Real Time Change Data Capture from PostgreSQL to Kafka Using Debezium
Data&AI Insights📖 Источник: medium.com
Краткое содержание статьи Статья посвящена созданию и тестированию конвейера Change Data Capture (CDC) для потоковой передачи данных в реальном времени из PostgreSQL в Apache Kafka с использованием Debezium. Автор подробно описывает архитектуру решения, настройку компонентов в Docker-контейнерах и демонстрирует практическую реализацию с конкретными командами и конфигурациями. В статье приводятся технические детали, примеры команд и визуализации, что делает материал полезным для инженеров, желающих построить подобные системы.
Введение в Change Data Capture (CDC) и его актуальность
В современных системах необходимость передачи данных в реальном времени стала критичной для аналитики, микросервисов и мониторинга. Change Data Capture (CDC) — это технология, позволяющая фиксировать и транслировать изменения в базе данных (вставки, обновления, удаления) практически мгновенно. В статье рассматривается реализация CDC для PostgreSQL с передачей событий в Kafka через Debezium.
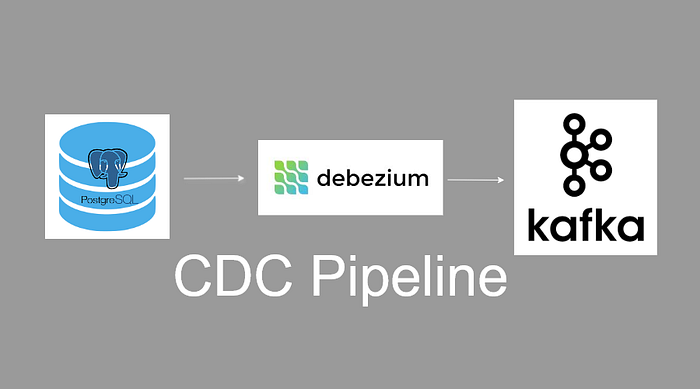
Архитектура решения
Основные компоненты архитектуры:
- PostgreSQL — исходная база данных, где происходят изменения.
- pgAdmin — инструмент для управления и наблюдения за базой данных.
- Debezium Connect — движок CDC, который отслеживает изменения в PostgreSQL и публикует их в Kafka.
- Apache Kafka — платформа для потоковой передачи событий.
- Kafka UI — интерфейс для визуализации топиков и сообщений Kafka.
При каждом событии INSERT, UPDATE или DELETE в PostgreSQL Debezium фиксирует изменение и отправляет его в Kafka в режиме реального времени.
Настройка среды с Docker Compose
Для удобства развертывания все сервисы упакованы в один Docker Compose файл с пятью контейнерами:
postgres— контейнер с PostgreSQL.pgadmin— контейнер с pgAdmin для управления БД.kafka— контейнер с Apache Kafka.kafka-ui— контейнер с интерфейсом Kafka UI.debezium/connect— контейнер с Debezium Connect (версия 2.6).
