Размечаем данные. Быстро, недорого.
DeepSchoolАвтор: Илья Бакалец
Редакторы: Марк Страхов, Тимур Фатыхов
Представьте ситуацию: подходит к концу спринт, во время которого вы с командой планировали разметить десятки тысяч картинок для обучения новой нейросети (допустим, детектора). Откладывать задачи — не про вас! И вы обязались придумать способ как успеть в срок!
В такой ситуации вам как раз поможет наша статья. В ней мы расскажем вам:
- как развернуть CVAT - популярный сервис для разметки данных;
- как быстро и удобно предразметить датасет с помощью yolo и fiftyone;
- как загрузить полученный датасет на CVAT для переразметки;
- и как выгрузить переразмеченный датасет обратно.
Развернем CVAT
Представим, что сервиса для разметки у вас нет и вы хотите развернуть его у себя. В документации есть инструкции для установки CVAT на Windows, Mac OS и Ubutu. В статье мы рассмотрим пример установки на Ubuntu 18.04.
Установим Docker
sudo apt-get update sudo apt-get --no-install-recommends install -y \\ apt-transport-https \\ ca-certificates \\ curl \\ gnupg-agent \\ software-properties-common curl -fsSL <https://download.docker.com/linux/ubuntu/gpg> | sudo apt-key add - sudo add-apt-repository \\ "deb [arch=amd64] <https://download.docker.com/linux/ubuntu> \\ $(lsb_release -cs) \\ stable" sudo apt-get update sudo apt-get --no-install-recommends install -y docker-ce docker-ce-cli containerd.io
Делаем так, чтобы docker мог работать без root прав. Для этого создадим docker-группу и добавим в нее своего пользователя
sudo groupadd docker sudo usermod -aG docker $USER
Ставим docker-compose (1.19.0 или выше), который помогает управлять несколькими связанными между собой сервисами. Без него CVAT не сможет корректно работать, так как CVAT — это целый набор сервисов. Помимо фронтенда в нем есть еще django-бэкенд, postgresql и redis.
sudo apt-get --no-install-recommends install -y python3-pip python3-setuptools sudo python3 -m pip install setuptools docker-compose
Зависимости установили. Теперь клонируем репозиторий CVAT и переходим в него.
git clone <https://github.com/opencv/cvat> cd cvat
Чтобы получить доступ к CVAT по сети, необходимо экспортировать переменную среды CVAT_HOST (при условии что вы хотите использовать любой другой домен, а не localhost, который используется по умолчанию).
export CVAT_HOST=your-ip-address
Запускаем наш сервис. Это займет какое-то время.
docker-compose up -d
Обратите внимание:
- По умолчанию сервис будет доступен на порту 8080. Но этот порт может быть занят, в таком случае надо поменять порт.
- При использовании sudo, переменные окружения по умолчанию не экспортируются. Если вы выполните sudo docker-compose up -d, то по адресу your-ip-address:8080 не будет ничего, кроме 404.
Для первой проблемы находим в репо(папка cvat) файлик docker-compose.yml и меняем в нем строчку с указанием портов:
ports:
- 8080:8080
например, на такие:
ports:
- 8982:8080
первые четыре цифры — порт на котором будет открываться CVAT. А вторые 4 — порт внутри докера.
Теперь веб-интерфейс будет доступен по адресу: http://your-ip-address:8982/
Для решения второй проблемы можно экспортировать переменную CVAT_HOST внутри команды запуска сервиса:
sudo CVAT_HOST=your-ip-address docker-compose up -d
или использовать флаг -E , чтобы экспортировать переменные окружения c sudo:
sudo -E docker-compose up -d
Сервис подняли. Теперь необходимо создать superuser’а. Потому что если вы просто зарегистрируетесь через интерфейс, у вас не будет прав на создание заданий. Командой ниже мы запускаем питоновский скрипт внутри докер контейнера для создания superuser
docker exec -it cvat_server bash -ic 'python3 ~/manage.py createsuperuser'
Нас попросят ввести логин, пароль и почту. Имя по умолчанию — django
После открываем интерфейс в браузере и вводим логин и пароль суперюзера
Ура, работает!
Все о том как размечать в CVAT и даже больше есть в этой замечательной статье.
А если возникнут проблемы или вопросы всегда можно написать в официальный чатик разработчиков CVAT.
Предразметим и почистим датасет с помощью yolo и fiftyone
Усложним задачу и представим, что данных у нас не было вовсе. В таком случае один из возможных вариантов — напарсить картинок из интернета. Для примера воспользуемся загрузчиком данных из поисковика bing. Собрать полноценный датасет с ним вряд ли получится, но для примера подойдет.
