Requests
Загрузил при помощи requests страницу по адресу 'https://www.vfbank.ru/fizicheskim-licam/monety/pamyatnye-monety/' и сохранил её на диск. Далее открыл сохраненный html файл в sublime text и попробовал поискать к html коде названия монет. Но их там не оказалось. Тут я подумал, что монеты на страницу могут подгружаться с помощью js.
Открыл инструменты разработчика и обновил страницу. В первую очередь меня интересовали xhr запросы:

Xhr запрос по адресу 'https://www.vfbank.ru/fizicheskim-licam/monety/pamyatnye-monety/?bxrand=1586775385684' заинтересовал меня, так как он возвращал что-то похожие на json и так же внутри ответа было что-то похожее на html.
Опять с помощью requests сделал запрос по адресу 'https://www.vfbank.ru/fizicheskim-licam/monety/pamyatnye-monety/?bxrand=158677538568', и сохранил ответ на диск. Но никакого json там не было, а был тот же html, что и в предыдущем запросе. Потом решил посмотреть, какие заголовки firefox передает:
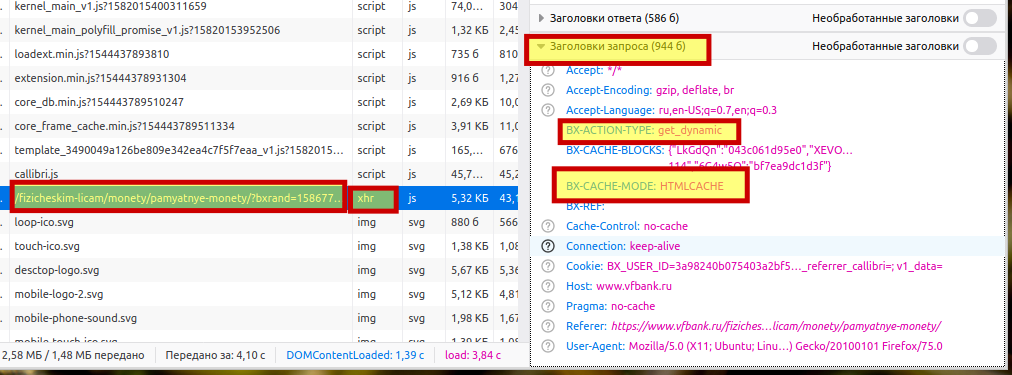
Мне лень было все их добавлять в requests, поэтому пошел методом тыка),
передал BX-ACTION-TYPE и BX-CACHE-MODE. И с первого раза получил json.

Вбил в поиск названия монет и нашел их. Но есть одно - НО! На первый взгляд это json. Загрузил его в online сервисы, чтобы удобно было смотреть:

Правда сервисам не совсем понравился данный файл, да и python отказался работать с данным файлом как с json. Ну тут я и подумал, что можно просто вырезать из этого файла нужные мне данные, а также очистить от ненужных символов.
После проделанных операций у меня остался чистый html код, с которым я работал с помощью BeautifulSoup.
Далее я кликнул по названию монеты, и в devtools Firefox увидел, по какому адресу браузер шлёт запрос:

Здесь не трудно догадаться, что подставив вместо 122 id другой монеты, мы получим данные конкретной монеты.