Распределенный кэш. Часть 1.
https://t.me/faangmasterВведение
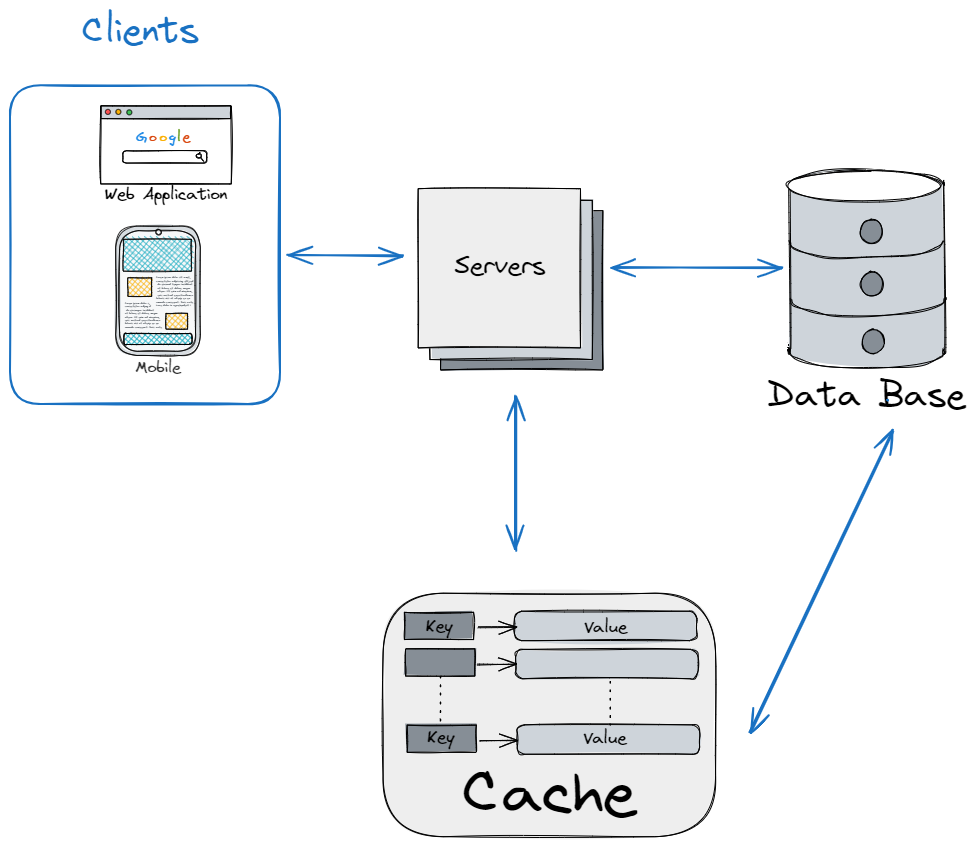
Типичное web-приложение состоит из клиента(браузер, мобильное приложение и т.д.), серверов с бизнес логикой приложения и базы.

Для небольших приложений такой архитектуры достаточно. Но по мере роста числа пользователей у нас растет и нагрузка на базу. Что приводит ухудшению производительности приложения. В таком случае можно добавить в систему кэш. Кэш хранит данные в оперативной памяти, что позволяет ускорить процесс чтения данных. Оперативная память дороже SSD или HDD, поэтому в кэше, обычно, хранится только часть наиболее часто используемых данных из базы. Вначале, сервер читает данные из кэша. Если они там есть (cache hit), то данные возвращаются из кэша. Если их там нет (cache miss), то данные читаются из базы.
