Регистрация
@de_syncДля примера взят исток Fellow.pl
Первое - снифаем запрос
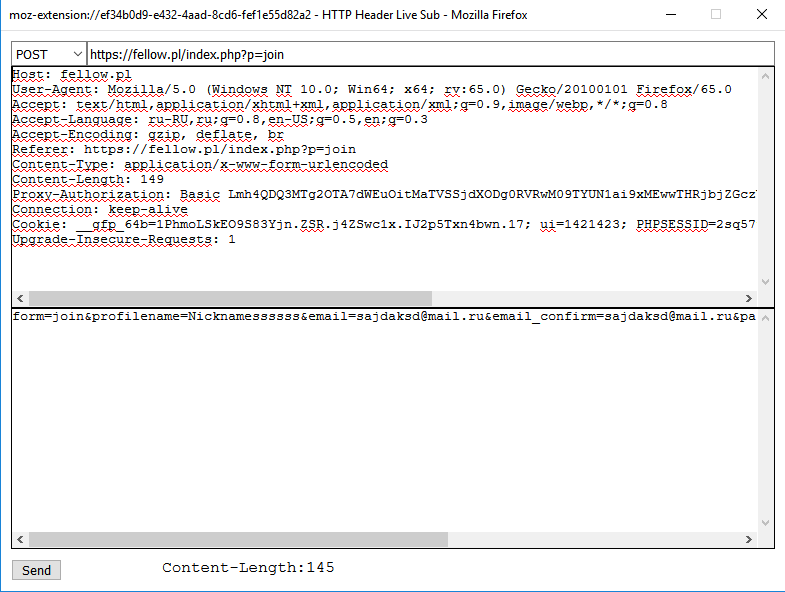
Получаем пост запрос, и сразу смотрим в тело, какие уникальные данные нам будут нужны, а это почта и никнейм. Значит нужны почты, в этом случае не буду брать одноразовые(будет дз). Берем пак мейл ру или любой другой в тхт файл.
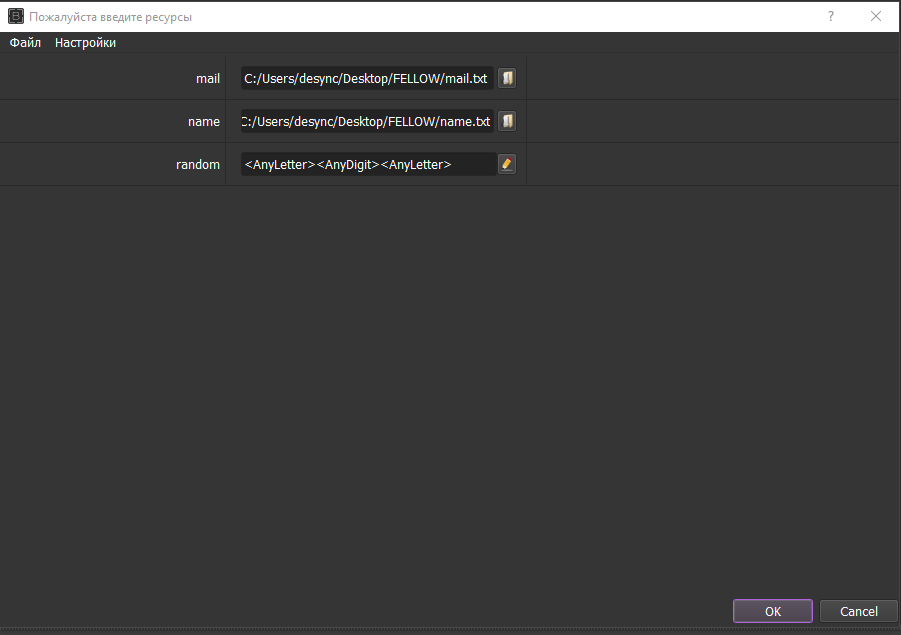
Создаем в басе сразу два ресурса "Из файла", первый это файл с мейлами, второй с именами, третий ресурс - генератор строк(буква, цифра, буква), для рандомизации никнеймов.
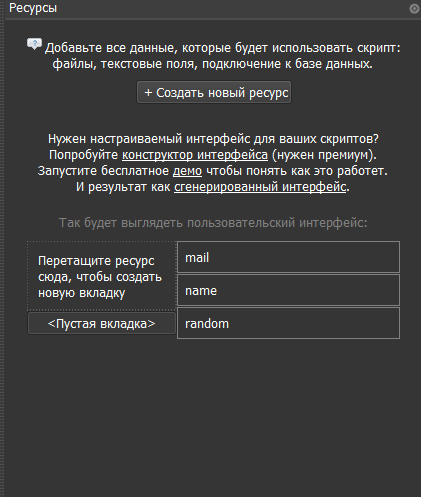
Переходим к созданию шаба. Выбираем наши файлы с почтами и именами в режиме записи
Для начала нам нужно создать переменную с рандомным именем. В переменную вставляем ресурсы с именем и рандомом, убирая галочки с повторного использования и назовем эту переменную "NAME"
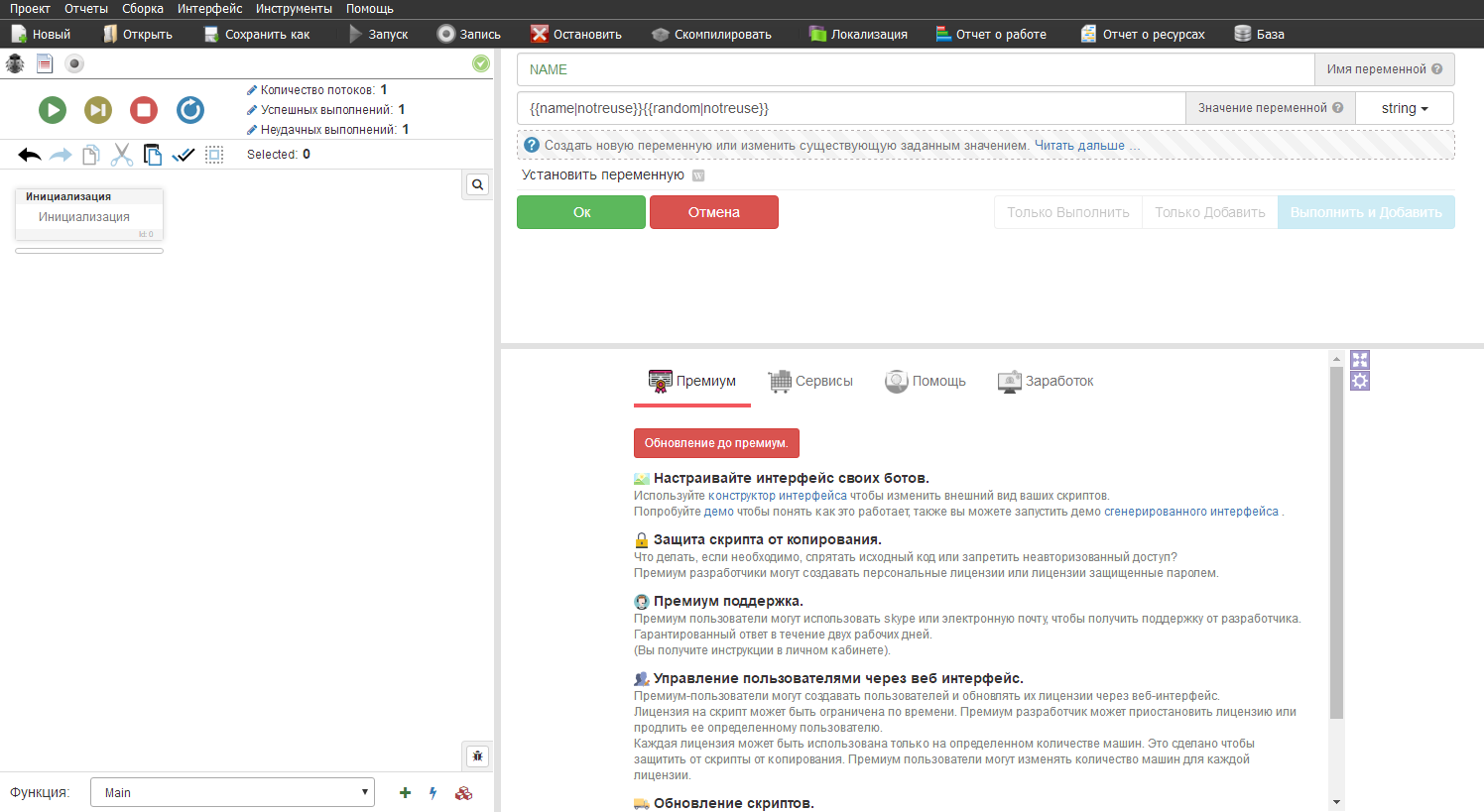
Аналогично делаем с почтами, т.к. в запросе нам нужно вставить ее дважды. Запомните, если какой-то из ресурсов дважды нужно использовать в одном шаблоне, то мы создаем переменную с этим ресурсом которую будем подставлять в последующие действия.
