Организация компонентов в Jetpack Compose
Askhar AydarovВ Jetpack Compose очень неплохая идея слотов, о которой довольно много пишут и писали пару лет назад и которая позволят делать простые и расширяемые компоненты, не ограничивая разработчиков в том, какой контент и как они могут отрисовать в слотах.
Для примера вот две функции с ограничениями и без них.

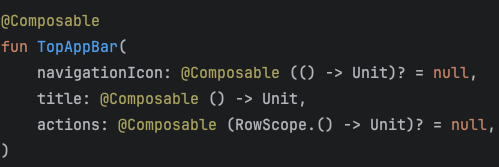
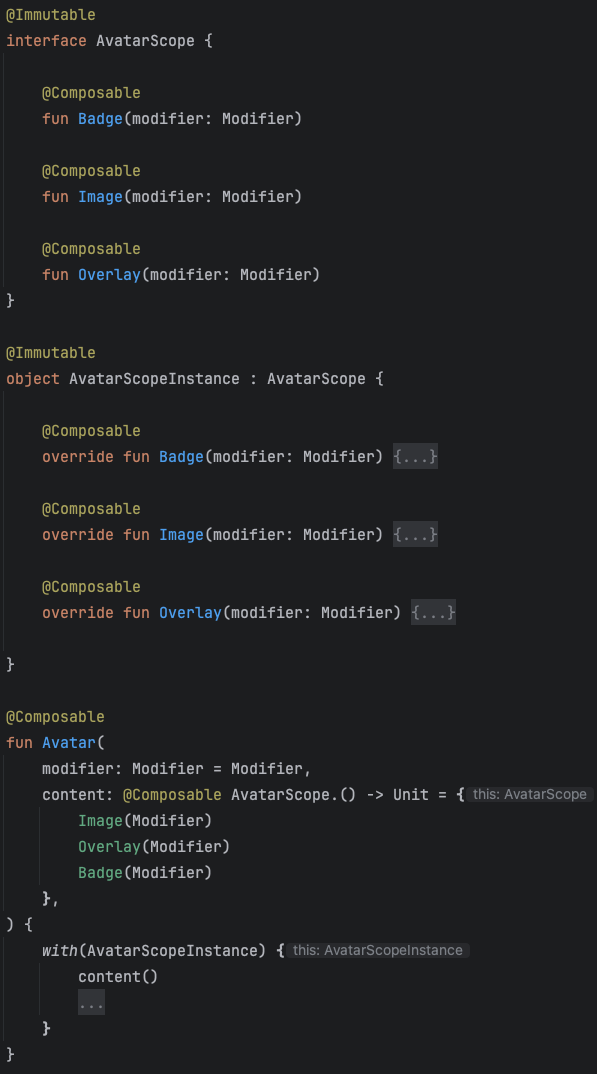
Но такой подход с неограниченными слотами чаще всего подойдёт для foundation компонентов, которые довольно простые и атомарные как Text, TabRow, Button и так далее. Но если у вас есть своя дизайн-система, то появляются компоненты посложнее, которые дизайнеры трактуют как единый и настраиваемый компонент. Например, вот такой компонент аватара с разными состояниями border, overlay, badge и top badge.
Причем badge довольно нестандартно расположен. Пересекается не его центр, а верхняя часть - дизайнерские фичи :)
В таких компонентах неограниченные слоты не сработают. Почему? Есть несколько проблем:
1) Неочевидность
Мы можем сделать заготовки под конкретные слоты в виде отдельных функции, но как потом разработчики найдут их и не будут делать свои?
2) Сложность
Пару абзацев назад писал, что все просто, расширяемо, а тут какая то сложность. На самом деле я про случаи, когда нужно в зависимости от контента и от его данных определять логику отрисовки слота. Да, в Compose есть ParentDataModifier, но эта такая страшная реализация, что даже не хочется никогда его трогать. Кроме этого, если реализация будет на плечах разработчика, то зачем нужен общий компонент?
3) Ограничения
А именно их отсутствие. Дизайн система обычно предполагает, что в конкретном слоте возможны конкретные компоненты. Мы не можем наложить ограничения на слоты в Compose при реализации, когда принимается просто @Composable функция. Разработчик может прокинуть что угодно, даже если это не соотносится с дизайном. Не, не подумайте, я не про то, что надо всем запрещать все, а про то, что ограничения должны задавать структуру, которая будет понятна разработчикам и они смогут легко расширить компонент, если это требуется и это расширение будет доступно всем.
В разное время использовал разные решения. И по большей части это вкусовщина и тема может стать холиварной :) Но я попробую разобрать плюсы и минусы разных вариантов организации компонентов, а так же рассказать о том, к чему в итоге пришел сам.
