Reduce Mean Time to Resolution with an observability agent | Amazon Web Services
Data&AI Insights📖 Источник: aws.amazon.com
Сокращение среднего времени решения инцидентов с помощью агента наблюдаемости | Amazon Web Services
Статья посвящена использованию агента наблюдаемости, построенного на базе Amazon OpenSearch Service и Amazon Bedrock AgentCore, для автоматизации и ускорения расследования инцидентов в IT-инфраструктуре. Рассматривается архитектура решения, технические детали реализации, примеры работы агента на основе демонстрационного приложения OpenTelemetry, а также преимущества и результаты применения такого подхода для сокращения Mean Time to Resolution (MTTR). В статье подробно описываются механизмы сбора и анализа телеметрических данных, взаимодействие агента с разными типами сигналов (логи, трассировки, метрики), а также использование искусственного интеллекта для выявления корневых причин инцидентов и оценки бизнес-воздействия.
Архитектура решения и сбор телеметрии
Основой решения является архитектура, в которой приложения и инфраструктура генерируют телеметрические сигналы в виде логов, трассировок и метрик. Эти данные собираются с помощью OpenTelemetry Collector (шаг 1) и экспортируются в Amazon OpenSearch Ingestion через отдельные конвейеры для каждого типа сигнала:
- Логи: OpenSearch Data Prepper OTEL Logs Source
- Трассировки: OpenSearch Data Prepper OTEL Trace Source
- Метрики: OpenSearch Data Prepper OTEL Metrics Source
(шаг 2)
Данные доставляются в домен OpenSearch Service и Amazon Managed Service for Prometheus (шаг 3).
OpenTelemetry выступает стандартом для инструментирования, обеспечивая независимый от вендора сбор данных для множества языков и фреймворков. Такая архитектура позволяет избежать зависимости от конкретных поставщиков, использовать преимущества open source и применять решение как в облаке, так и в локальных средах.
Для демонстрации используется приложение OpenTelemetry Demo — ecommerce-платформа, состоящая из около 20 микросервисов, генерирующая реалистичные телеметрические данные с нагрузкой и имитацией сбоев.
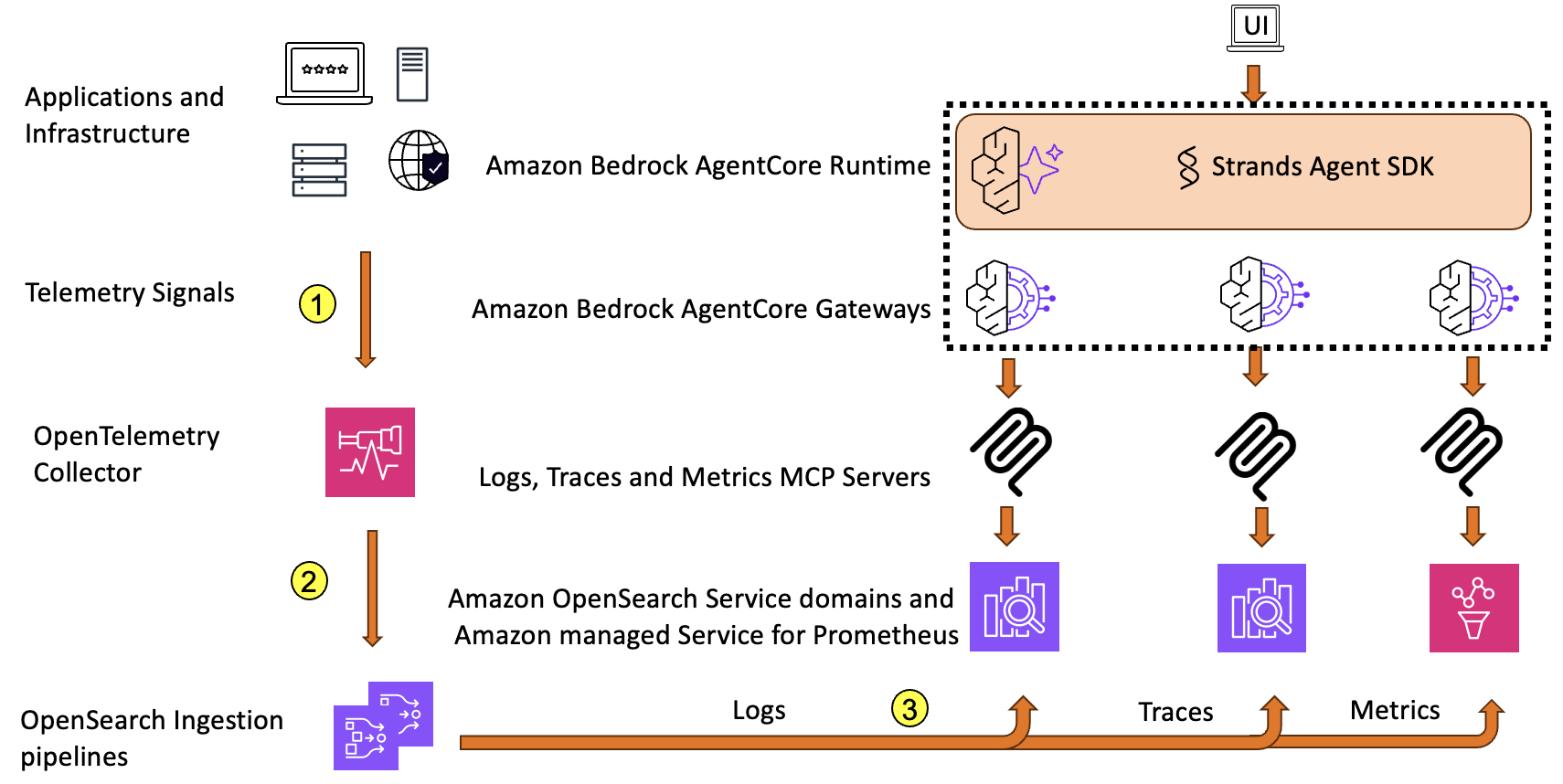
Протокол Model Context Protocol (MCP) и серверы сигналов наблюдаемости
Для подключения агента к внешним источникам данных и инструментам используется Model Context Protocol (MCP), предоставляющий стандартизированный интерфейс.
В решении реализованы три отдельных MCP-сервера для каждого типа телеметрических сигналов:
- Logs MCP сервер: предоставляет функции поиска, фильтрации и выбора логов, хранящихся в OpenSearch Service. Агент может выполнять запросы по ключевым словам, имени сервиса, уровню логов и временным диапазонам. Пример псевдокода функции поиска:
💻 Код (pseudo):
searchLogs(keyword, serviceName, logLevel, timeRange) -> filteredLogs
