Разбор репорта FineWeb
@ibragim_bad
Напомню, что такое FineWeb. HuggingFace покумекали и выложили:
- FineWeb: много, 15Т(трлн) англ токенов норм качества. Прошлый большой датасет RedPajamaV2 на 20T англ токенов, но хуже по качеству + нужно сидеть и самому фильтровать по посчитанным сигналам. FineWeb немного лучше прошлых композитных датасетов, но нет сравнения с cultura-x. Думаю, что там +- похожее качество.
- FineWeb-edu: 1T отфильтрованных по образовательной ценности токенов. Вот этот датасет поинтереснее, хоть и есть вопрос к лицензии. Такого объема отфильтрованных классификатором данных в открытый доступ еще не выкладывали.
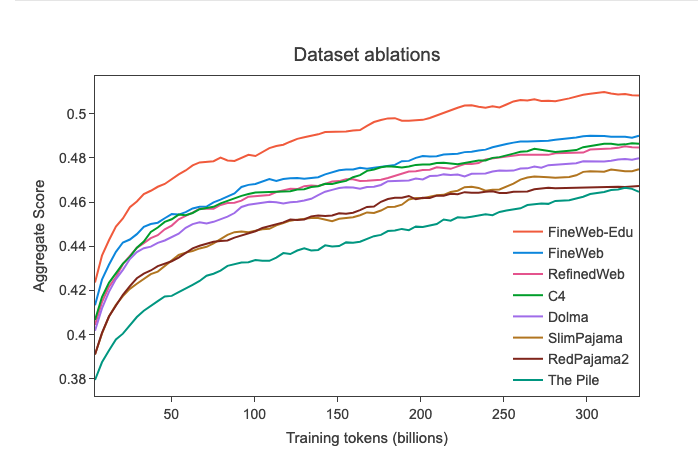
Данные в LLM
- Нужно много данных – если для GPT-2 использовали 8B (млрд) токенов, то для LLaMA-3 уже 15T. Кроме интернета, такое количество взять негде.
- Нужны качественные данные, но “качественные данные“ – это понятие относительное, поэтому все используют разные методы, чтобы оценить их качество.
- Всегда существует ограничение по количеству ресурсов (время, компьютеры, люди), которые можно использовать для обучения модели. Эти ограничения определяют решения и компромиссы: какие метрики измерять, какие данные использовать, какие обработки применять, каким доменам дать больший вес, а каким меньший и т.д.
Как оценивать качество текстов для обучения?
Сложно четко сформулировать универсальное понятие “качественности данных“. Но можно сказать, что если модель обученная на одних данных, лучше по ряду метрик, чем модель обученная на других, то такие данные для данных метрик лучше. Поэтому берем тексты -> применяем свою обработку -> обучаем модель -> смотрим стала ли модель лучше, чтобы оценить наше влияние на данные.
Выбор метрик. Базовые модели учились продолжать текст, поэтому для сравнения в стиле arena chat (выбор лучшего ответа на инструкцию), нужно сделать alignment и уже потом запускать оценку метрик. Но базовые модели, все еще можно сравнить по среднему на подмножестве бенчмарков. Тут важно подобрать правильный набор бенчмарков, у которых:
- Дисперсия между разными запусками обучения на подмножествах одной смеси данных будет маленькой.
- Результат монотонно растет с продолжением обучения.
- Результат обученной модели превышает результат случайного решения.
Размер модели и сколько токенов учить. В fineweb взяли 1.8B модель и учили на 28B токенов. Это +-шиншилла оптимальный размер. Это означает, что для затраченного компьюта (объема вычислений) это оптимальный размер модели и данных. Еще важный момент это последующее обучение на 350B токенов. Это аналог обучения 7B модели на 1.4T токенов, как было в первой ламе. Такое обучение нужно, чтобы завалидировать результаты, потому что модель может рано выйти на плато.
Наша методология такая же, даже размеры совпали за исключением нескольких моментов.
- Мы учим MoE(Mixture-of-Experts) модели, потому что за такое же количество компьюта – можно получить модель лучше и уловить больше сигнала.
- У нас есть предварительные эксперименты для фильтрации гипотез на моделях с ~250M(млн) активных параметров и 6B токенов. Это позволяет вместо одного эксперимента с моделью на 1.8B параметров и 28B токенов запускать несколько экспериментов для проверки различных гипотез и отсеивать нерабочие варианты раньше.