1. Убрать слоты
Да, такой вариант иногда уместен, когда компонент настраивается через параметры функции. Но параметров может быть очень много и расширение предполагает добавление или изменение параметра и его поддержку в компоненте. Чаще всего у людей стоят линтеры на количество параметров функции, поэтому все схлопывается в data class, который становится конфигурацией компонента.
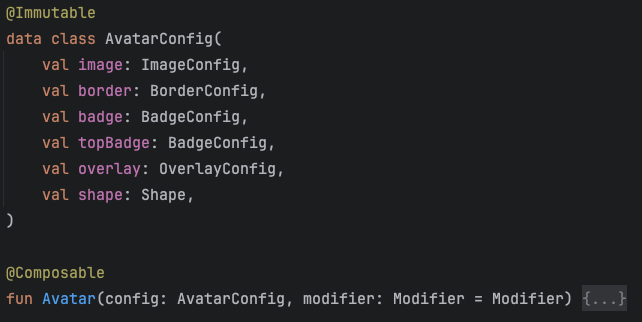
Какие минусы?
- Компонент в курсе всех своих состояний. Любое изменение/расширение предполагает изменения в основном компоненте
- Лишние рекомпозиции. Да, их можно избежать, если достаточно декомпозировать функцию компонента
2. Сделать scoped @Composable функции
По аналогии, как это сделано в Row-RowScope, Column-ColumnScope и так далее.
Это скорее не ограничение, а просто рекомендация разработчикам о том, какие слоты следует использовать.
Какие минусы?
- Разработчик может не следовать рекомендациям. Несмотря на то, что мы в рамках скоупа, это все ещё контекст
@Composableфункции, а значит можно прописать что-то другое - Сложность передачи каких-либо данные от контента в слотах компоненту. Опять через
ParentDataModifier, но его как минимум можно будет прикрыть через функции в рамках скоупа.
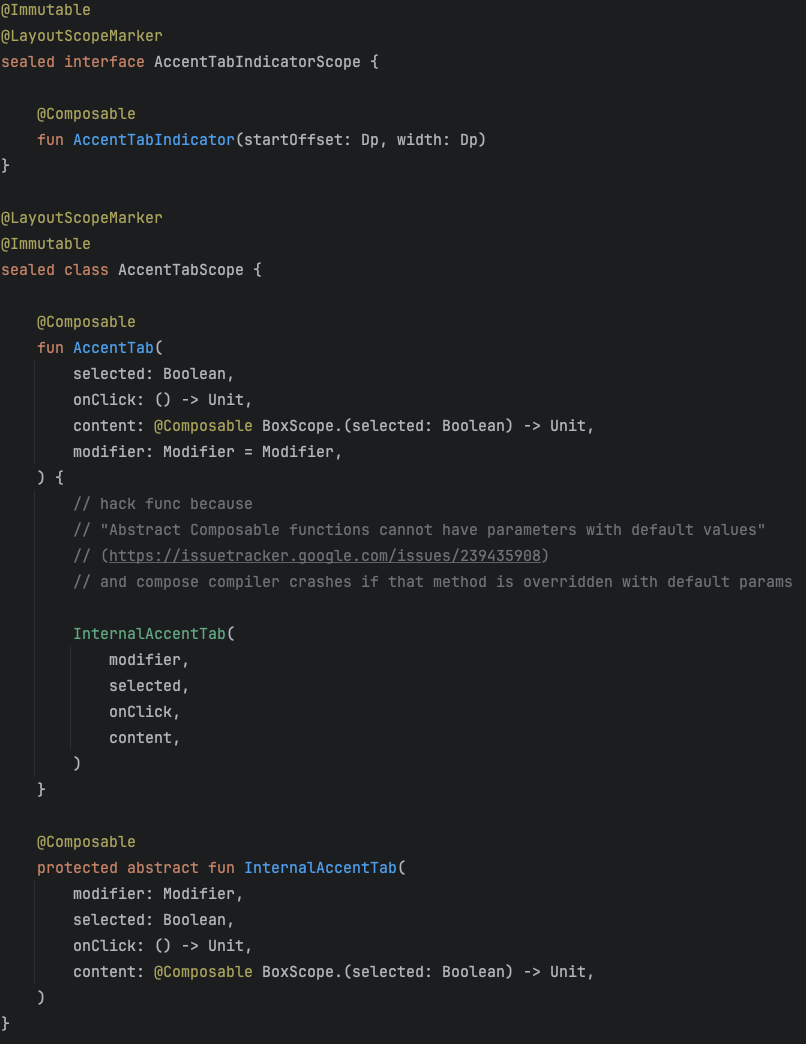
Несмотря на минусы, я такой подход оставил в компонентах, которые должны отрисовывать неограниченное количество слотов. Например, есть кастомный TabRow - AccentTabRow. В котором можно прописать в слоте AccentTab функцию и AccentTabIndicator. Для SecondaryTabRow - SecondaryTab, SecondaryTabIndicator. Но такой подход не очень подойдёт, если у нас сильнее ограничения на слоты.