- Traces MCP сервер: предоставляет функции для поиска и получения информации о распределённых трассировках. Позволяет искать трассы по ID, получать спаны, карту сервисов, а также метрики RED (rate, errors, duration). Это помогает агенту отслеживать путь запроса через сервисы и выявлять места сбоев или задержек.
- Metrics MCP сервер: предоставляет функции для запроса временных рядов метрик. Агент использует их для проверки процентилей ошибок и использования ресурсов, что важно для оценки состояния системы и выявления аномалий.
Эти три MCP-сервера обеспечивают полный набор данных для автономного расследования инцидентов с корреляцией между логами, трассировками и метриками.
Дополнительно существует кастомный MCP-сервер для бизнес-данных (выручка, продажи и др.), который в демонстрационном приложении генерирует синтетические данные для оценки бизнес-воздействия, но в архитектуре не показан.
Наблюдательный агент: архитектура и функциональность
Центральным элементом решения является наблюдательный агент, предназначенный для помощи в расследовании инцидентов. В отличие от традиционных автоматизаций и ручных инструкций, агент не требует заранее заданных сценариев. Он анализирует и рассуждает на основе доступных данных, адаптируя стратегию по мере получения новой информации. Агент коррелирует данные из логов, трассировок и метрик для выявления корневой причины.
Агент построен с использованием Strands Agent SDK — open source фреймворка, упрощающего разработку ИИ-агентов. SDK реализует модельно-ориентированный подход, управляет оркестрацией и рассуждениями (agent loop), вызывая инструменты и поддерживая последовательное взаимодействие. Агент динамически обнаруживает доступные инструменты, что позволяет ему адаптироваться к изменениям функционала.
Агент работает на Amazon Bedrock AgentCore Runtime — полностью управляемой инфраструктуре для хостинга и запуска агентов. Runtime поддерживает популярные фреймворки, включая Strands, LangGraph и CrewAI, обеспечивает масштабируемость и вычислительные ресурсы для промышленного использования.
Для подключения к MCP-серверам используется Amazon Bedrock AgentCore Gateway, который упрощает управление, снижает необходимость в кастомной разработке, обеспечивает безопасность входящего и исходящего трафика, а также единый доступ. В данном решении создано несколько шлюзов, подключающих все три MCP-сервера через server-sent events (SSE).
Пример работы шлюзов с сервер-сент эвентами
Безопасность обеспечивается через Amazon Bedrock AgentCore Identities и AWS Identity and Access Management (IAM), что позволяет безопасно управлять учётными данными и передавать идентичность пользователя к взаимодействующим компонентам.
Расследование инцидентов — итеративный процесс с множеством циклов гипотез, запросов и анализа. Для поддержки этого используется Amazon Bedrock AgentCore Memory с сессионными пространствами имён, позволяющими хранить отдельные ветки диалогов для разных расследований. Агент сохраняет вопросы пользователя и свои ответы с временными метками, что помогает восстанавливать контекст и логику рассуждений.
