Риск-ориентированный подход к DQ
Алексей ПахомовМы, как команда Data Quality, стремимся, чтобы о нас забыли: если никто не говорит про качество данных, значит, все хорошо. Можно провести аналогию с безопасностью - о нас вспоминают, когда творится что-то неладное. В мире безопасности давно главенствует риск-ориентированный подход с инструкциями нудными, сложными в реализации, но выверенными. По такому пути мы и пошли: начали выявлять риски качества данных и оценивать их ущерб.
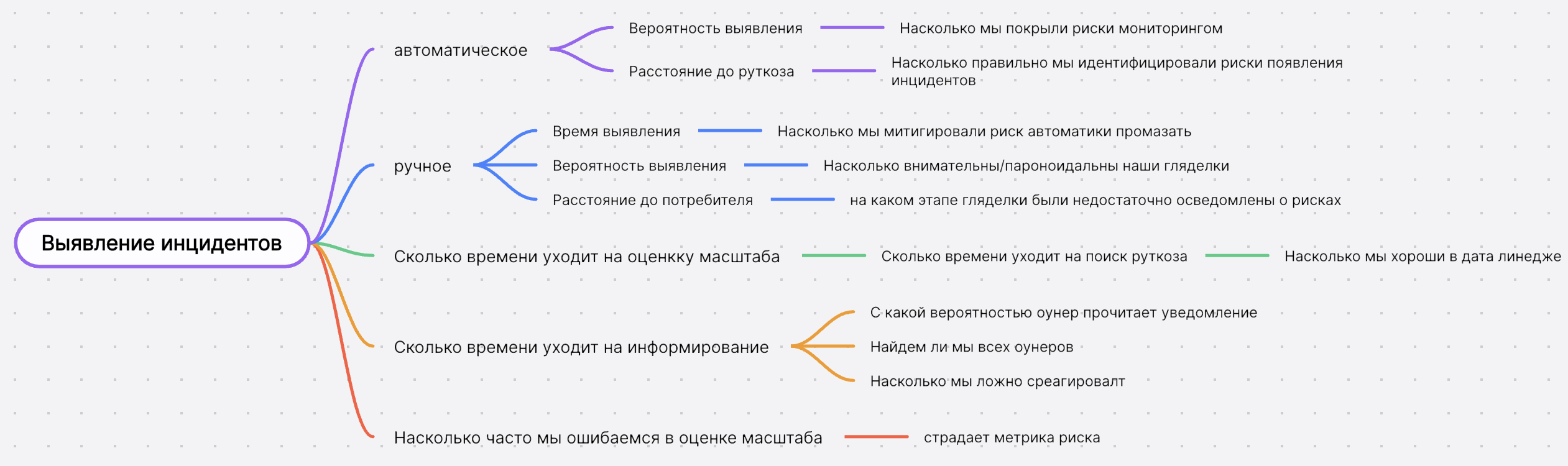
Проведя аналитику рисков, мы пришли к страшному пониманию: метрик много, считать придется долго, а снижать риск надо уже сейчас. Самое ужасное — предотвращать и расследовать буквально нужно одним и тем же людям. Поэтому для старта мы выбрали фокус на двух метриках.
Первая метрика - это количество пропущенных автоматикой инцидентов. У нас в платформе развит self-service подход и многие проблемы с данными проходили мимо команды DQ. Это не позволяло узнать о способах их выявления и предотвращения в будущем. Глобально есть три способа поиска инцидентов - автоматическая проверка дата контрактов поставки, факторный анализ метрик потребления и data-science всего подряд. Мы решили исчерпать классические 2 и начать пробовать себя в 3. В результате анализа выделили минимальный набор тестов, который позволяет детектировать 80% от всех пропущенных инцидентов.