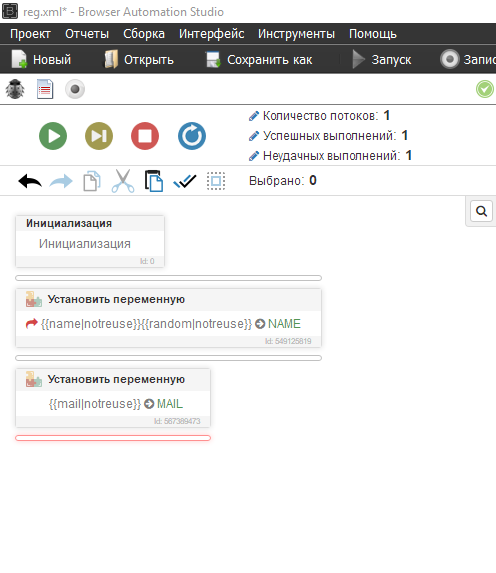
Исток польский, есть ограничение по странам, подключаем прокси, хттп клиент прокси, я добавлю один, если хотите работать с прокси листом, делаем аналогично мейлам и именам - ПЕРЕМЕННЫЕ
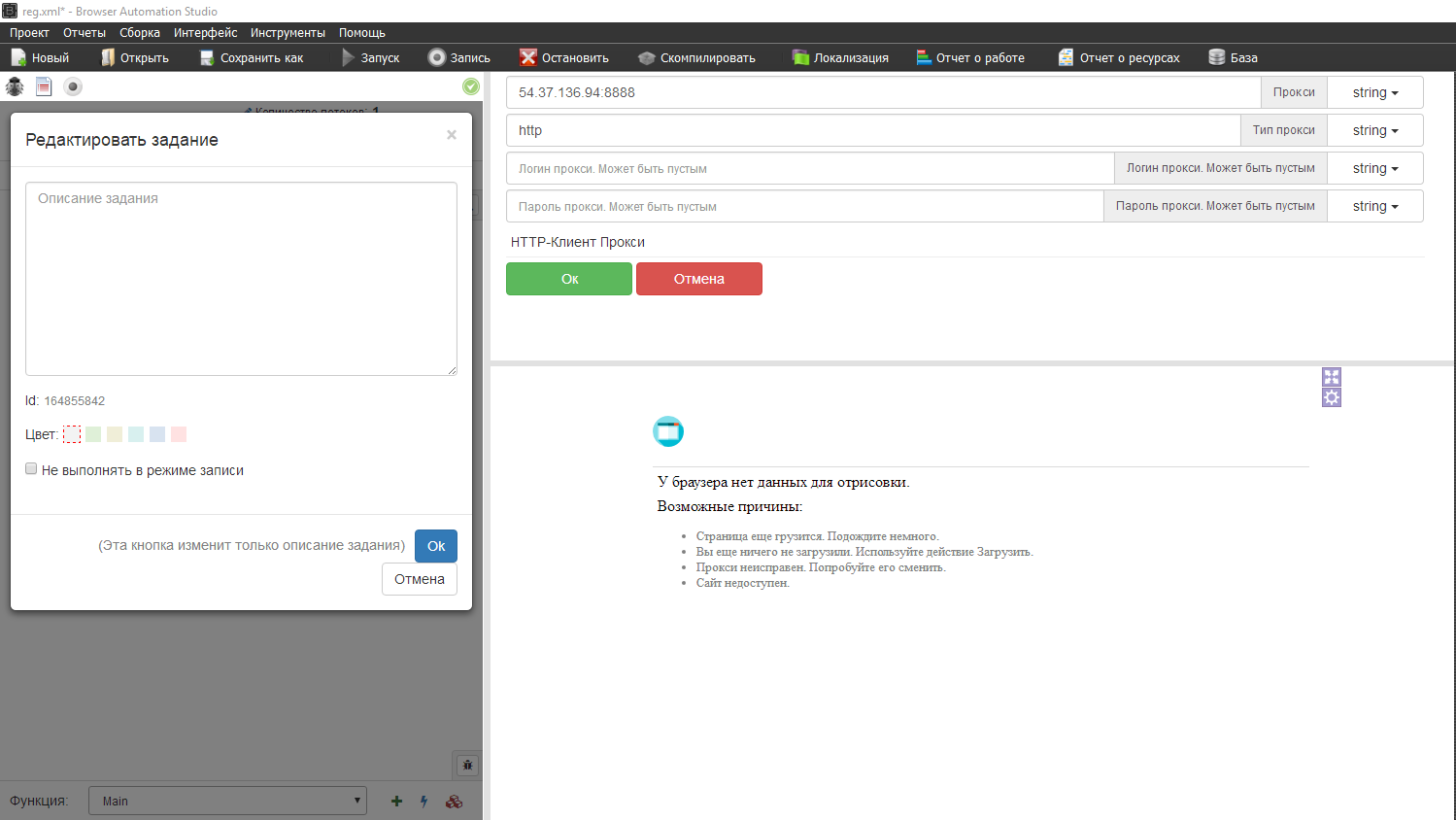
Переходим к пост запросу, все переменные готовы. Копируем со снифера юрл и тело запроса и подставляем наши переменные
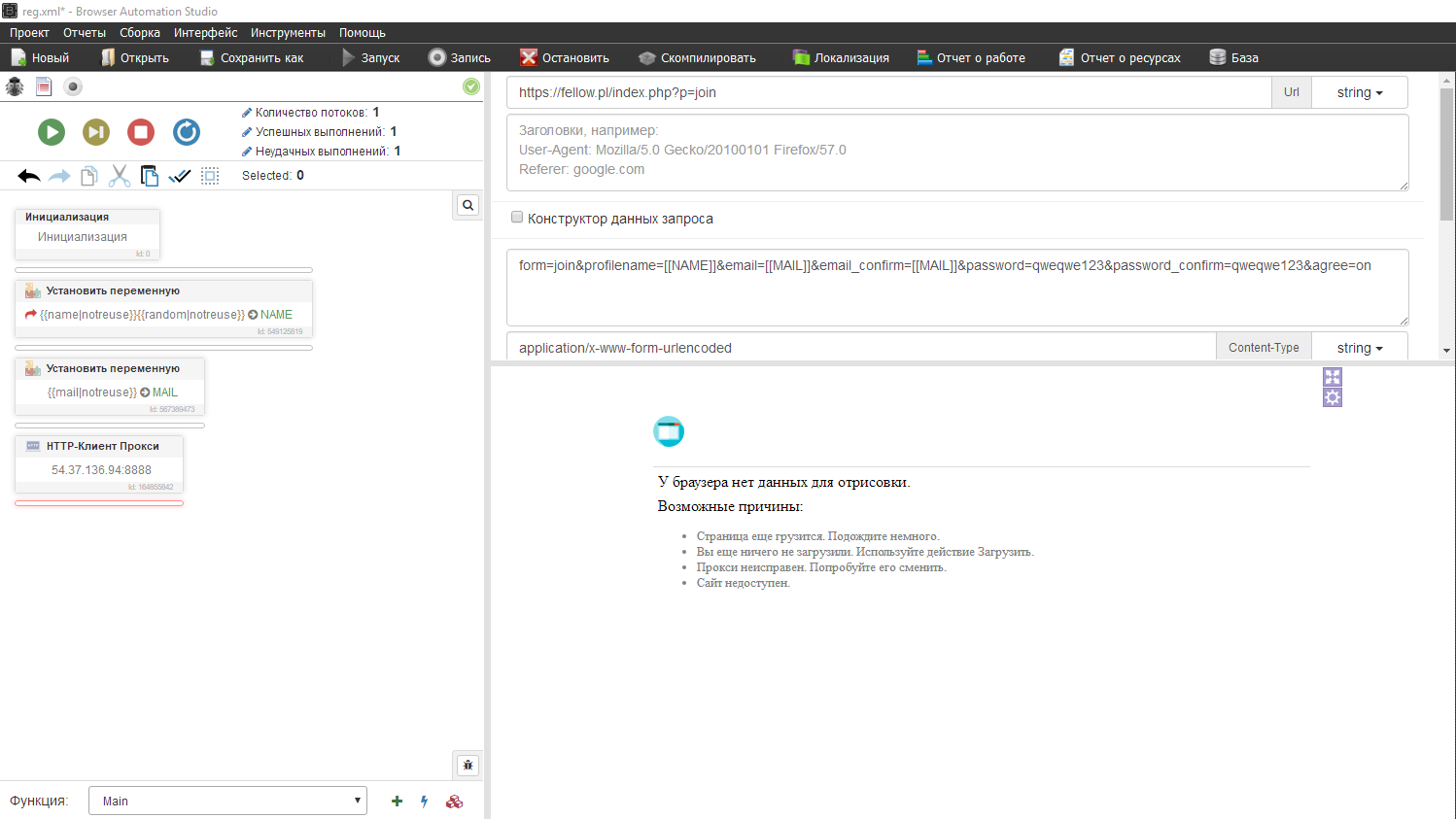
Нажимаем ок и смотрим результат отработки запроса в анализе трафика статус 200 уже