Установим bing-image-downloader и fiftyone (чуть ниже расскажем что это такое)
pip install bing-image-downloader pip install fiftyone
Допустим, мы решаем задачу object detection и хотим собрать и разметить транспорт на шоссе. Для этого используем bing-image-downloader и скачаем 20 изображений по словосочетанию 'traffic_road':
from bing_image_downloader import downloader image_class = 'traffic_road' downloader.download(image_class, limit=20, output_dir='dataset', adult_filter_off=True, force_replace=False, timeout=60, verbose=False)
После того как мы получили наши изображения, отобразим данные с помощью fiftyone.
Fiftyone - это инструмент, который поможет вам визуализировать данные, подсчитывать метрики, искать ошибки в датасете, извлекать срез данных с определенными классами и многое другое.
# С помощью FiftyOne создаем датасет из картинок и посмотрим на них
import fiftyone as fo
import os
cwd = os.getcwd()
DATA_PATH = f'{cwd}/dataset/{image_class}'
# Create a dataset from a directory of images
name = "car-dataset"
dataset = fo.Dataset.from_images_dir(
images_dir=DATA_PATH,
name=name,
)
dataset.persistent = True
session = fo.launch_app(dataset)
Важный момент: чтобы иметь возможность скачать результаты разметки, необходимо сделать датасет “постоянным” с помощью dataset.persistent = True. Этот флаг заставит fiftyone сохранять датасет в базе данных после завершения сеанса.
Так выглядит наш датасет и интерфейс fiftyone.
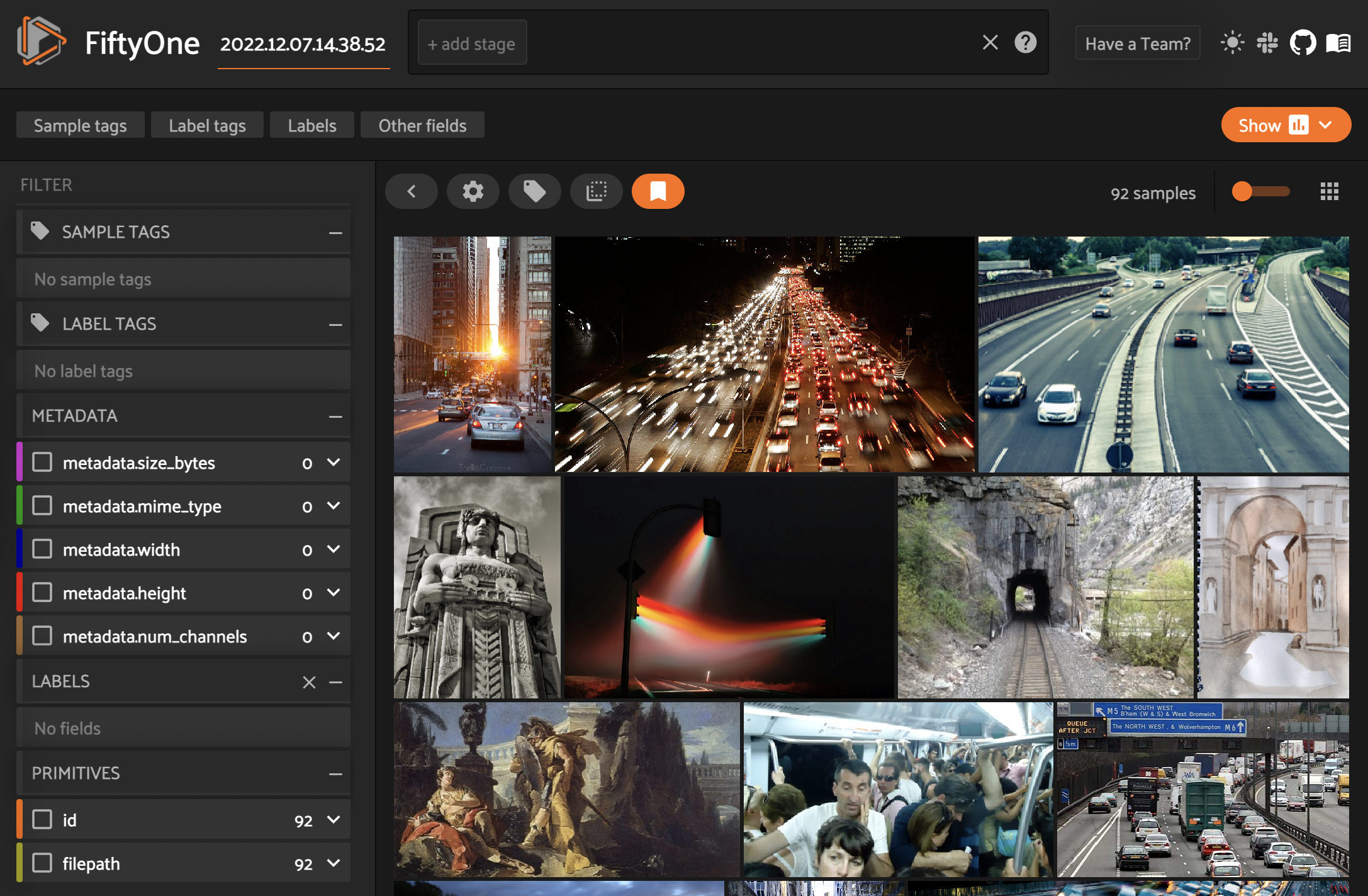
Видно, что не все изображения содержат автомобили. Чтобы почистить датасет и ускорить разметку, предразметим данные с помощью yolov5. Fiftyone также предоставляет инструменты для очистки данных. Например, умеет удалять дубликаты и находить максимально уникальные изображения.