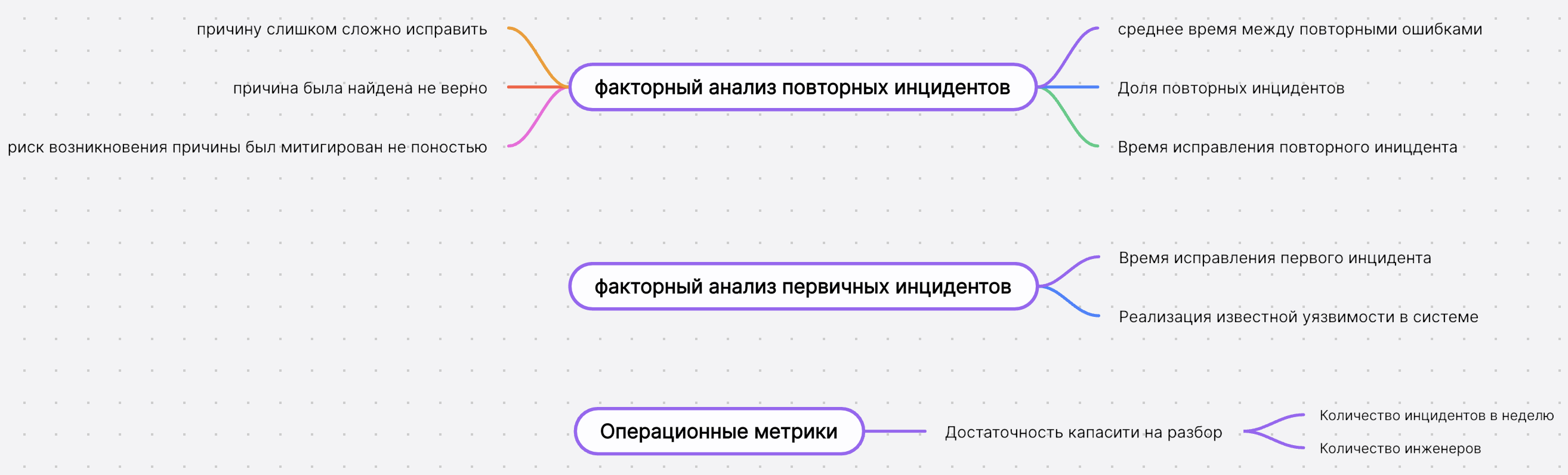
Вторая метрика - операционная: «а сколько мы накопили инцидентов нерешенных». Почему не общее количество или среднее время решения? Потому что у нас self-service, big-data и это приносит два важных аспекта: скорость зачастую зависит от того, что где у кого и когда ломается, и как много задето. Поэтому средние / медианы и любые подобные метрики на небольшой неоднородной выборке не применимы, а вот достаточность воронки разгребания и фокус на ней показал себя предсказуемее.
Для того, чтобы копить меньше инцидентов, нам нужно их быстрее разбирать и искать корневую причину. Незаменимым инструментом для решения этой задачи для нас является Data Lineage.
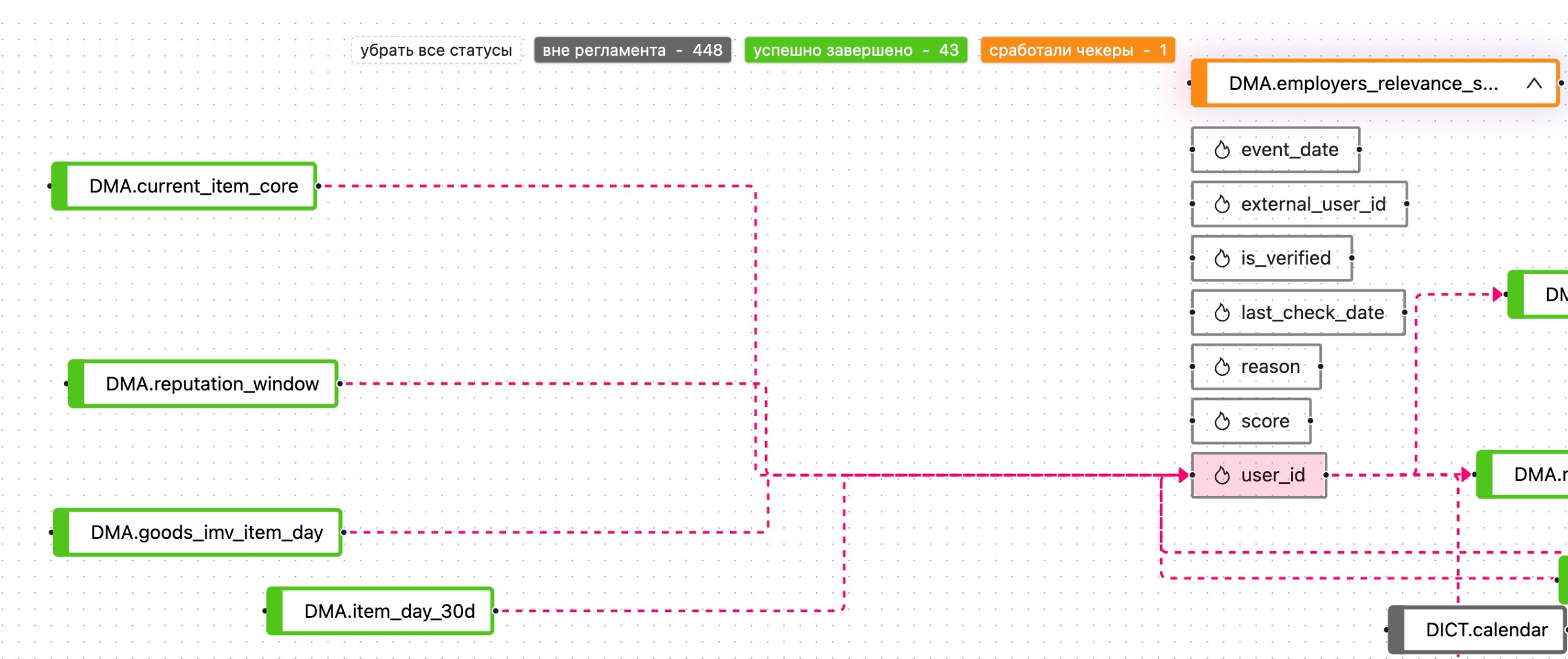
В следующих постах расскажем о том как мы улучшаем процесс оценки масштаба инцидента и как это помогает ускорить основной фактор времени на поиск инцидентов.