3. Оборачиваем в классы, объекты или интерфейсы.
Подход не новый. Думаю, что каждый в попытках сделать хорошую структуру применял этот подход в навигации. Когда есть некий class/object ScreenContentA/B, в котором содержится @Composable функция.
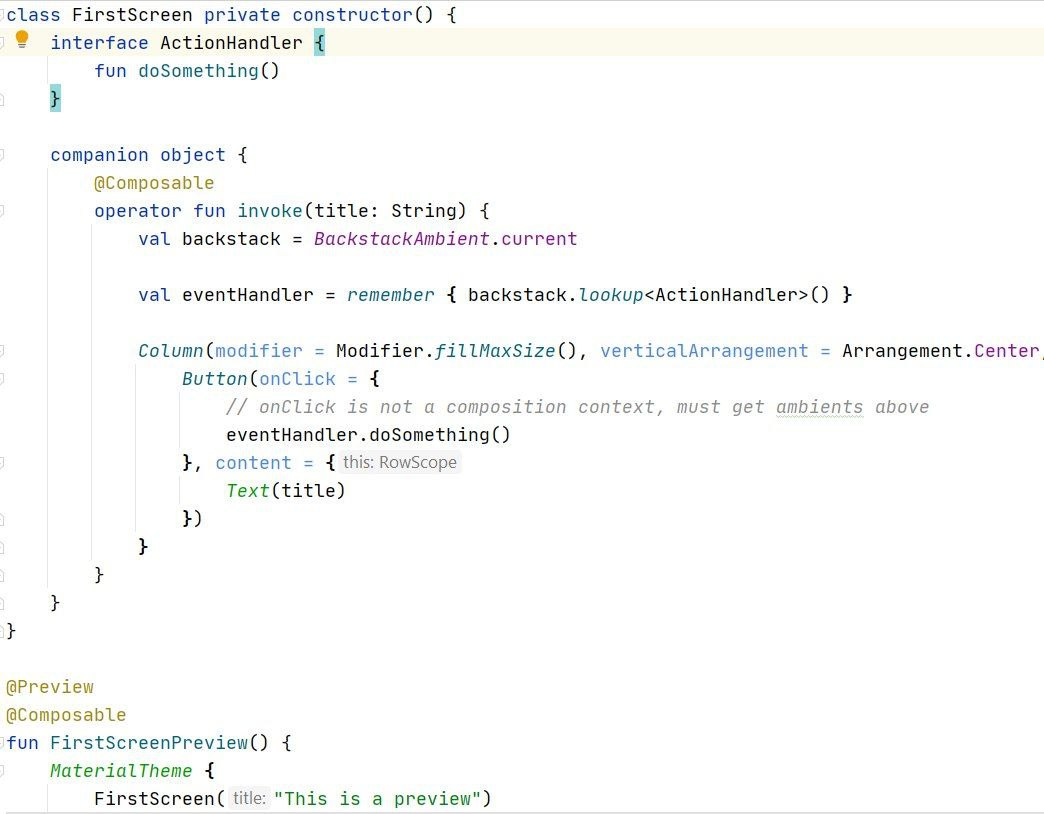
Чуть позже я наткнулся на похожий подход для компонентов после того, как написал этот текст, но там решается только проблема организаций функции.
В перспективе компонентов слотом будет какой-либо интерфейс, а разработчики будут подкладывать разные его реализации вместо @Composable лямбды как в варианте со скоупами.
Какие плюсы?
- Первый плюс заключается в том, что в интерфейсах мы можем прописать любой необходимый контракт, который разработчик должен будет реализовать и который можно будет учитывать в функции родительского компонента.
- Второй плюс, что расширение не будет требовать каких-то дополнительных изменений в компоненте, так как реализация слотов содержится в отдельных классах.
Но есть и минус: аллокации классов. Вместо вызова функции мы создаём классы, которые могут повлечь за собой дополнительные рекомпозиции. Решение простое: можем оборачивать в remember и пересоздавать класс по необходимости, а некоторые реализации и вовсе сделать object.
4. Слот как State
В большинстве в @Composable функции мы передаём конкретные значения. Это вполне очевидный и нормальный подход, но есть ещё варианты для Chad, которые хотят точечных рекомпозиций и работы donut-hole skipping во всей красе - это передача лямбд или стабильных и неизмеяннымых оберток по типу State<*>. Достаточно статей с примерами как это здорово может улучшить картину с рекомпозициями(тык и тык2). Но при этом, как по мне, такой подход ухудшает api функции, делая его менее декларативным что-ли. И все же давайте разберемся как это работает и как это применить без вреда для api.
