Регуляризуем правильно!
DeepSchoolПод термином регуляризация понимают набор различных методов для борьбы с переобучением и улучшением робастности модели.
В нейронных сетях эти методы можно разделить на три группы, которые изменяют:
- функцию потерь;
- структуру сети;
- входные данные (различные аугментации).
В этом посте мы рассмотрим две из них.
L1/L2 регуляризация
L1/L2 регуляризация — это методы регуляризации с изменением функции потерь. Смысл прост: будем добавлять к исходной функции потерь дополнительное слагаемое.
В случае L1 регуляризации это выглядит так:
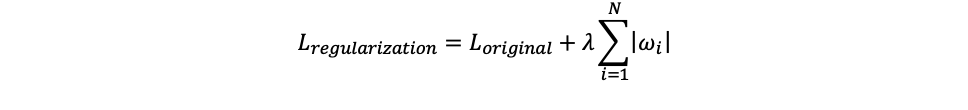
То есть добавляем сумму модулей весов нейронной сети и тем самым вводим дополнительный штраф за большое значение веса. Параметр λ (регуляризационный член) является гиперпараметром.
Для L2 регуляризации формула следующая:
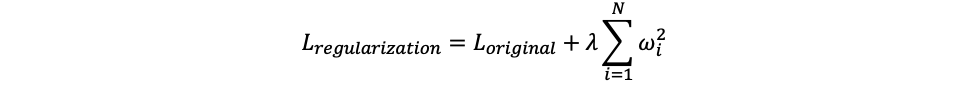
В данном случае штрафуем квадраты весов. Тут стоит отметить, что если выходное значение имеет смещение (y=Wx+b), то к смещению регуляризация не применяется.
У L1 и L2 регуляризаций есть свои преимущества и недостатки:
- L1 регуляризация дает разреженное решение: зануляет менее важные веса и шум. Это делает ее устойчивой к выбросам;
- L2 регуляризация не зануляет веса, что делает ее неустойчивой к выбросам (из-за возведения в квадрат), однако хорошо работает с сильно скоррелированными признаками, что позволяет использовать ее для сложных входных объектов (например, изображения);
- L2 регуляризация плохо работает с адаптивными методами градиентной оптимизации (например, Adam).
В глубоком обучении вместо L2 регуляризации используют схожий метод weight decay. Отличие от L2 регуляризации заключается в том, что в weight decay штраф добавляется не к функции потерь, а на этапе обновления весов. Соединив weight decay c Adam, получим новый оптимизатор AdamW, который показывает лучшее качество, нежели Adam.
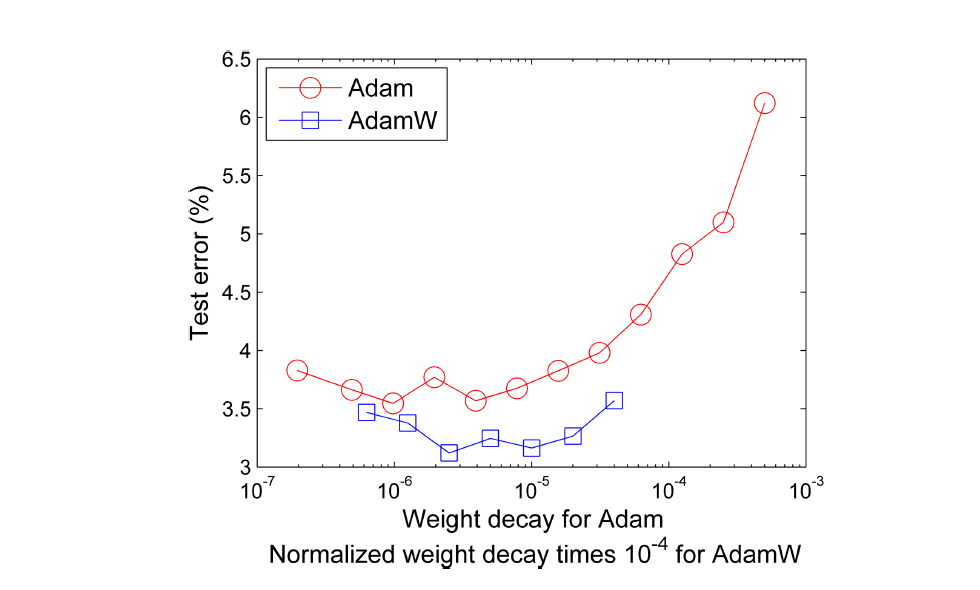
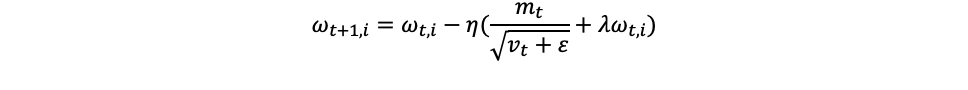
Dropout
Dropout — пример метода регуляризации, связанного с изменением структуры нейронной сети.
Он заключается в следующем: будем случайным образом занулять определенное число нейронов входного слоя на этапе обучения.