хорошо(рекомендую прогуглить статусы ответов, что бы не писать типа "ой 302 ошибка" и т.д.).
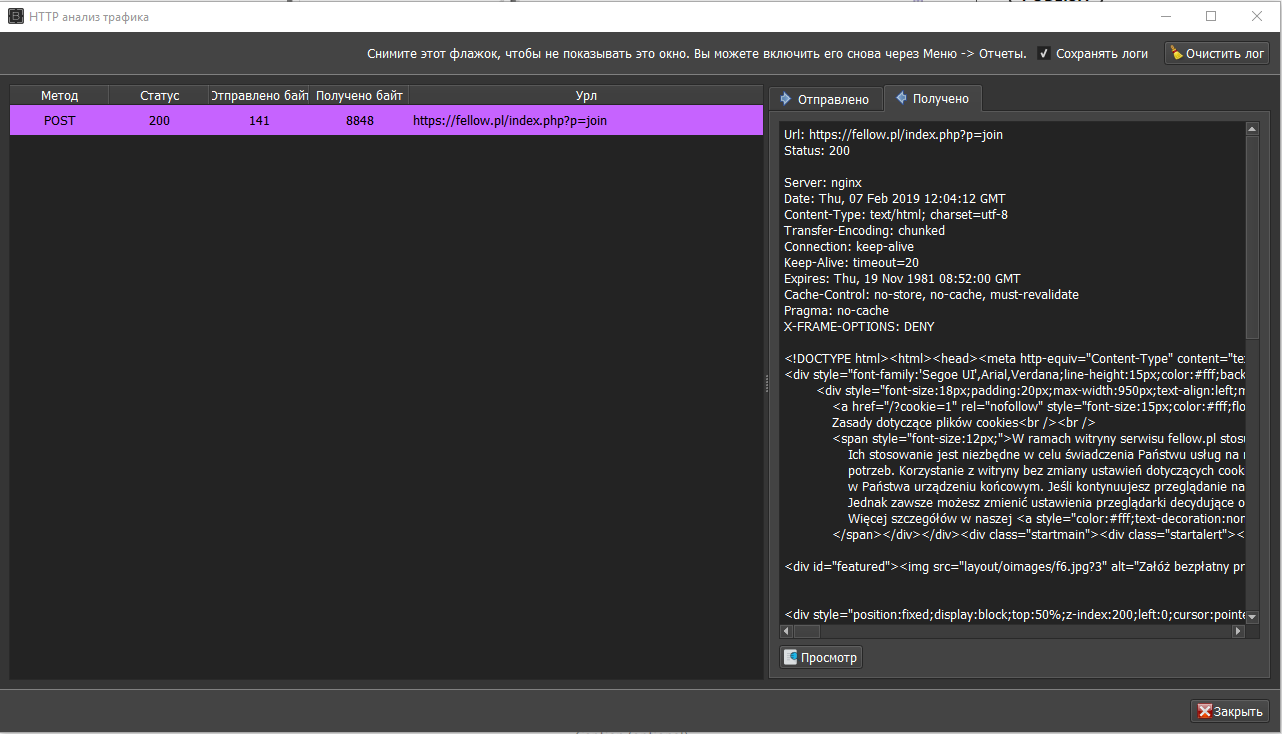
Нужно убедится что запрос отработал правильно, открываем результат в браузере через кнопку Просмотр
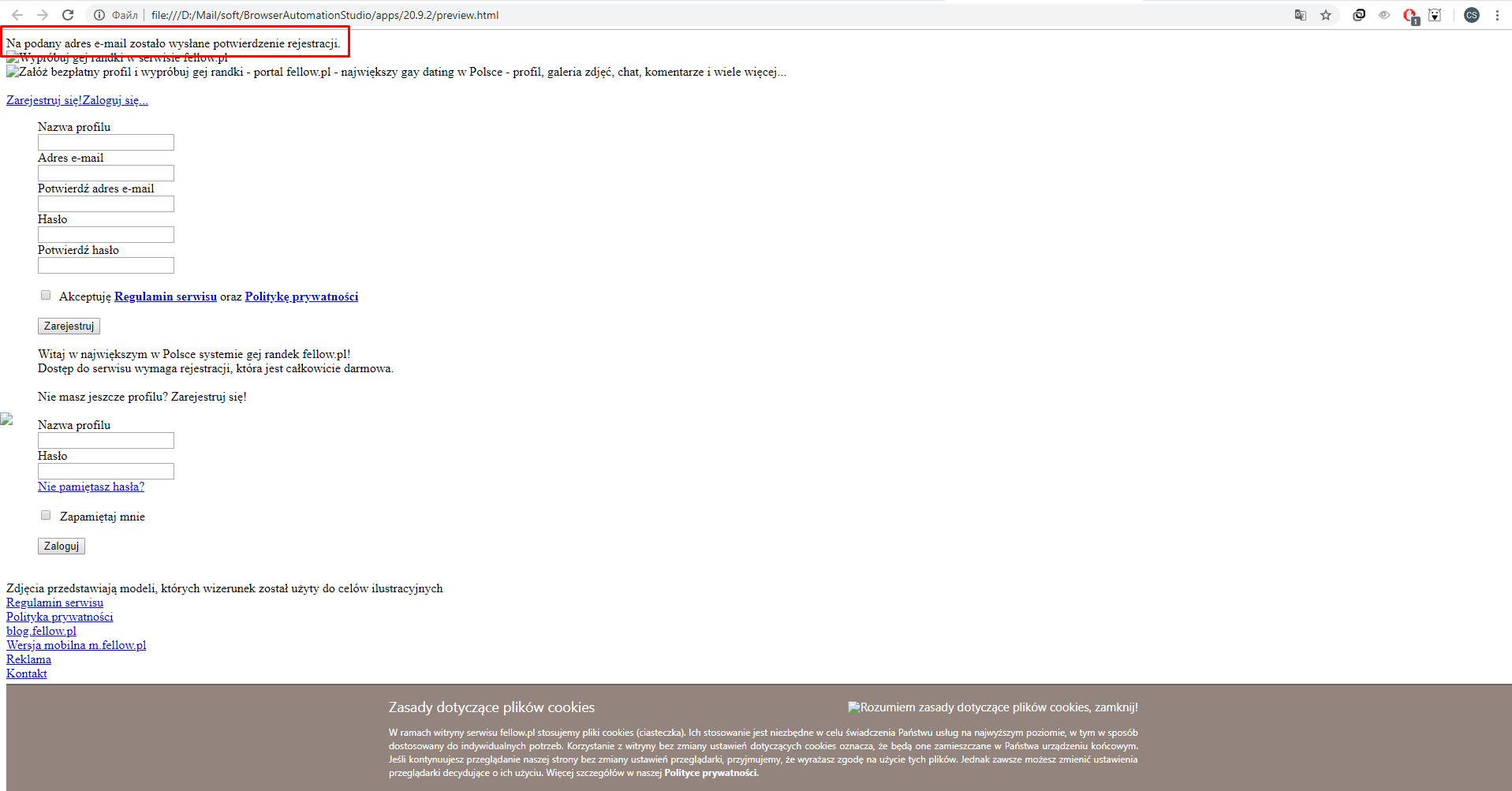
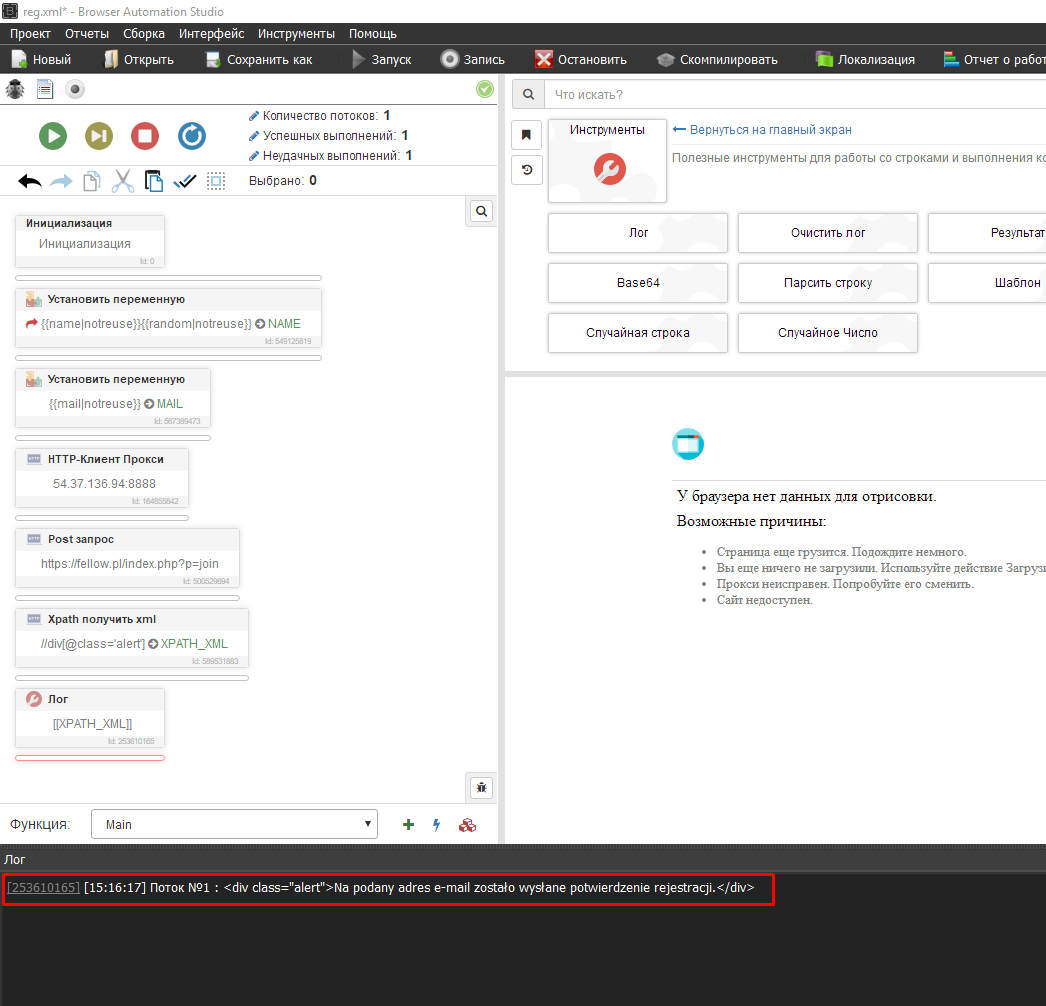
Видим что на почту отправленно письмо подтверждения, теперь давайте выведем этот кусочек в лог что бы можно было следить за работой скрипта и увидеть ошибку.