У проекта также есть целый список готовых туториалов, с которыми мы советуем познакомиться :)
Чтобы предразметить изображения, скачем нужную нам модель. В нашем случае это предобученная yolov5x6 на датасете COCO.
import torch
model = torch.hub.load('ultralytics/yolov5', 'yolov5x6')
Чтобы добавить результат инференса в датасет fiftyone, необходимо создать объект DatasetView
preds_view = dataset.take(len(dataset))
Прогоняем наши данные через yolov5 и записываем результаты в fiftyone
from PIL import Image
from torchvision.transforms import functional as func
import fiftyone as fo
# Получим список классов
classes = model.names
# Добавим predictions к samples
with fo.ProgressBar() as pb:
for sample in pb(preds_view):
# Perform inference
w,h = Image.open(sample.filepath).size
preds = model(sample.filepath, size=(w,h))
df = preds.pandas().xyxy[0] #есть формат xywhn - но ббоксы не бъются с картинками есть shift (возможно баг у fiftyone)
labels = df['class'].tolist()
confidences = df['confidence'].tolist()
boxes = df[df.columns[:4]].values.tolist()
# Конвертим детекции в FiftyOne формат
detections = []
for label, confidence, box in zip(labels, confidences, boxes):
# Конвертация из xyxy в xywh со значениями от 0 до 1, то есть нормализованные
x1, y1, x2, y2 = box
