ResNet
DeepSchoolПредисловие
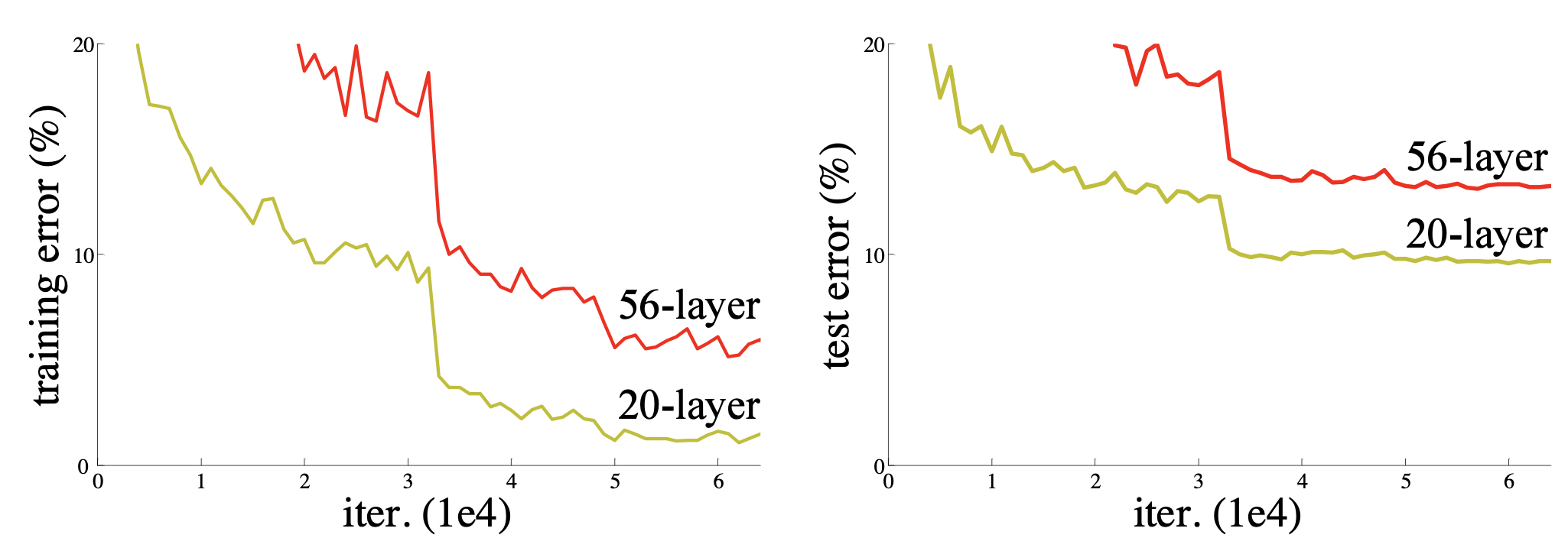
В посте про VGG мы писали, что сделать сеть ещё глубже не получится, так как градиенты начинают затухать. Авторы статьи про ResNet еще раз убедились в этом факте: обучили сверточные сети глубиной 20 и 54 слоя на CIFAR-10 и увидели, что глубокая сеть показывает себя хуже.
