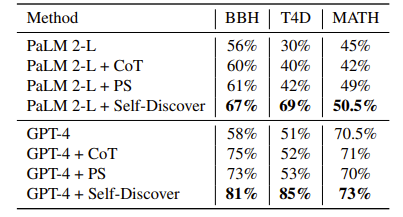
Для экспериментальной проверки авторы выбрали бенчмарки, с которыми у различных LLM пока возникают трудности: BIG-Bench Hard (BBH), Thinking for Doing (T4D) и MATH. Первый содержит 23 сложных задания, отобранных из BIG-Bench. Они включают алгоритмическое и многоходовое рассуждение, понимание естественного языка, использование мировых знаний и мультиязычное рассуждение. В T4D модели должны использовать рассуждения о психическом состоянии, чтобы принимать решения.
Self-Discover прикрутили к GPT-4, GPT-3.5-turbo, PaLM 2-L и Llama2-70B и сравнили в другими zero-shot методами (Chain of thought, Plan-and-Solve). Self-Discover улучшил рассуждения PaLM 2-L и GPT-4 на всех бенчмарках. На BBH улучшение по сравнению с Chain of thought и Plan-and-Solve составили от 6% до 8%, на T4D — более 27%. Слабее всего результат на MATH — от 1% до 7%.
Что случилось с GPT-3.5-turbo и Llama2-70B после добавления Self-Discover не совсем понятно, но об этом чуть ниже.
Лучше всего Self-Discover сработал на заданиях, в которых нужны разнообразные знания о мире. Например, понимание спортивных игр, рекомендации фильмов и так далее. Ниже график для PaLM 2-L; сравнивается Self-Discover c Chain-of-thought и прямым промптингом.

Успех именно по части “эрудированности” модели авторы относят именно к одновременному использованию нескольких схем рассуждения. По отдельности, например, Chain of though может упустить какие-то ключевые факты из рассуждений, а какое-нибудь креативное мышление не даст это сделать. Для более прямолинейных задач, типа алгоритмических, преимущество Self-Discover уже не такое заметное. В принципе, это объяснимо — чего тут думать, прыгать надо.
Еще одно важное свойство Self-Discover — возможность переноса между языковыми моделями. Self-Discover можно реализовать с помощью более серьезных моделей, вроде GPT-4, а затем в таком виде интегрировать в модели поменьше, вроде ChatGPT и Llama2-70B. В таком виде улучшение по сравнению с Chain of Thought составило до 10%.
Кажется, после “Let’s think step by step” в 2021-2022 и появилась профессия промпт-инженеров, которые упрашивают, заговаривают и подбирают волшебные слова к моделям. Споры об этой области не утихают, а кто-то уже предрекает промпт-инженерам скорое исчезновение за ненадобностью. Подход Self-Discover в какой-то мере подтверждает такое мнение.