rel_box = [x1/w, y1/h, (x2-x1)/w, (y2-y1)/h]
detections.append(
fo.Detection(
label=classes[label],
bounding_box=rel_box,
confidence=confidence
)
)
# Сохраняем predictions в dataset
sample["predictions"] = fo.Detections(detections=detections)
sample.save()
Давайте посмотрим на наш предразмеченный датасет.
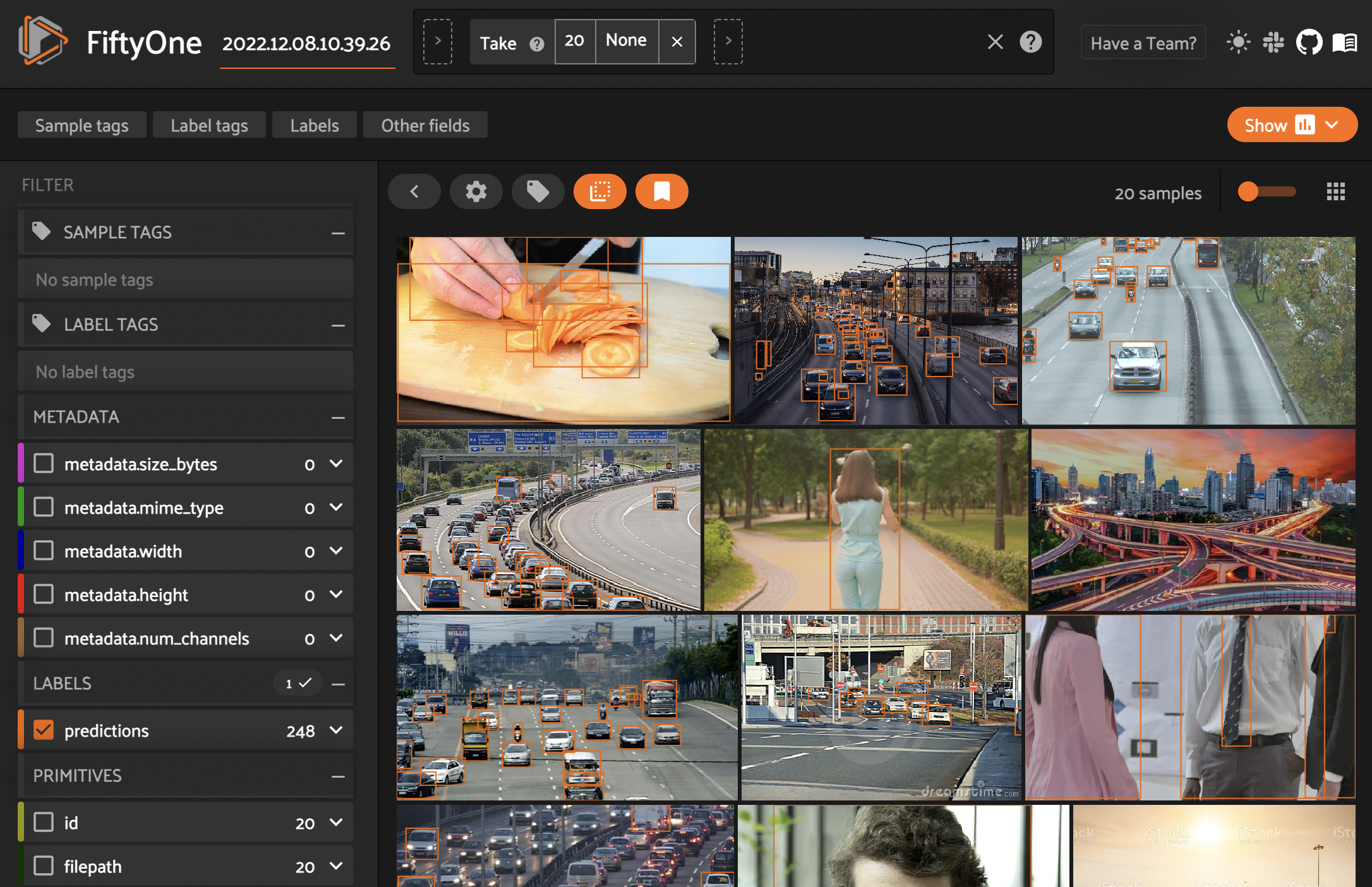
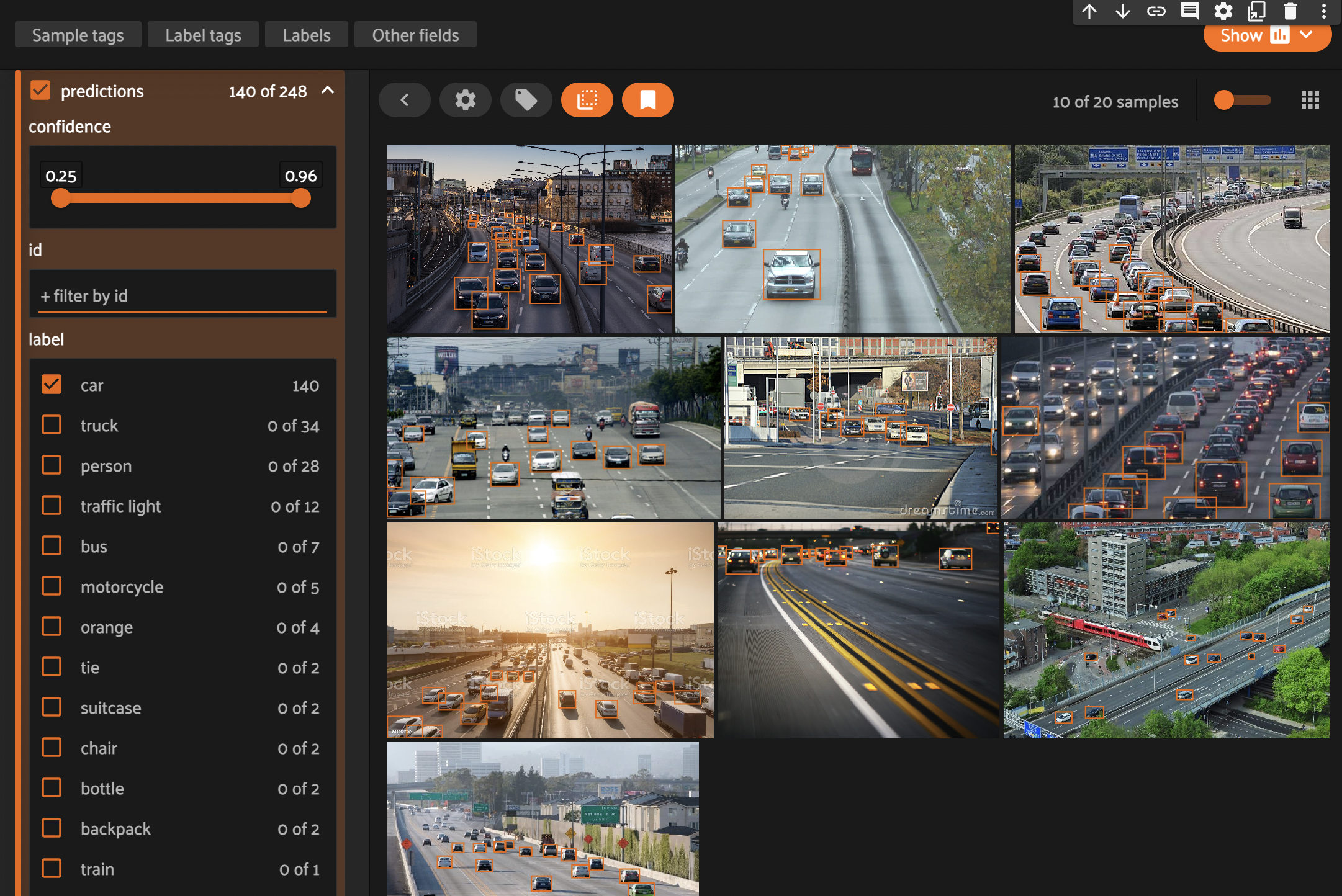
Отберем только те картинки, на которых есть класс car. Для этого разворачиваем вкладку predictions и выбираем в меню слева нужный нам класс. Жмем на бокс с label car. Сэмплы также можно отсортировать по уверенности модели.
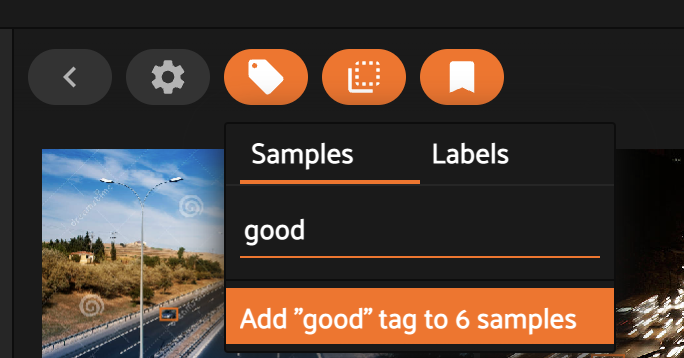
Теперь создадим тег good и присвоим его к выбранным изображениям.
Загрузим датасет на CVAT
Для этого в код ниже надо вписать url, на котором развернут ваш CVAT, логин superuser’а и пароль
# загружаем только семплы которые мы отобрали по классу car с tag good
tagged_view = dataset.match_tags("good")
# Устанавливаем уникальное имя для аннотированного датасета
anno_key = "dets_run"
# Загружаем семплы на cvat
anno_results = tagged_view.annotate(
anno_key,
backend="cvat",
url='http:/your-ip-address:8080/',
username='SUPER_USER_NAME',