Ключевая идея
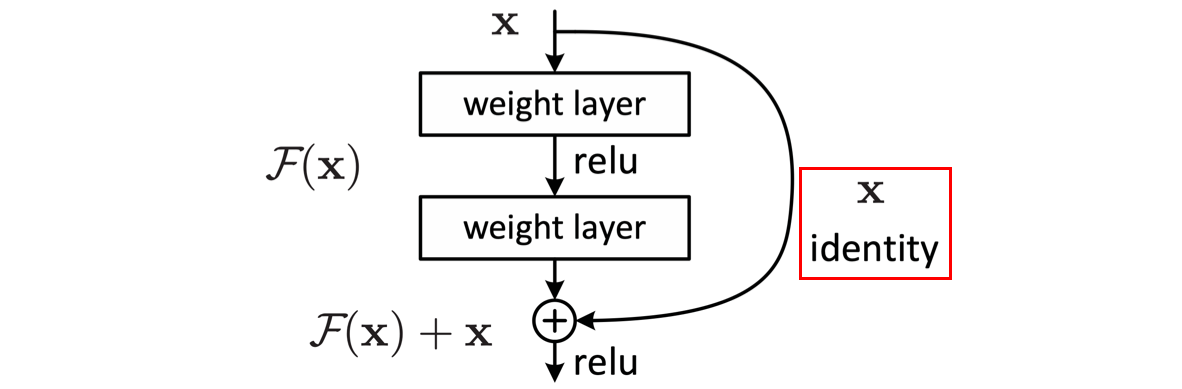
У авторов статьи возникла идея: что если дать возможность сети самой выбирать оптимальную глубину? Например, построить нейронную сеть в 56 слоёв таким образом, чтобы последние 36 могли передать тензор с выхода 20 слоя. Вот так, все думают что авторы изначально решали проблему затухающего градиента, но первая гипотеза была совсем иной :)
Чтобы у сети была возможность передать тензор через несколько слоёв без существенных изменений, авторы ввели дополнительную связь, которая обозначена красной рамкой на рисунке 2. Дополнительную связь назвали identity (идентичный), а блок с такой связью — residual (остаточный). Если на вход residual блоку пришел тензор x, то на выходе будет F(x) + x, где F(x) — это какой-то вычислительный блок. Если в процессе обучения сеть “решит” полностью обнулить F(x), то благодаря дополнительной связи, тензор пройдет через residual блок без изменений. Это нововведение позволяет тренировать очень глубокие сети (в статье даже учили ResNet глубиной 1200 слоёв, но точность была чуть хуже остальных).
Но спасает такие глубокие сети не “отключение” наименее важных слоев, а дополнительное слагаемое в градиенте residual блока. Градиент для первых слоев — это результат перемножения градиентов всех последующих. И если градиенты поздних слоев станут ниже 1 по модулю, то к ранним слоям дойдут близкие к нулю значения. Но в формуле градиента для residual блока (рисунок 3) появляется дополнительная единица, которая спасет обратный проход от зануления при F`(x) близкой к нулю.
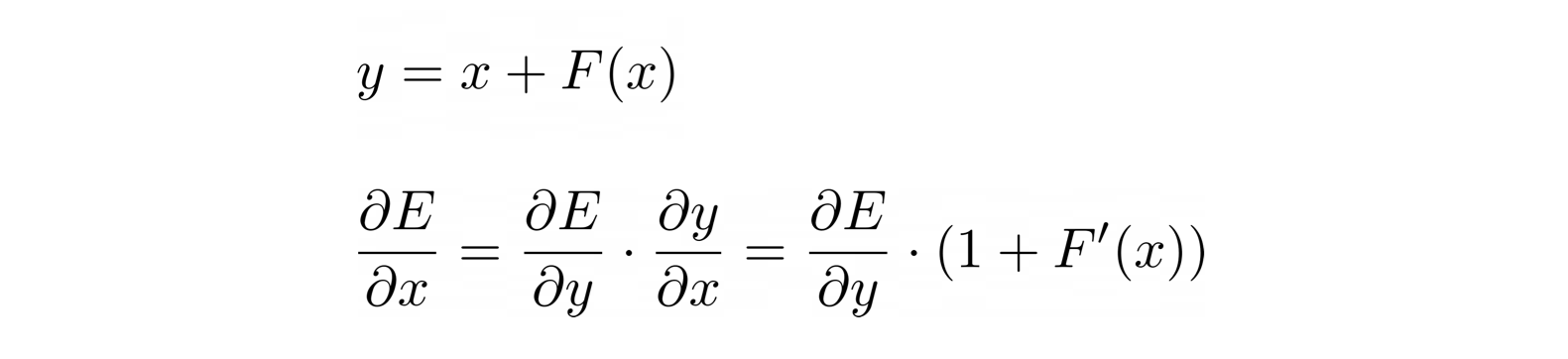
Архитектура
Архитектура показана на рисунке 4. Цветами выделены различные размеры протекающих тензоров. На стыке двух цветов количество каналов увеличивается в 2 раза, а ширина и высота тензора в 2 раза уменьшаются благодаря stride=2. Сплошные дугообразные стрелки — это identity без изменений размера тензора, а пунктирные с изменением размера.