Например есть такая бесполезная функция, которая получает State в аргументах и обновляет значение в нем, и такая же функция, которая вызывает первую
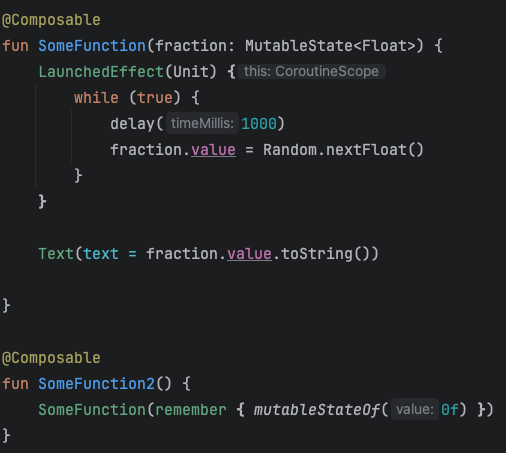
MutableStateпомечен аннотацией@Stable, а значит функция не будет лишний раз рекомпозироваться, если аргументы не поменяются- Вторая функция гарантирует, что State не поменяется
Как в таком случае Compose будет рекомпозировать первую функцию, если там читается, меняется и отображается значение.
Тут можно было многое рассказать, но есть уже несколько интересных докладов по этой теме:
- Алексей Панов: Что скрывает State в Compose
- Zach Klippenstein: Opening the shutter on snapshots
По моим ощущениям, Snapshot System - это, самая лапшевидная часть Compose Runtime, и без иллюстрации не рассказать в полной мере. Поэтому попробую в двух словах в контексте примера выше.
Дело в том, что Compose создает для каждой функции, которая может перезапускаться, restart group.
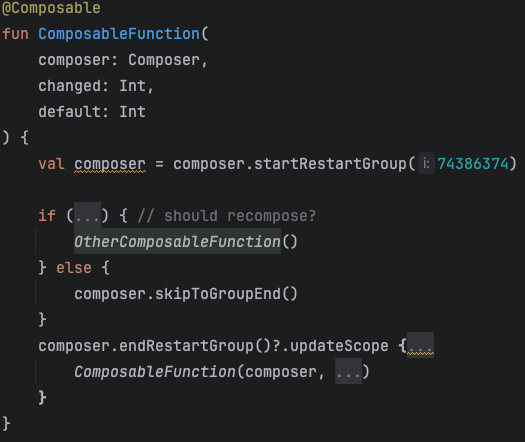
У этой группы имеется RecomposeScope, который учитывается при отслеживаниях изменений и чтений State.
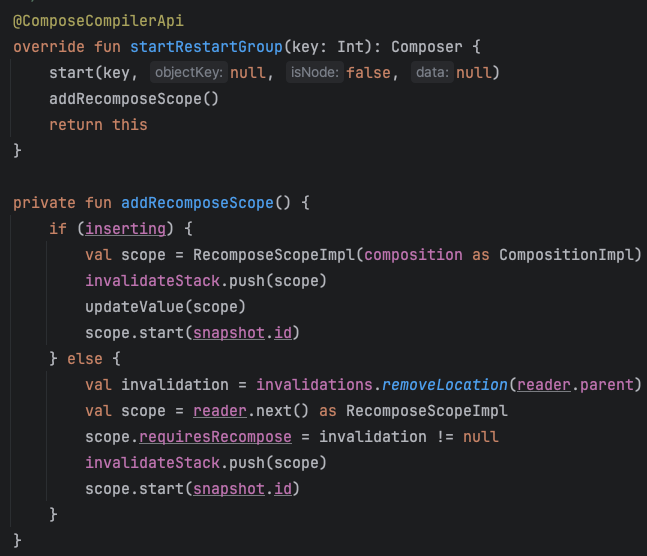
Далее вызовом composer.endRestartGroup вытаскивается этот скоуп и у него вызывается updateScope, который сохранит лямбду, которая должна будет вызвана в случае рекомпозиции
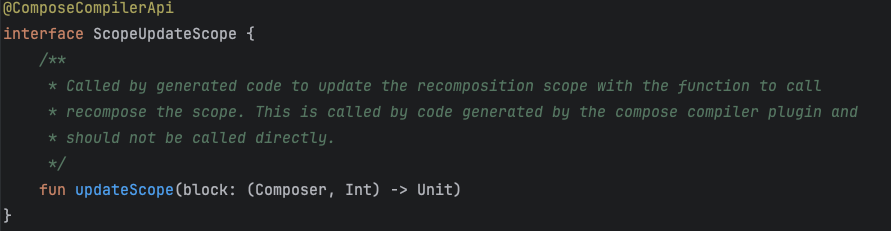
То есть Compose на самом деле в курсе в каком скоупе происходит чтение и запись, поэтому ведет список скоупов, которые нужно будет обновить, если их коснулось изменение State.
И так как он может просто взять и перезапустить конкретную функцию, то он так и делает.