(Так же советую делать вообще со всем, статус ответа не всегда дает понять отработал ли запрос правильно, лучше смотреть по содержанию и всегда выводить в лог)
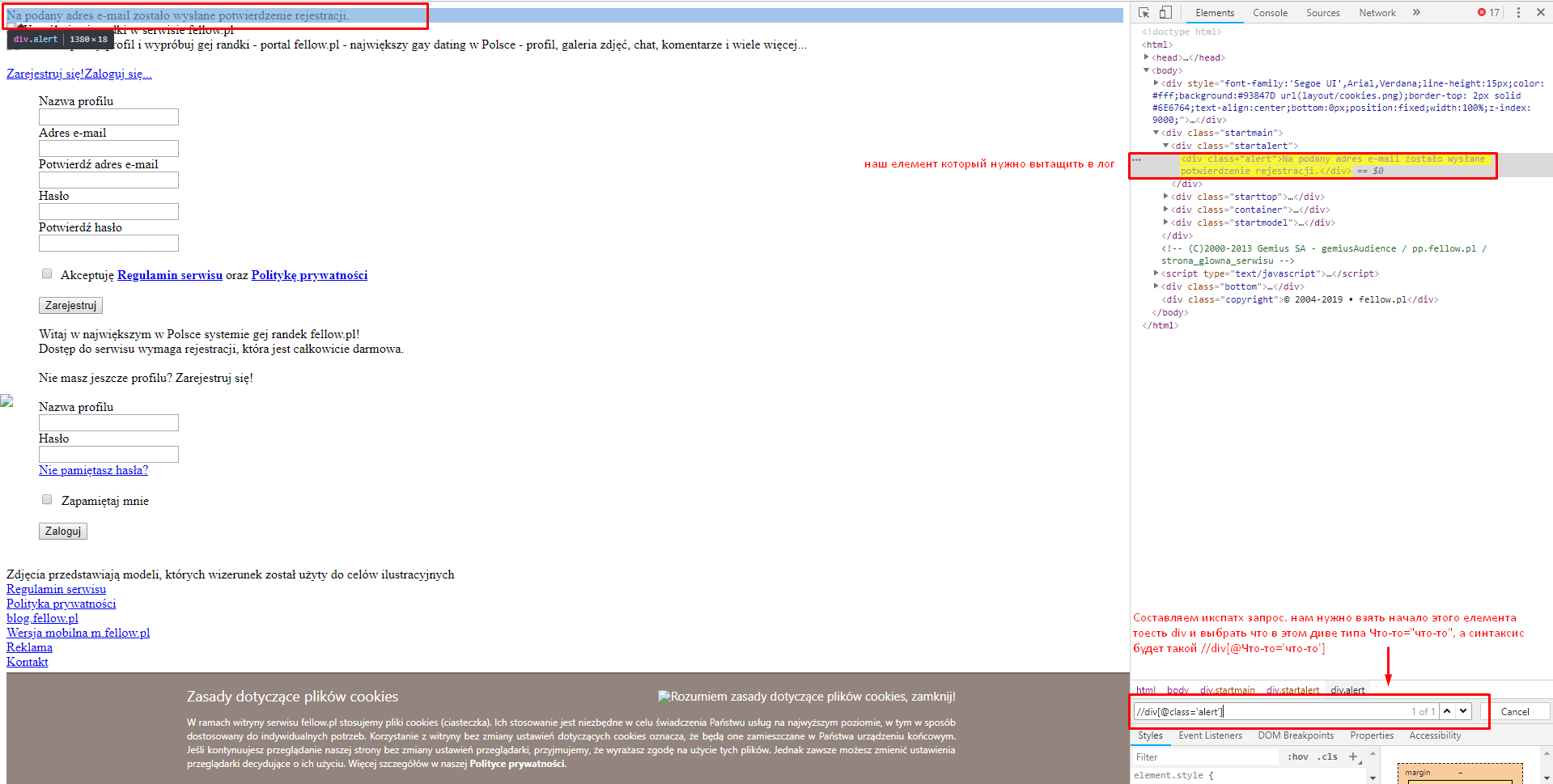
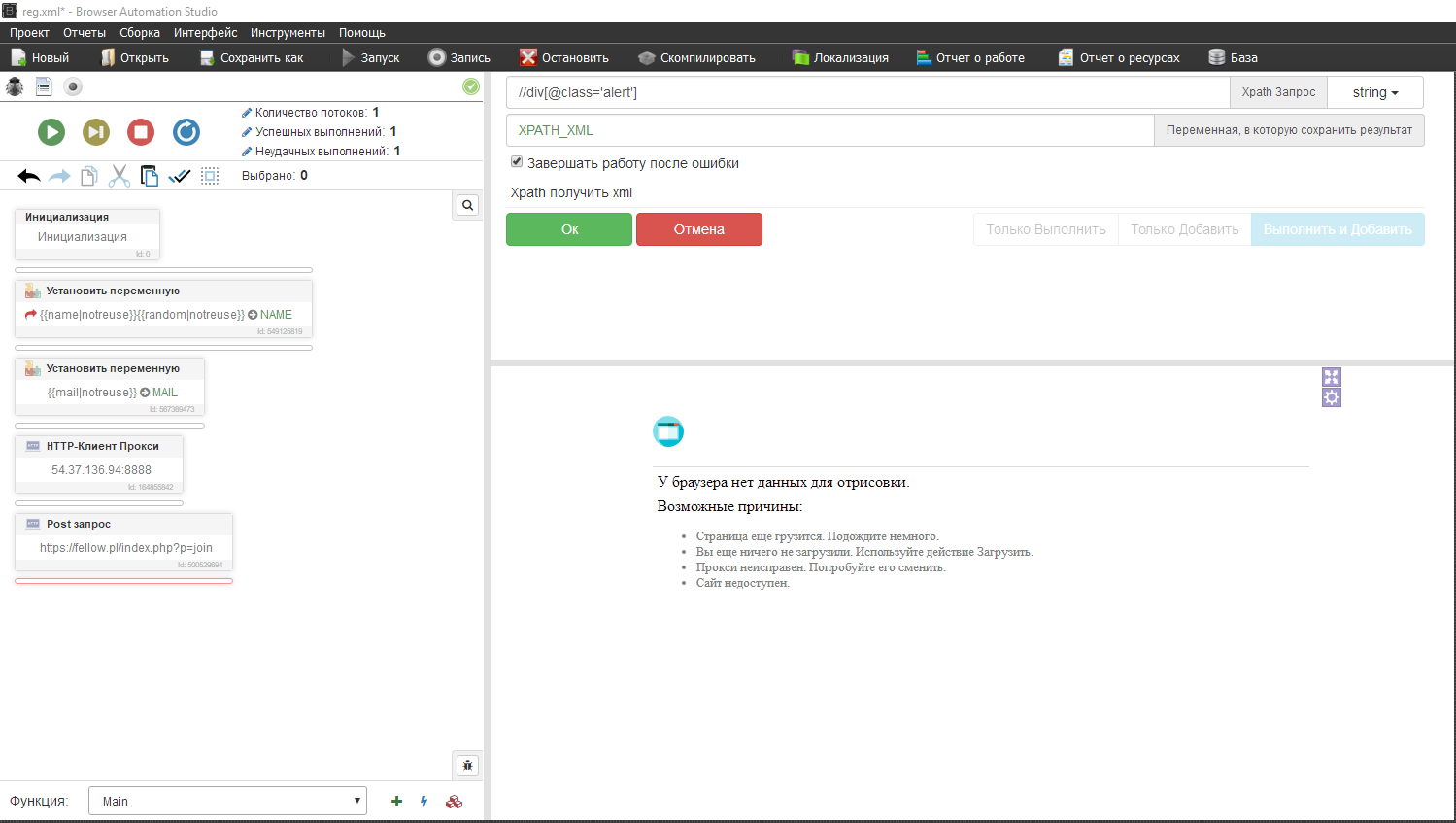
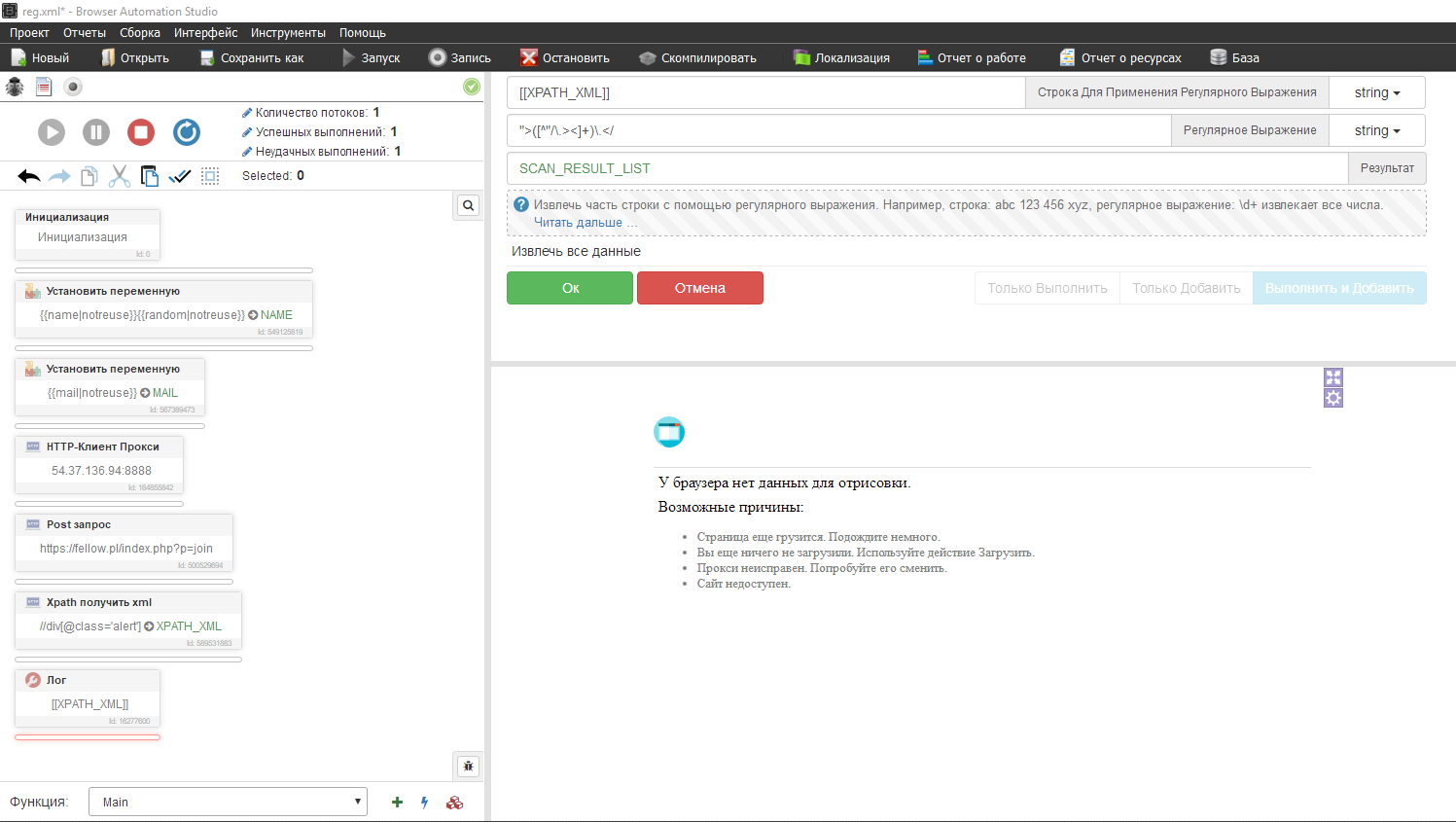
Вставляем в бас этот икспатх запрос. Xpath - получить xml
Осталось вывести это дело в лог, вставляем переменную XPATH_XML
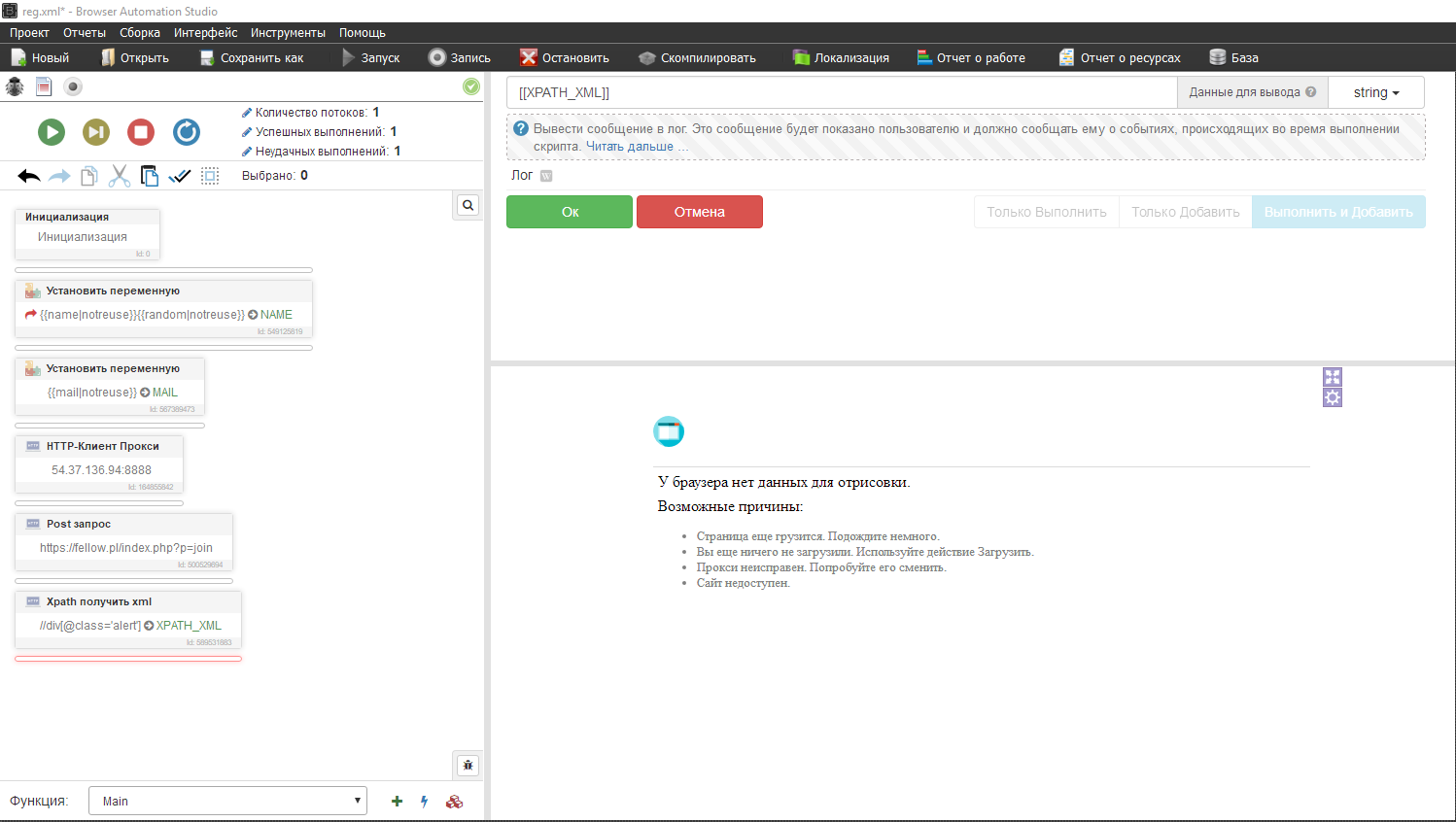
Получилось вот такое
Не красиво, давайте сделаем что бы выводило только текст, обращаемся к регулярным выражениям, в