Первый слой — свертка 7х7, за ней идет maxpooling, а потом ровный строй сверток 3х3 (почти во всех stride=1, кроме тех, что на стыке цветов — в них stride=2). И в самом конце стоит global average pooling и полносвязный слой. Пулинг считает среднее значение для каждого канала в тензоре, а полносвязный слой отображает эти значения в скоры классов.
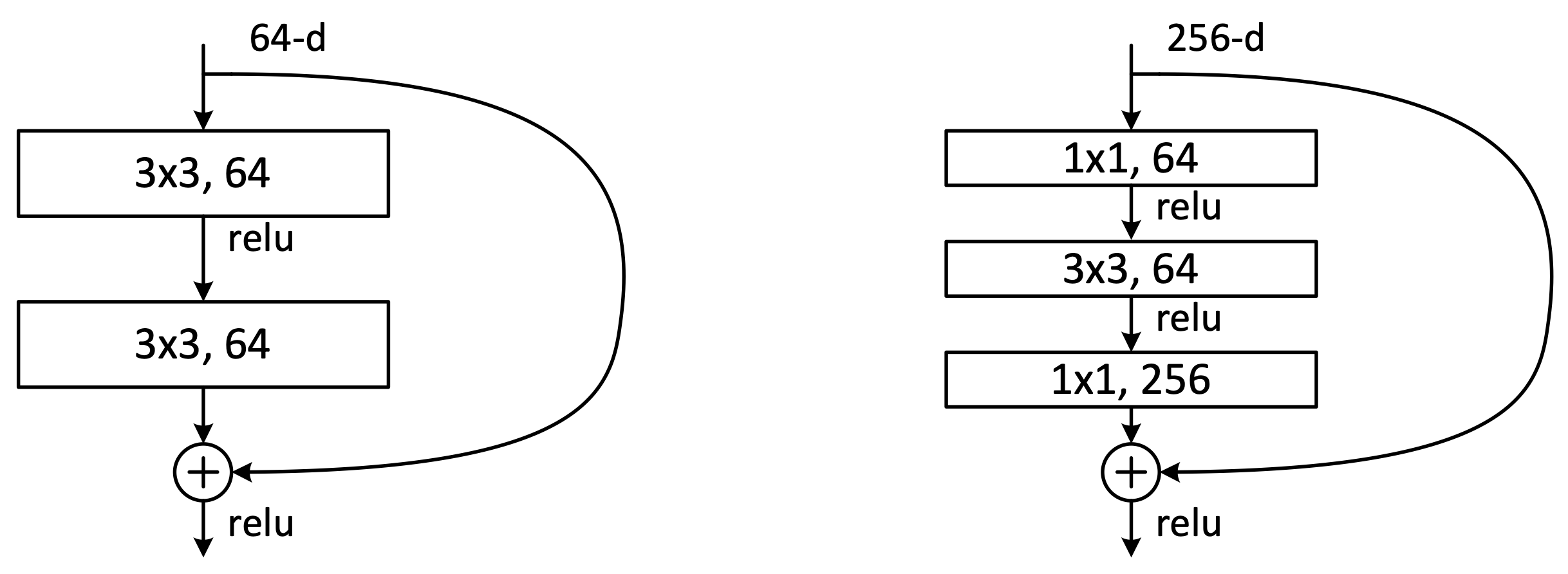
На рисунке 5 изображены разные residual block. Для более глубоких сетей (50+ слоёв) использовали residual block справа, известный как “bottleneck” (бутылочное горлышко). Первая свёртка 1х1 в ботлнеке уменьшает количество каналов, затем идет свёртка 3х3 и в конце опять 1х1, которая возвращает исходное количество каналов. Этот трюк позволяет увеличить глубину сети без резкого увеличения количества параметров.
В таблице 1 показаны архитектуры сетей, с которыми экспериментировали авторы. Можно заметить, что в сетях глубже 50 слоёв использовали bottleneck residual block (50-слойная сеть — это 34-слойная, в которой все блоки заменили на ботлнеки).