Для логики рассуждений агент использует модель Anthropic Claude Sonnet v4.5, запущенную в Amazon Bedrock. Модель интерпретирует вопросы, выбирает MCP-инструменты для вызова, анализирует результаты и формулирует выводы и последующие вопросы. Система настроена с промптом, который задаёт поведение модели как опытного SRE или инженера операционного центра:
> «Начинайте с проверки на высоком уровне, сужайте круг затронутых компонентов, коррелируйте данные разных типов сигналов и делайте выводы с обоснованием. Также предлагайте логичные следующие шаги, например, углублённое исследование межсервисных зависимостей.»
Это обеспечивает универсальность агента для анализа типичных сценариев расследования инцидентов.
Демонстрация работы агента наблюдаемости
Для визуализации состояния приложения создана панель RED-метрик (rate, errors, duration) в реальном времени, охватывающая все микросервисы.
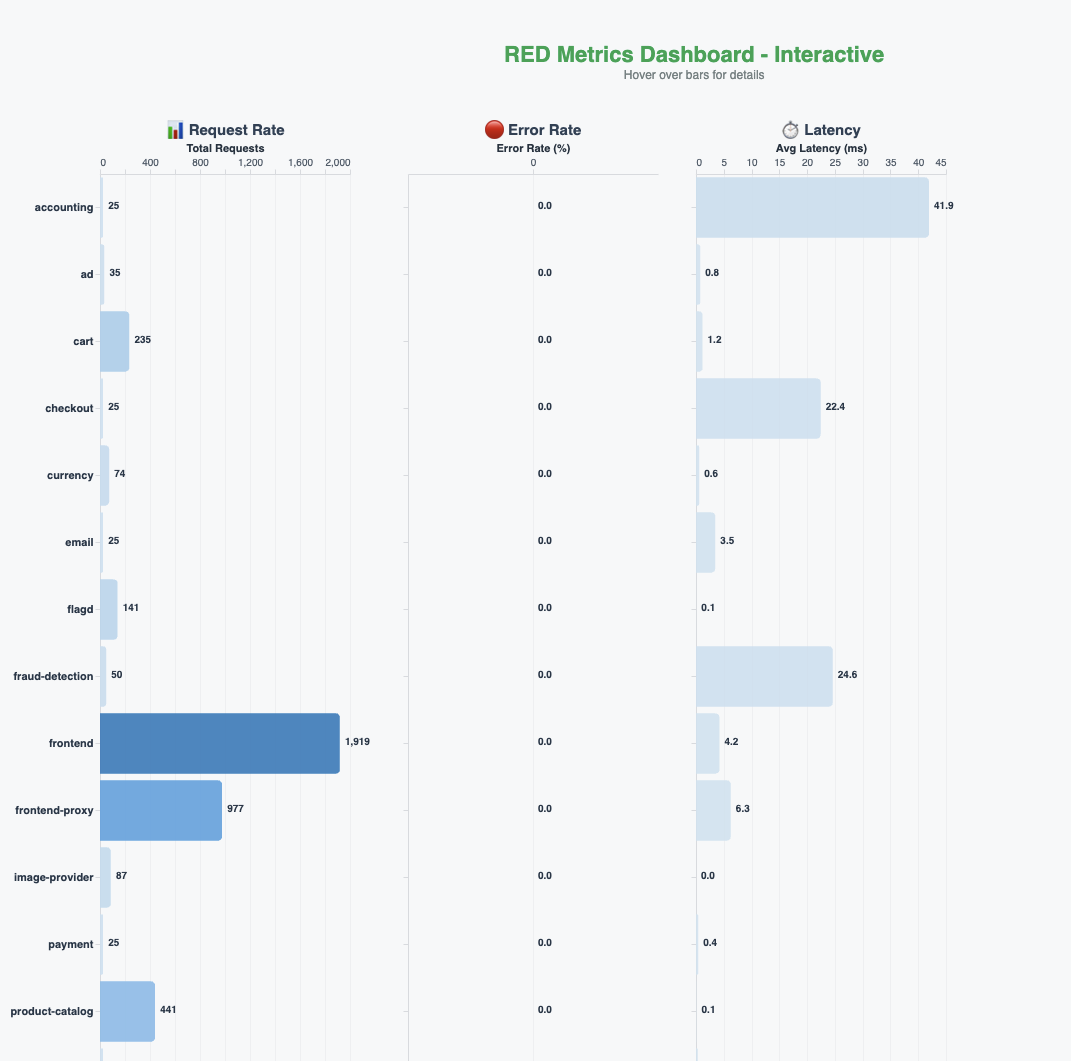
Установка базового уровня
В качестве начального запроса агенту задан вопрос: «Есть ли ошибки в моём приложении за последние пять минут?» Агент выполняет запросы к трассировкам и метрикам, анализирует результаты и отвечает, что ошибок нет, все сервисы активны, трассы здоровы, система обрабатывает запросы нормально. Агент также предлагает возможные следующие шаги для углублённого анализа.