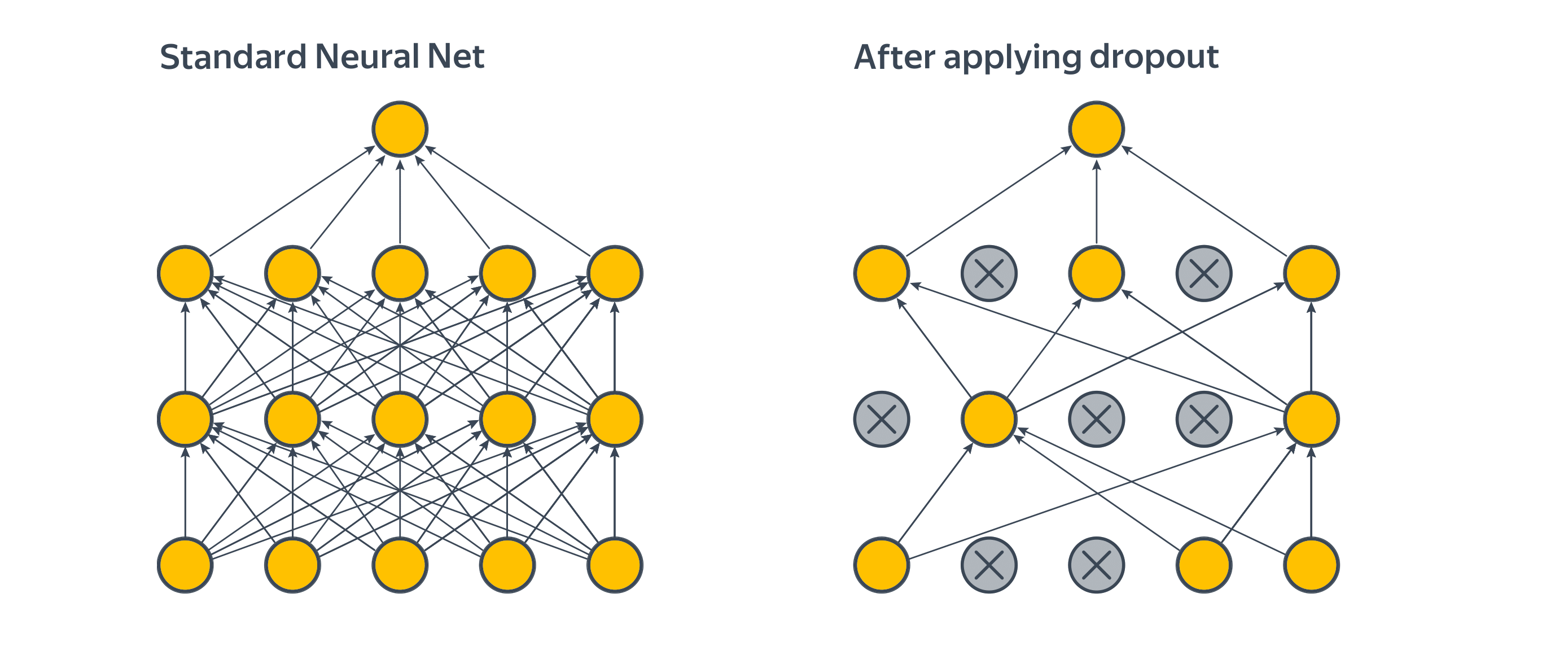
Тогда при «выключении» некоторых нейронов произойдёт резкое изменение предсказаний модели, что приведёт к увеличению ошибки, а полученные градиенты этой ошибки укажут, как её исправить с использованием оставшихся нейронов.
Реализация метода проста: слой Dropout умножает выход предыдущего слоя на маску из нулей и единиц:
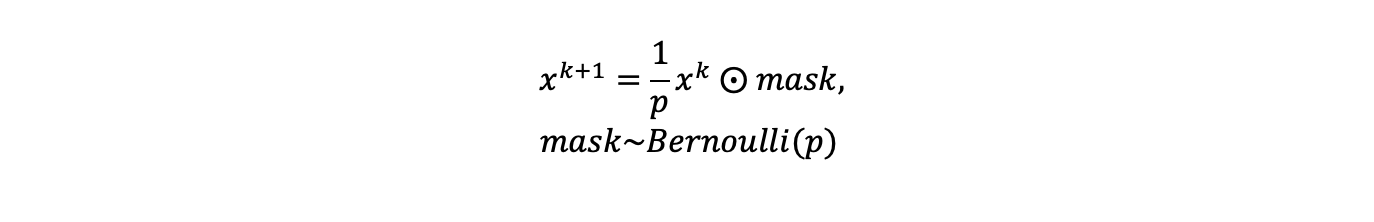
где p - вероятность обнуления, является гиперпараметром. Данная маска участвует и при подсчете градиентов. Маска генерируется независимо на каждом шаге прямого прохода сети. На этапе предсказания Dropout «выключается»: внутренние представления используются как есть, без умножения на маску. Множитель 1/p нужен для того, чтобы на этапе предсказания нейроны не получали дополнительных активаций и не становились «перевозбужденными».
Таким образом, благодаря Dropout, сеть выучивает более устойчивые представления на внутренних слоях. При этом имейте в виду, что увеличивается количество итераций, необходимых для сходимости сети.
Также не забывайте про несколько особенностей при использовании Dropout.
Первая особенность: Dropout не следует размещать между сверточными слоями. На это есть две причины: обычно в сверточных сетях не так много параметров, и в начале обучения им нужно как можно меньше обнулений и из-за пространственной корреляции карт признаков обнуление отдельных активаций бесполезно.
Для решения указанных проблем Dropout между свертками заменяют на DropBlock, в котором зануление весов происходит не случайным образом, а структурировано, а сам Dropout обычно размещают после последнего сверточного слоя перед классифицирующей «головой». Однако в большинстве современных сверточных архитектур Dropout заменен на Global Average Pooling.
Вторая особенность использования Dropout: использовать его стоит после Batchnorm, иначе Batchnorm будет собирать неверные статистики.