Пример конфигурации Docker Compose (версия 2.2):
💻 Код (yaml):
version: "2.2"
services:
pgadmin_service:
image: dpage/pgadmin4
container_name: my-pgadmin
environment:
PGADMIN_DEFAULT_EMAIL: muaazmuzammil69@gmail.com
PGADMIN_DEFAULT_PASSWORD: 123
ports:
- "5050:80"
volumes:
- /c/Users/Muaaz/Desktop/data/pgadmin:/var/lib/pgadmin
depends_on:
- postgres
postgres:
image: postgres
container_name: postgresdb
restart: always
ports:
- 5432:5432
volumes:
- /c/Users/Muaaz/Desktop/data/postgres:/var/lib/postgres
command: >
postgres -c wal_level=logical -c max_replication_slots=10 -c max_wal_senders=10
environment:
- POSTGRES_USER=postgres
- POSTGRES_DB=test
- POSTGRES_PASSWORD=123
broker:
image: apache/kafka:latest
container_name: broker
ports:
- "9092:9092"
environment:
KAFKA_NODE_ID: 1
KAFKA_PROCESS_ROLES: broker,controller
KAFKA_LISTENERS: PLAINTEXT://broker:9092,CONTROLLER://broker:9093
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker:9092
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@broker:9093
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_NUM_PARTITIONS: 3
debezium:
image: debezium/connect:2.6
container_name: debezium
ports:
- "8083:8083"
depends_on:
- broker
- postgres
environment:
BOOTSTRAP_SERVERS: broker:9092
GROUP_ID: 1
CONFIG_STORAGE_TOPIC: debezium_configs
OFFSET_STORAGE_TOPIC: debezium_offsets
STATUS_STORAGE_TOPIC: debezium_statuses
KEY_CONVERTER: org.apache.kafka.connect.json.JsonConverter
VALUE_CONVERTER: org.apache.kafka.connect.json.JsonConverter
VALUE_CONVERTER_SCHEMAS_ENABLE: "false"
KEY_CONVERTER_SCHEMAS_ENABLE: "false"
kafka-ui:
image: provectuslabs/kafka-ui:latest
container_name: kafka-ui
environment:
KAFKA_CLUSTERS_0_NAME: local
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: broker:9092
KAFKA_CLUSTERS_0_ZOOKEEPER: ""
ports:
- "8080:8080"
depends_on:
- broker
volumes:
postgres_data:Запуск всех контейнеров производится командой:
💻 Код (bash):
docker compose up -d
После запуска в Docker Desktop будут отображаться контейнеры postgresdb, my-pgadmin, broker, debezium и kafka-ui.
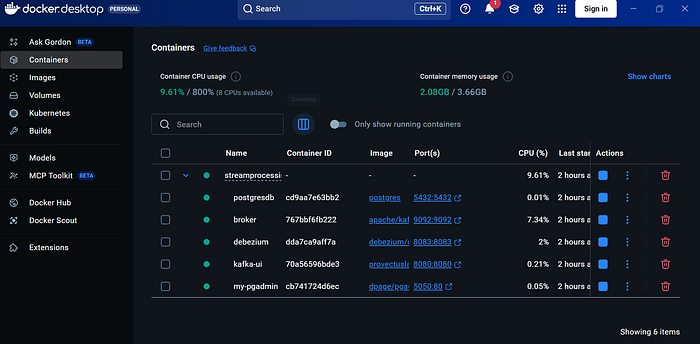
Добавление PostgreSQL коннектора в Debezium
Для подключения Debezium к PostgreSQL необходимо создать коннектор с помощью REST API Debezium Connect. Пример запроса на PowerShell:
💻 Код (powershell):
$body = @'
{
"name": "postgres-cdc",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "postgres",
"database.port": "5432",
"database.user": "postgres",
"database.password": "123",
"database.dbname": "test",
"topic.prefix": "pg",
"schema.include.list": "public",
"table.include.list": "public.*",
"publication.autocreate.mode": "all_tables",
"include.schema.changes": "true",
"plugin.name": "pgoutput"
}
}
'@
Invoke-RestMethod -Uri http://localhost:8083/connectors -Method Post -ContentType "application/json" -Body $bodyДля проверки созданных коннекторов используется команда:
💻 Код (powershell):
Invoke-RestMethod http://localhost:8083/connectors

Визуализация данных и потоков
После настройки коннектора можно открыть веб-интерфейсы:
- Kafka UI на
localhost:8080для просмотра топиков и сообщений Kafka. - pgAdmin на
localhost:5050для управления базой PostgreSQL.