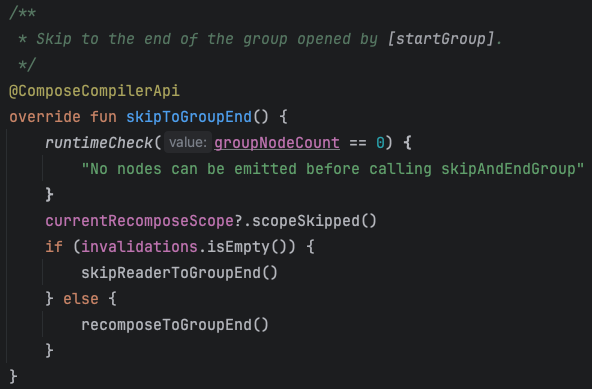
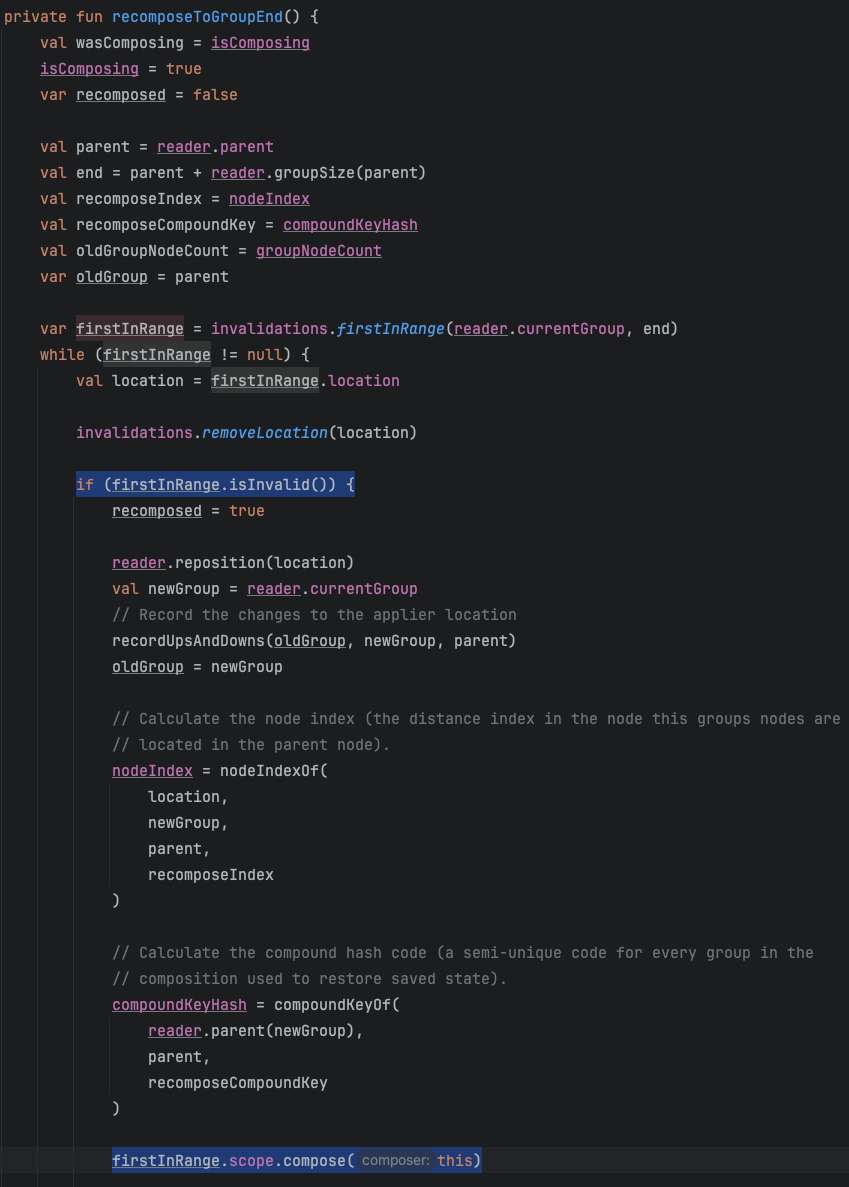
В функции skipToGroupEnd вызывается recomposeToGroupEnd,который ищет ближайший в списке скоуп, который нужно перезапустить. Находит, настраивает окружение (речь про значения composition locals) и перезапускает.
При этом может пропустить перезапуск функции выше по иерархии, так как их аргументы не поменялись, что как раз делает возможным штуку как donut-hole skipping.
Мы можем эту фичу использовать у себя, если сделаем каждый класс для слота как State, то есть чтобы все значения, которые принимаются в конструкторе или используются в контракте были обернуты в State, чтобы он был в курсе изменений и смог правильно запустить рекомпозицию в нужных местах.