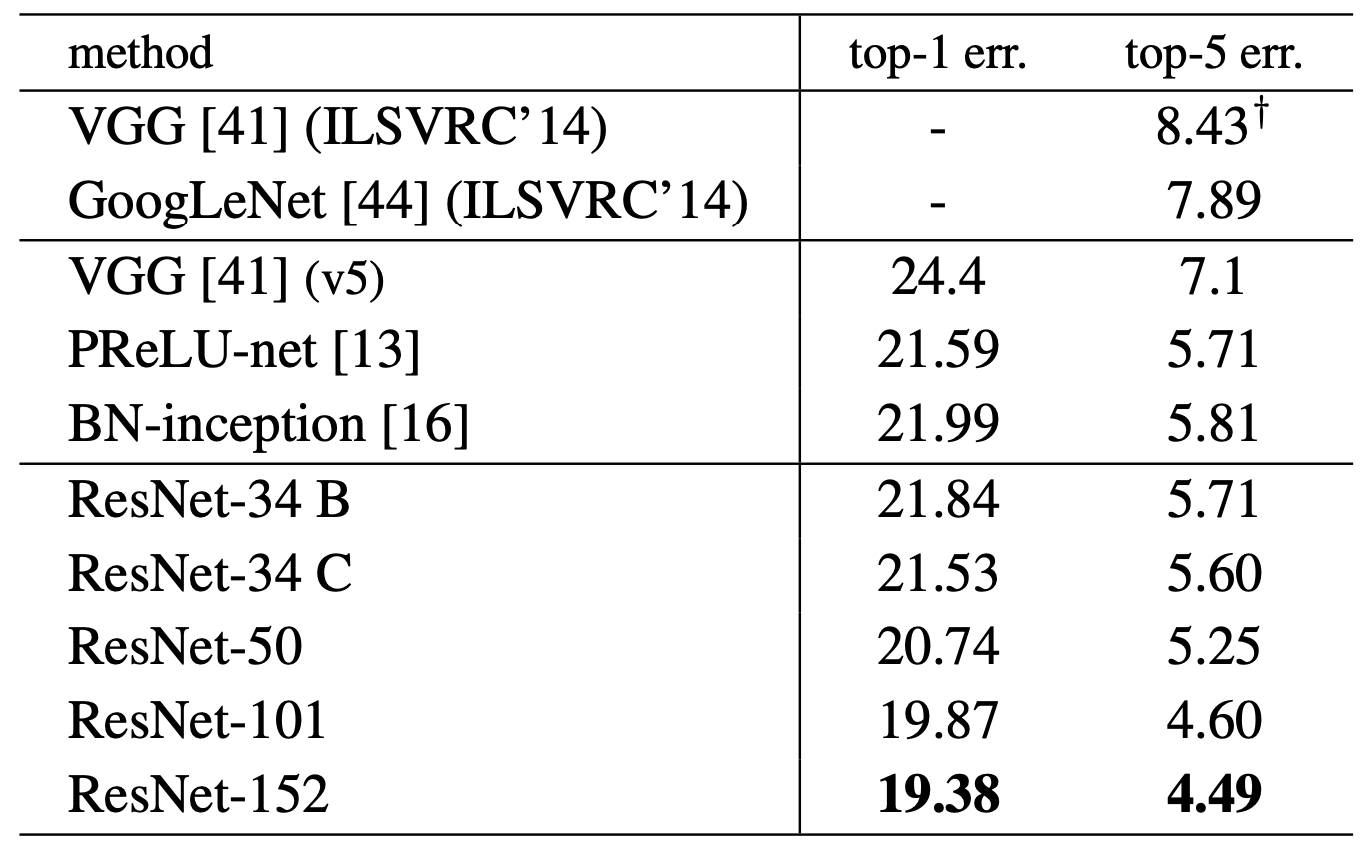
В таблице 2 видно, что с увеличением глубины сети растет и точность классификатора.
Вывод
Residual Block позволил обучать более глубокие сети, не боясь ухудшить их точность. Затем эту идею распространили и за пределы сверточных сетей. За 6 лет ResNet зарекомендовал себя как отличный backbone для различных CV задач, поэтому его совершенно не стыдно использовать и в современном мире :) Главное учить его правильно — кстати, об этом мы писали в одном из предыдущих постов.
Ссылки на дополнительные источники
Видео (рус.) хорошее и понятное видео, в котором другими словами пояснена работа рассмотренной архитектуры.
Два видео (англ.) Andrew Ng про ResNet 1 и 2.