басе есть конструктор, открываем его, нажимаем создать регулярное выражение и вставляем туда нужный нам текст и какие-то символы которые его обрамляют типа ">.</
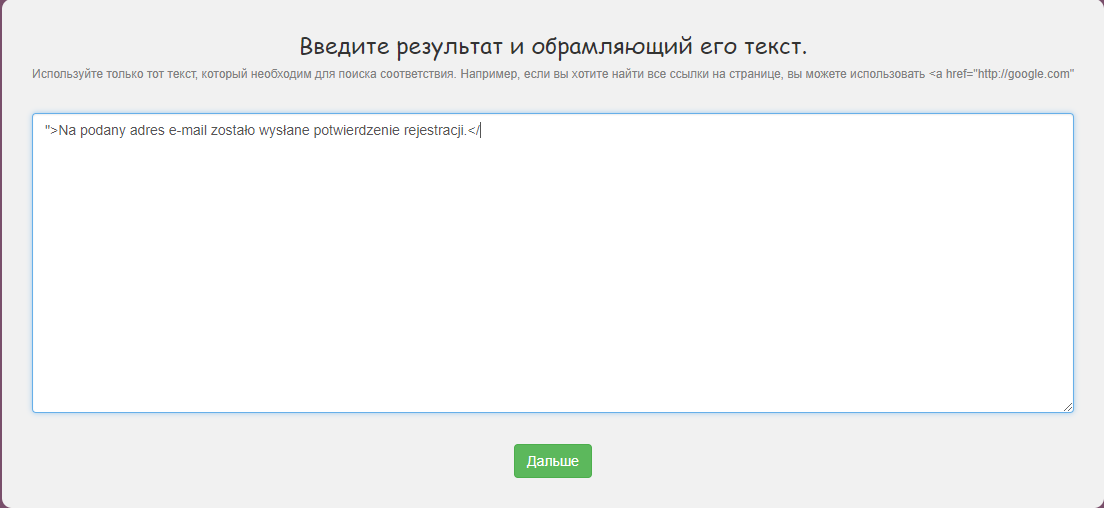
Жмем дальше и выделяем наш результат, а это текст

Дальше кликаем дважды на каждый символ который не входит в наш результат он встречается один раз, точный текст будет автоматом вписан этот символ, ничего не меняем и нажимаем принять
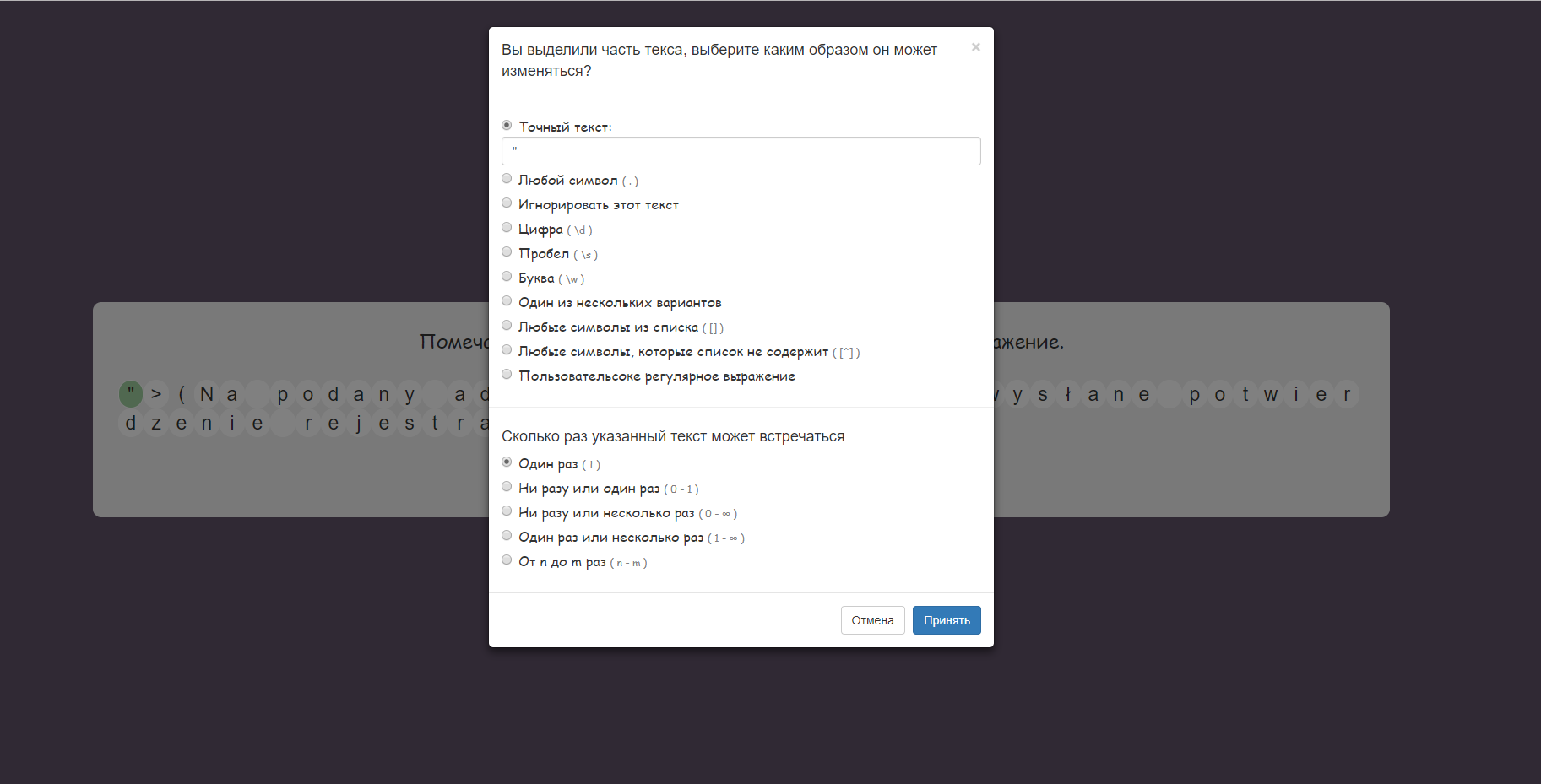
Проделываем это с каждым символом