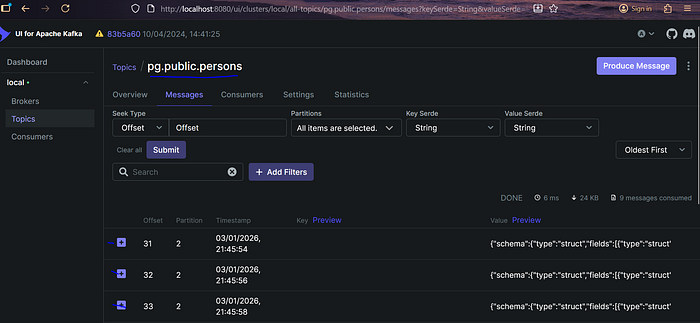
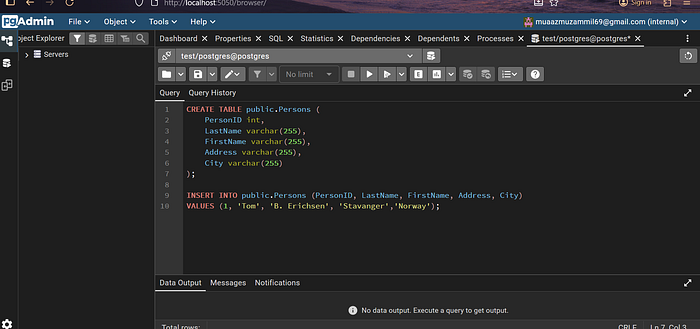
Демонстрация работы CDC на примере таблицы
Создается тестовая таблица в PostgreSQL, после чего при вставке данных Debezium фиксирует изменения и отправляет их в Kafka. Каждое сообщение в Kafka соответствует одной записи, вставленной в базу.
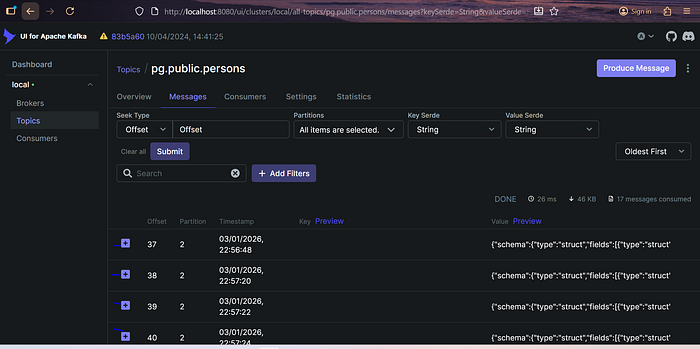
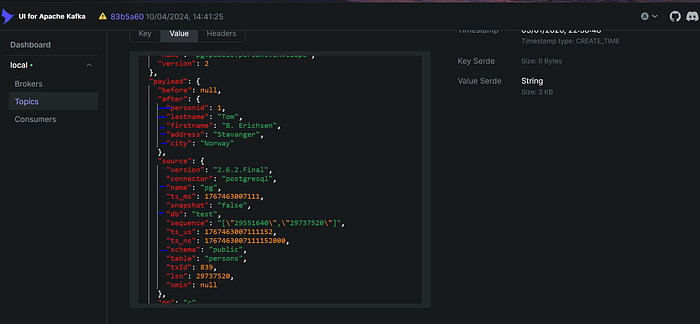
При открытии отдельного сообщения в Kafka UI виден полный полезный нагрузка с данными вставленной записи.
Итоги и перспективы развития
Данный пример демонстрирует, как с помощью PostgreSQL, Debezium и Kafka можно быстро и просто построить потоковую систему передачи данных в реальном времени, используя Docker для удобства развертывания. Такой конвейер CDC фиксирует каждое изменение (вставка, обновление, удаление) и транслирует его в Kafka, что позволяет реализовать event-driven архитектуру и обрабатывать данные в реальном времени.
Хотя пример выполнен в локальной среде, он близок к промышленным решениям и может служить основой для более сложных сценариев, таких как:
- Реальное время аналитики.
- Взаимодействие микросервисов.
- Обработка данных downstream с использованием Apache Spark, Apache Flink и других инструментов.
Дальнейшее развитие конвейера может включать:
- Добавление потребителей данных (consumers).
- Обработку эволюции схемы данных.
- Интеграцию с облачными Kafka-сервисами.
Статья от Muaaz, опубликованная 3 января 2026 года на платформе Medium в издании Towards Data Engineering, представляет практический и технически детализированный гайд по организации CDC-потока с PostgreSQL в Kafka с использованием Debezium и Docker.
📢 Информация предоставлена телеграм-каналом: Data&AI Insights
🤖 Data&AI Insights - Ваш источник инсайтов о данных и ИИ