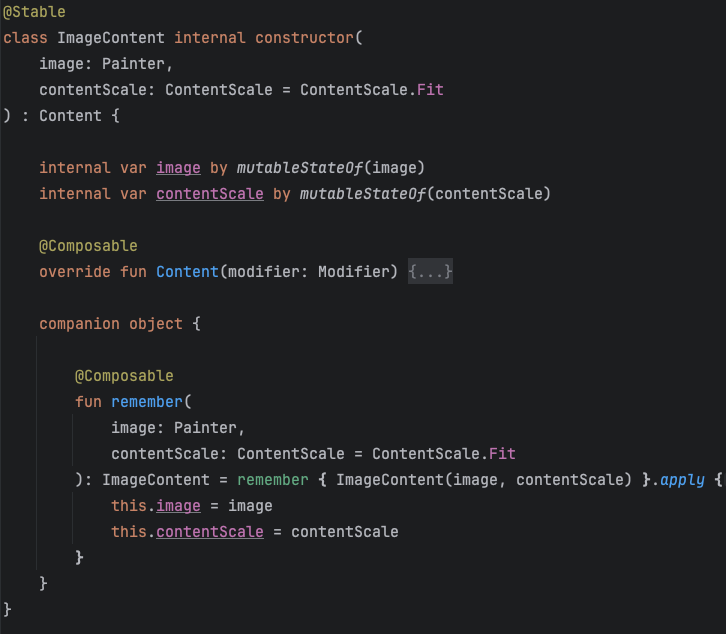
По такому варианту нам даже не нужно пересоздавать класс при изменениях данных, мы можем обновлять значения в классе по тому же принципу, что remeberUpdateState: оборачиваем создание класса в remember без ключей и на каждом вызове функций присваиваем новые значения.
Добавив немного структуры получил примерно следующее:
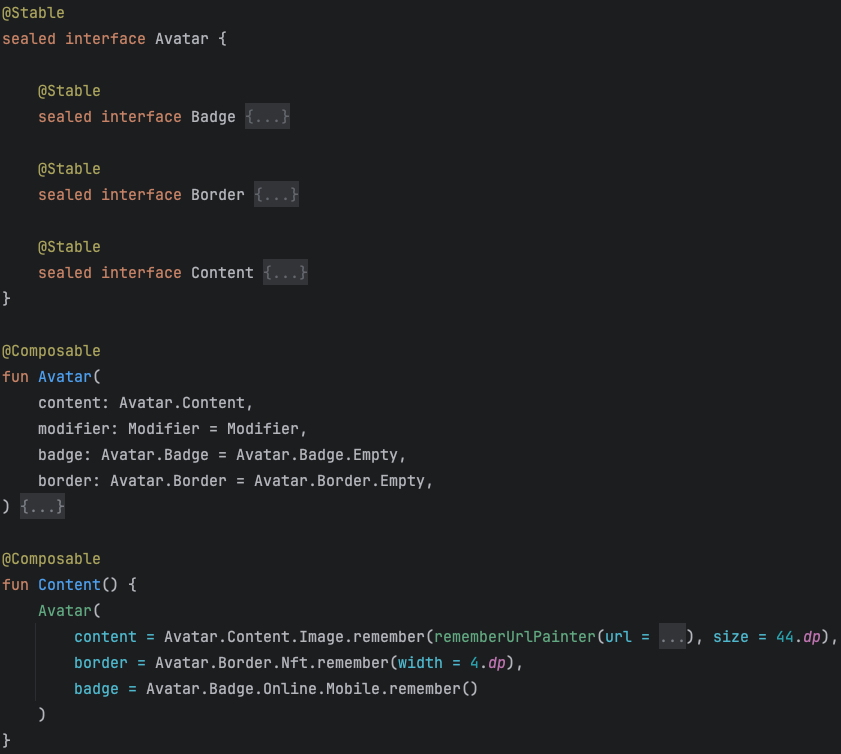
Плюсы:
- Имеется структура слотов
- Не пострадал api компонента*
- Слоты следуют определенному контракту
- Разработчик в курсе какие слоты реализованы, каких не хватает и как их реализовать
- В компоненте только важная часть логики размещения слотов
- Классы переиспользуются и не вызывают лишних рекомпозиций
- Работает donut-hole skipping, благодаря которому рекомпозиция происходит в конкретном слоте и только по необходимости в родителе
Минусы:
- Если слотов много, то разрастается код sealed интерфейсов. Очень помог бы codgen, который собирал все в одну кучу. Либо вариант с выносом этой логики в какой-нибудь DSL. Эксперты по идиоматичному Kotlin подскажут лучше :)
- Абьюзим память Compose Runtime в виде Slot Table тем, что храним много объектов. Но это оптимизируется на стороне Compose Compiler, так как там в 1.5.6 включили оптимизации remember по умолчанию.
5. Хранить данные в Modifier
Чуть позже, просматривая различные репозитории в GitHub, наткнулся на ещё один вариант реализации компонентов, вдохновленный внутренней реализацией Modifier.