Остался результат, выделяем его полностью, текст встречается "Один раз или несколько раз" и это "Любые символы которые список не содержит" в этом поле мы вписаваем символы которые выделяли до этого, которые встречаются только один раз. Нажимаем принять и дальше
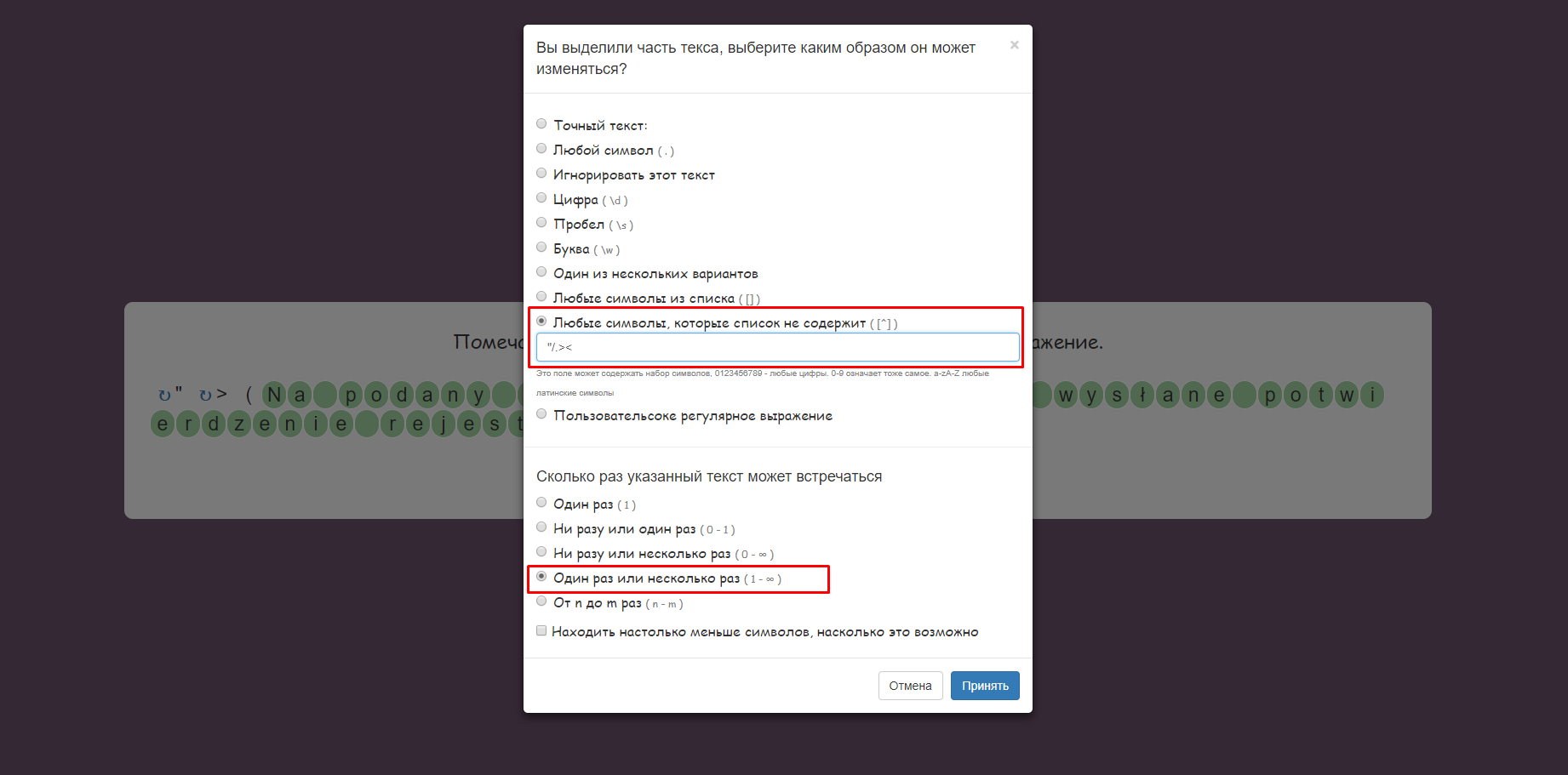
Появляется окно проверки нашей регулярки, давайте проверим, копируем текст из прошлого лога и вставляем его и снизу получаем результат
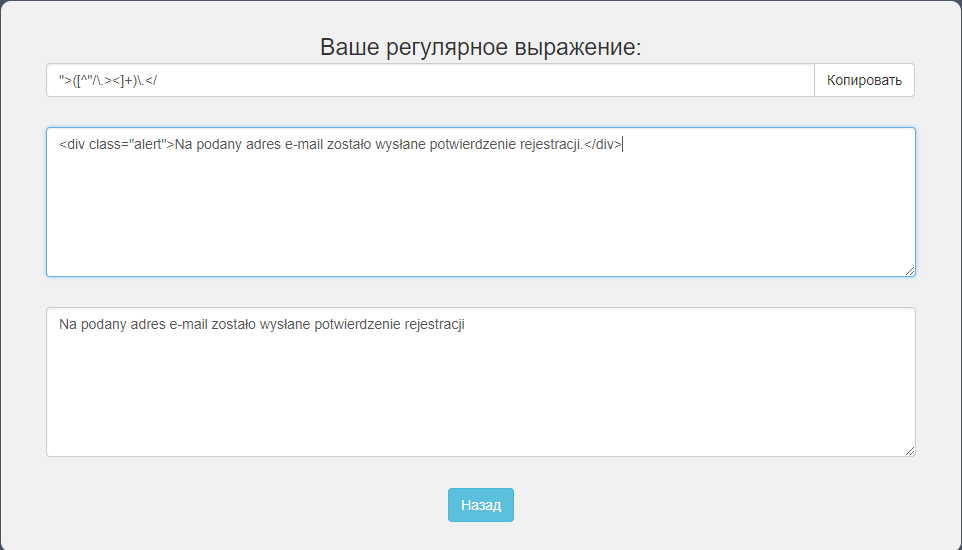