- Мы используем доп бенчмарки (в том числе на других языках) для более широкой оценки. Важно отметить, что некоторые бенчмарки могут не коррелировать или даже отрицательно коррелировать между собой.
Рецепт обработки веб данных
Веб-данные — это буквально HTML-страницы, которые собрал веб-краулер. У крупных компаний есть свои боты (как у OpenAI, Anthropic и Google). Также существует открытый проект CommonCrawl, который с 2008 года собирает данные из интернета и выкладывает свежие архивы на свой S3, откуда их может скачать любой желающий. Последний дамп (18-31 мая) в несжатом формате весит 414 ТБ!
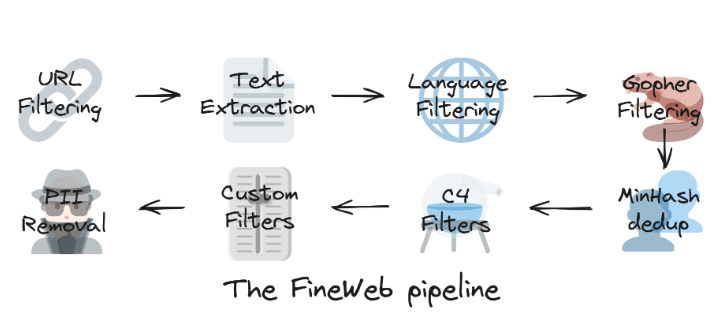
Шаги, которые выполняются при сборе собственного датасета для обучения LLM из дампов CommonCrawl:
- Экстракция из HTML страниц. В CC есть WARC и WET файлы. Первые – это сырой html, а второй уже извлеченный текст. Текст там не вау, если есть ресурсы лучше извлекать самим. Fineweb используют trafilatura, как и многие другие. Из других опций, можно глянуть табличку экстрактеров в OpenWebMath, там важно было вытащить LaTeX корректно, поэтому пробовали по разному. Также можно извлекать текст, стараясь сохранить структуру. Например, Mistral извлекает тексты в формате markdown.
- Определение языка FastText классификатором. Классификаторы FastText — полезный инструмент. Во-первых, он дешевый (токенизация -> lookup в матрице эмбеддингов -> усреднение -> линейный слой), что позволяет масштабировать его применение на CPU-кластере. Кроме того, он достаточно хорош по качеству на задачах, где есть явные токены предикторы, вроде определения языка или детекции NSFW контента.
- Эвристики. Можно отфильтровать слишком длинные документы или по другой эвристике, которая может указывать на ошибку в экстракции. Сигналы собираются и фильтруются по-разному: по порогу, по перцентилю (как в Cultura-X). В FineWeb использовали статистики, которые сильнее всего отличались между данными низкого и высокого качества.
- Дедупликация. Дедупликация — это удаление дубликатов и очень похожих документов. Дедупликация нужна, но с ней надо быть аккуратным, чтобы не удалить лишнее. В fineWeb интересное наблюдение: глобальная дедупликация вредит, лучше использовать локальную в рамках одного дампа CommonCrawl. Объяснение в том, что глобальная дедупликация повышает долю данных низкого качества, так как они достаточно уникальны, а некоторые качественные документы могут оказаться похожими между дампами. При этом кластеры популярных дубликатов можно найти и внутри дампа.
Мы тоже используем MinHash для дедупликации и дедупликацию по эмбеддингам. Для ускорения дедуп проводится в рамках кластера.
У нас также есть методы для повышения разнообразия документов и перераспределения весов по кластерам, как тут.
Фильтрация образовательных данных
Это самая сочная часть.
Короче, за последний год стало ясно, что кроул(веб документы) содержит конкретные кластеры качественной информации, которую можно использовать для того, чтобы подтягивать конкретные способности моделей. Раньше все скорее пытались выкинуть какие-то некачественные куски информации из кроула. А остальное добить курируемыми источниками (посмотрите в pile источники, вроде архива, памбеда, книг итп).
Про фильтрацию образовательных данных писали еще в phi-2. Потом начали писать чаще, вот и в llama-3 такой подход использовали.
В чем суть подхода.