В этом репозитории дизайн система довольно скудная, но реализована она интересным образом. Там есть следующее:
- Кодогенерация с использование KSP для генерации sample приложения, как в google/casa-android
- Компиляторный плагин для генерации компонентов оберток над примитивными компонентами
- Прокидывание данных для компонента через Modifier
Нам интересно последнее. К тому же сами разработчики в Readme акцентируют на этом внимание.
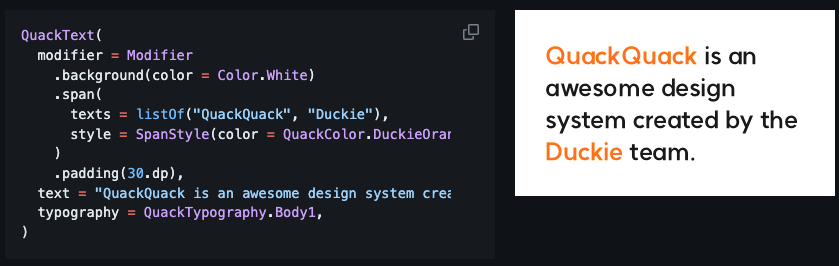
Начну с того, чем вдохновлялись при создании такого решения. В Compose Runtime есть такая функция, как materialize, которая вызывается для каждой LayoutNode. Ее основная задача в том, чтобы проитерироваться по цепочке Modifier.Element и выполнить @Composable лямбды, которые прокидываются через Modifier.composed.
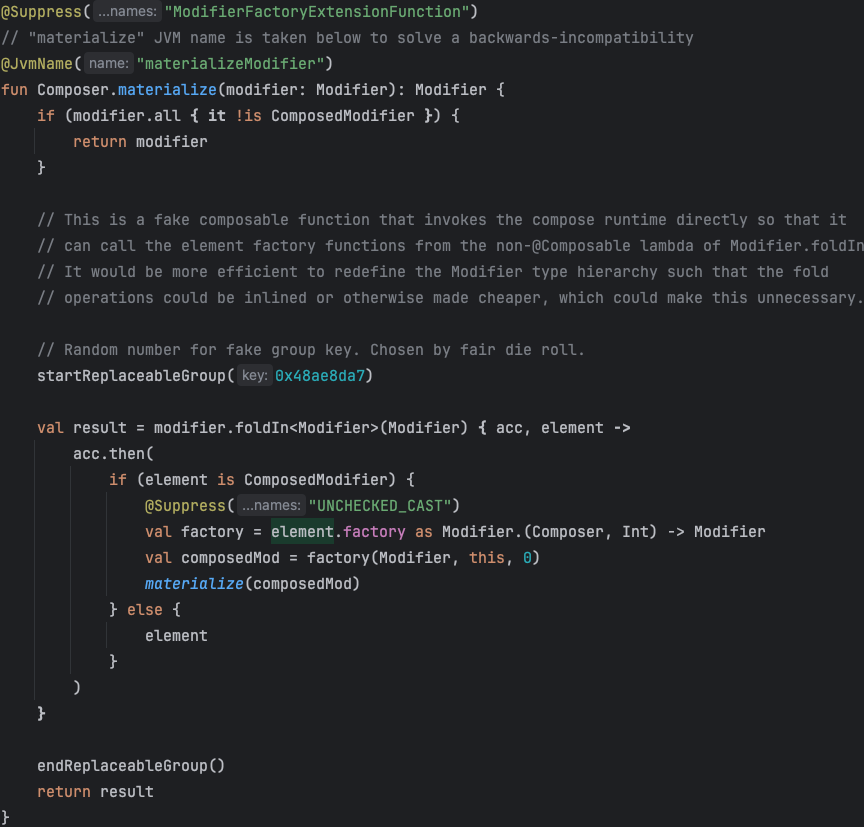
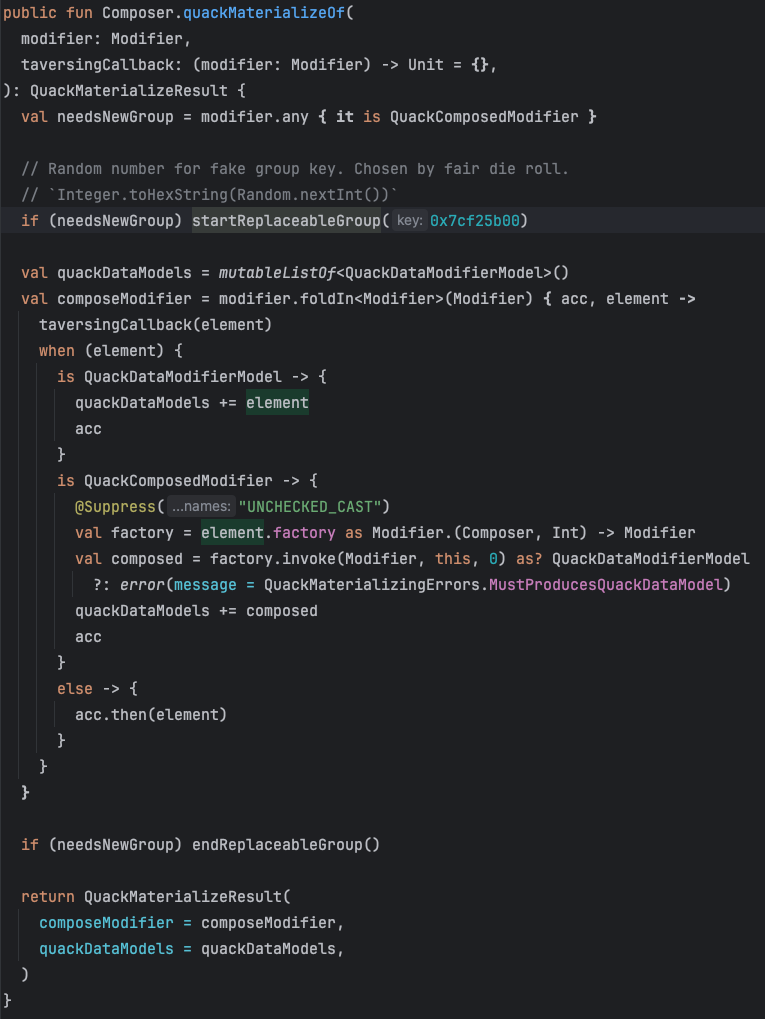