Копируем регулярку и вставляем в бас. Регулярные выражения извлечь все данные. Строка для применения регулярного выражения это то откуда мы будем парсить что либо, в нашем случае это переменная XPATH_XML, плюс копируем само выражение
И так же выводим в лог, только уже переменную SCAN_RESULT_LIST
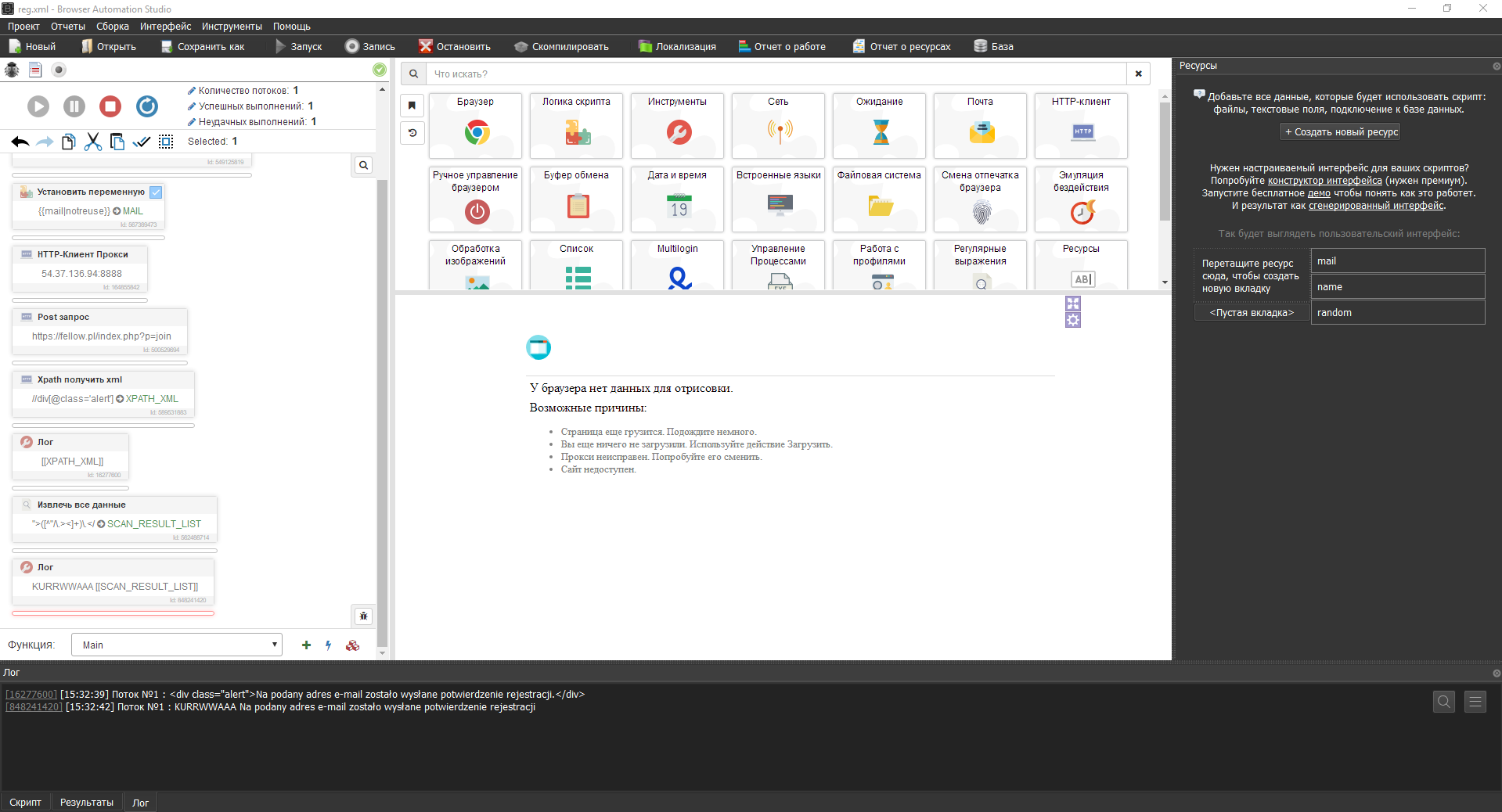
Выставляем нужное количество потоков, успешных/неуспешных выполнений и запускаем шаб.
Затронул xpath и регулярные выражения тут сполна, с этой инфой можно уже и парсить токены и любые данные вообще, в парсере и спамере я больше уделю внимания логике построения шаблона.
Еще момент по регуляркам, если допустим есть "id"="1101029239" то мы выделяем результат 1101029239, символы которые обрамляют 1101029239 тоесть " и = кликаем и выбираем как "Встречаются только один раз", кусочек "id" выделяем и тоже выбираем "Встречается только один раз". 1101029239 выделяем, выбираем "Любые символы которые список не содержит", а вписываем туда =", встречается один раз или несколько раз. Поковыряйте конструктор и все получится очень быстро.