Введение сбоев
В демонстрационном приложении OpenTelemetry Demo реализована возможность включения искусственных сбоев через feature flag, а также генерация нагрузки для проявления ошибок. В статье приводится пример сбоев в сервисе оплаты (payment service), что приводит к росту ошибок, отображаемому на панели RED-метрик.
Расследование и анализ корневой причины
После появления ошибок начинается сессия расследования. В реальных условиях её инициируют срабатывания алертов или вызовы на пейджинг.
Пользователь задаёт вопрос: «Пользователи жалуются, что долго покупают товары. Можешь проверить, что происходит?» Агент извлекает историю диалога из памяти, вызывает инструменты для запроса RED-метрик по сервисам и анализирует данные.
Результат: выявлена критическая проблема с производительностью в процессе покупки — сервис оплаты находится в состоянии сетевого кризиса и полностью недоступен, при этом наблюдается экстремальная задержка в сервисах fraud detection, ad service и recommendation service.
Агент рекомендует немедленно восстановить подключение к сервису оплаты и предлагает следующие шаги — исследовать логи сервиса оплаты.
Далее пользователь запрашивает: «Исследуй логи сервиса оплаты, чтобы понять проблему с подключением.» Агент выполняет поиск в логах сервисов checkout и payment, коррелирует их с трассировками и анализирует зависимости сервисов на карте. Подтверждается, что сервисы cart, product catalog и currency работают нормально, а сервис оплаты недоступен, что и является корневой причиной сбоя.
Анализ бизнес-воздействия
Используя отдельный MCP-сервер с синтетическими бизнес-данными (выручка, продажи), агент отвечает на запрос: «Проанализируй бизнес-воздействие сбоев в checkout и payment сервисах.» Агент изучает транзакционные данные из трассировок, рассчитывает предполагаемый ущерб по выручке и оценивает уровень отказа клиентов из-за сбоев на этапе оформления заказа.
Таким образом, агент выходит за рамки технического анализа, помогая с операционными задачами, например, созданием инструкций по устранению проблем (runbook), что является первым шагом к автоматическому восстановлению без участия SRE.
Преимущества и результаты применения агента
Хотя сценарий сбоев в статье упрощён для демонстрации, он подчёркивает ключевые преимущества, способствующие снижению MTTR.
Ускорение циклов расследования
Традиционные методы требуют многократных итераций гипотез, проверок, запросов и анализа, что занимает часы и требует переключения контекста. Агент сокращает эти процессы до нескольких минут за счёт автономного рассуждения, корреляции данных и выполнения действий.
Обработка сложных сценариев
В реальных условиях часто возникают каскадные и множественные сбои. Агент способен работать с историческими данными и распознаванием паттернов, отличая связанные проблемы от ложных срабатываний с помощью временной и идентификационной корреляции, графов зависимостей и других методов.
Вместо единственного ответа агент может выдавать вероятностное распределение по возможным причинам, помогая SRE расставлять приоритеты в устранении:
- Проблема с сетевым подключением сервиса оплаты: 75%
- Таймаут downstream платежного шлюза: 15%
- Истощение пула соединений базы данных: 8%
- Другое/неизвестно: 2%
Агент сравнивает текущие симптомы с прошлыми инцидентами, выявляя повторяющиеся паттерны, что позволяет перейти от реактивного инструмента к проактивному диагностическому помощнику.
Заключение
Расследование инцидентов остаётся преимущественно ручным процессом, требующим от SRE одновременной работы с множеством дашбордов, написания запросов и корреляции сигналов под давлением времени, даже при наличии всех данных. В статье показано, как агент наблюдаемости, построенный на Amazon Bedrock AgentCore и OpenSearch Service, снижает когнитивную нагрузку, автономно запрашивая логи, трассировки и метрики, коррелируя результаты и ускоряя поиск корневой причины.
Гибкость Amazon Bedrock AgentCore в сочетании с возможностями поиска и аналитики OpenSearch Service позволяет создавать и развёртывать агентов с разным уровнем автономии и фокусом на различные этапы жизненного цикла инцидента, адаптируя решения под уникальные операционные потребности организаций.
Agentic AI не заменяет существующие инвестиции в наблюдаемость, а усиливает их, предоставляя эффективный способ использования данных для ускорения расследований и повышения надёжности систем.
📢 Информация предоставлена телеграм-каналом: Data&AI Insights
🤖 Data&AI Insights - Ваш источник инсайтов о данных и ИИ