В дизайн системе же Quack-Quack есть функция quackMaterializeOf, которая повторяет логику выше, но для того чтобы вытащить все модели с описанием состояния компонента. Такое возможно, так как модели реализуют Modifier.Element.
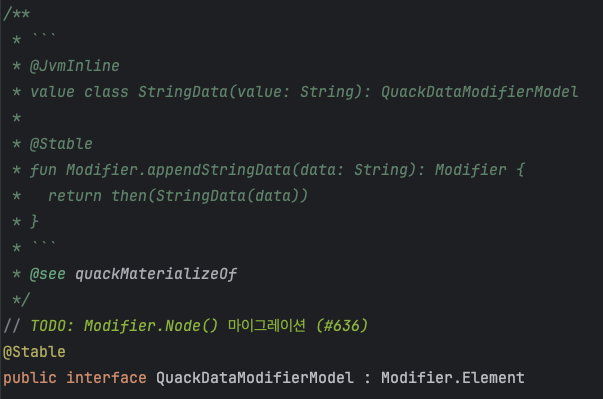
В базовом интерфейсе есть дока как создавать новые модели. К тому же планируют скоро переписать на более оптимизированный Modifier.Node. Эта часть очевидна вдохновлена ParentDataModifier.
Причем они даже скопировали работу composed в своей обертке, чтобы после выполнения @Composable лямбды так же вытащить модели для компонента.
Функция quackMaterializeOf вызывается в каждом компоненте, а из всех моделей компоненты вытаскивают только необходимые для них.
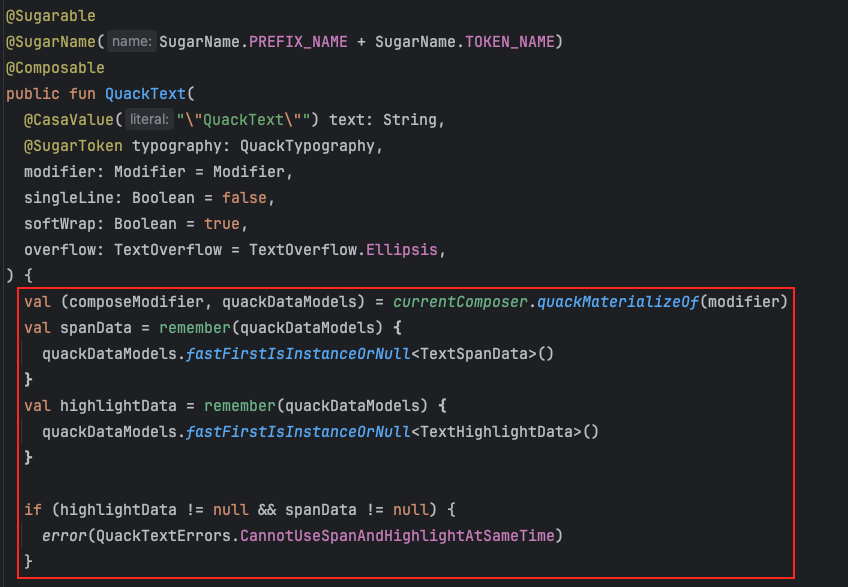
Решение выглядит довольно экзотическим. Мне нравится, что они применили идеи из Compose Runtime и UI, но не нравится количество аллокаций для создания экземпляров моделей и списка с моделями. Кроме этого, для больших цепочек будет довольно много итераций, чтобы вытащить нужные модели.
Опубликовано в Полуночные Зарисовки