- Давайте разметим LLM 100к-1000к веб документов на предмет их образовательной ценности. (Тут собрали такой Промт, которые ставит скор 0-5)
- Используем эти размеченные данные, чтобы обучить классификатор.
- Разметить все документы, которые есть и возьмем топ.
Чтобы качество такого классификатора было лучше, нужно брать Bert-like эмбеддер, а не просто fasttext. В FineWeb не пожалели 6000 h100 часов и взяли топ эмбеддер для англ от snowflake для своего размера.
Как итог, разметили 15T и достали из него образовательные 1.3T. Это дало значительный прирост на образовательных бенчмарках (оценка знаний, таких как ARC, MMLU, OpenBookQA).
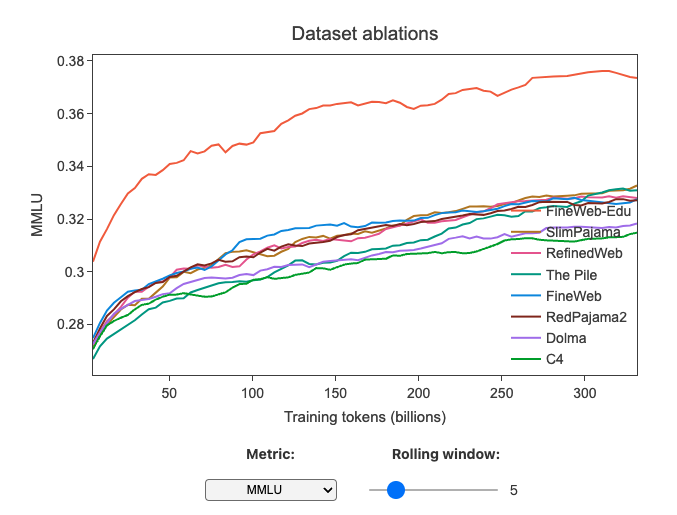
Про FineWeb-edu — здорово, что они выложили такой объем данных. Есть только один комментарий: ребята из FineWeb использовали LLaMA-3-70B для разметки всех этих данных. Честно говоря, я не понял мотивацию использовать LLaMA-3-70B, когда у них была Mixtral 8x22B, которая была такой же по качеству, но с более свободной лицензией. У LLaMA-3 моделей строгая лицензия: нельзя обучать модели, отличные от LLaMA-3, на результатах работы LLaMA-3, плюс везде надо писать "Built with Meta LLaMA 3" и использовать LLaMA-3 в названии своей модели. Сейчас у fineweb стоит лицензия odc-by, но это не совсем так с учетом лицензии ламы. Но пока всем пофиг)
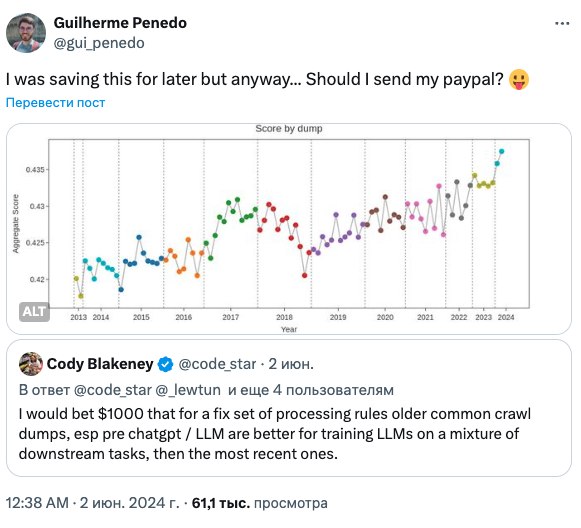
Еще в статье есть бонусная часть. Существует такое мнение, что из-за бума ллм, качество данных в интернете становится ниже, поэтому последние кроулы менее качественные, чем предыдущие. Для проверки этого решили сделать эксперимент. Буквально, обучили на каждом дампе свою модель и проскорили.
Оказалось, что последние кроулы более качественные, чем прошлые + в них больше синтетики от моделей, но кажется, что это не портит качество на текущий момент. Вот так, потратили 60k h100 часов, зато ответили на этот вопрос и чел из hf выиграл 1k$ в споре в Твиттере.
––––––––––––––––
Если вам понравился разбор – одобрительно кивните головой в сторону экрана, а если не понравился, то не одобрительно.
Автор разбора: @c0mmit