password='PASSWORD',
label_field="predictions",
segment_size=100, # по 100 изображений на задание
allow_additions=True,
allow_deletions=True,
allow_label_edits=True,
allow_spatial_edits=True,
launch_editor=True,
)
Все получилось! Задание с предразметкой появилось в CVAT!

Так как разметка может продолжаться неделями, рекомендуем не пользоваться google colab. Когда сессия закончится, кэш отчистится, и ваш датасет невозможно будет скачать обратно через API fiftyone.
# смотрим существующие датасеты
print(fo.list_datasets())
# загружаем датасет если вы прервали сессию
dataset2 = fo.load_dataset("Your dataset name")
Выгружаем измененную разметку из CVAT
cleanup=True - удалит задание из CVAT, если вы этого не хотите, поставьте False
tagged_view.load_annotations("dets_run", cleanup=True)
session.view = tagged_view
Сохраним данные в формате yolov5
export_dir = f"{cwd}/cars_dataset"
label_field = "predictions"
# Экспорт dataset в yolov5 формат
dataset_type = fo.types.YOLOv5Dataset
# Export the dataset
tagged_view.export(
export_dir=export_dir,
dataset_type=dataset_type,
label_field=label_field,
)
Ура вы счастливый обладатель размеченного датасета!
Весь код из статьи сохранили для вас в ноутбуке: google colab