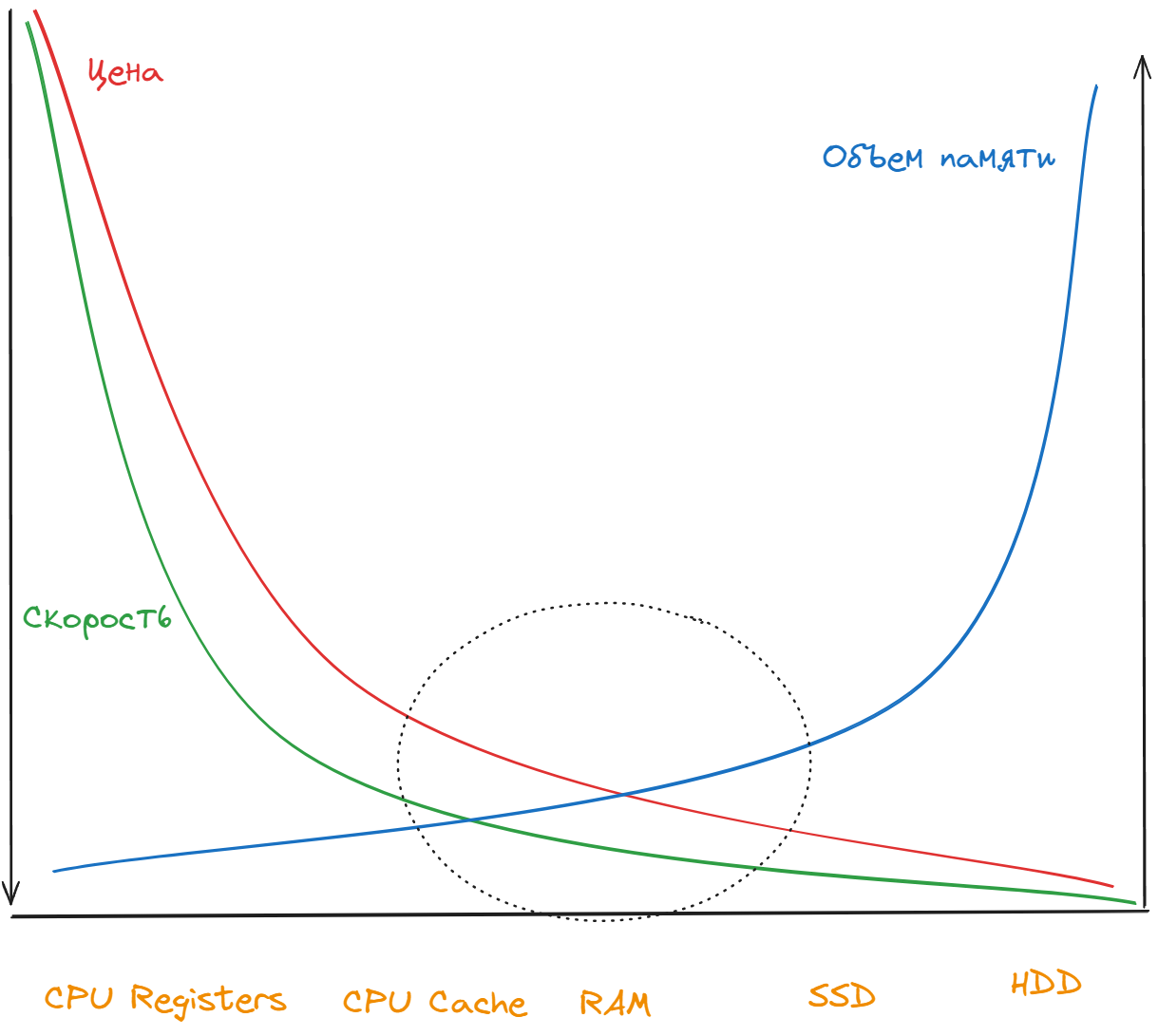
Кэш использует оперативную память (RAM) для хранения данных, т.к. она является оптимальным решение с точки зрения соотношения цены, скорости работы и объема. SSD и HDD позволяют хранить больше данных и стоят дешевле, но скорость чтения для них ниже. Скорость чтение из регистров процессора или кэша процессора намного выше, но при этом они не позволяют хранить много данных и дорого стоят. Поэтому RAM является оптимальным решением для кэша приложения.
Что такое распределенный кэш и зачем он нужен?
Распределенный кэш – это система кэширования, в которой используется несколько серверов, которые взаимодействуют друг с другом, для хранения данных. Распределенные кэши необходимы в случаях, где одного сервера недостаточно для хранения всех данных. Они также обеспечивают более высокую степень масштабируемости (scalability) и доступности (availability).
Некоторые плюсы использования распределенных кэшей:
- Позволяют минимизировать latency на чтение данных, что улучшает user experience, т.к. пользователь получит нужные ему данные в разы быстрее.
- Позволяет сохранить в памяти, для быстрого доступа, результаты долгих и ресурсоемких запросов или вычислений.
- Можно читать данные из кэша, даже если база лежит и недоступна.
По мере роста числа данных, они перестанут влезать на один сервер кэша, и нам нужно распределить наши закэшированные данные на несколько серверов. Для этого нам нужен распеределенный кэш. Распределение данных на несколько серверов позволяет избежать проблемы single point of failure (SPOF). Также можно использовать разные кэш сервера для чтения данных в разных географических зонах для уменьшения времени задержки (latency), а также для кэшерования данных для разных компонентов или даже слоев приложения.
Writing policies
Очень часто кэш используется в паре с неким persistent storage (некой базой данных например). В кэше хранятся данные (или часть данных) из базы для быстрого доступа, т.к. чтение из базы может занимать много времени.
При использовании одновременно кэша и persistent storage возникает вопрос, как в таком случае производить запись данных в эти два хранилища. Для этого существует несколько основных подходов (writing policies):
Write-though. Данные записываются как в кэш, так и в базу. Запись может происходить последовательно (сначала в кэш и потом в базу), так и паралельно. Запись в оба хранилища позволяет обеспечить консистентность данных между кэшем и базой. Но это увеличивает время записи и может повлять на производительность приложения.
Write-back. Данные сначала записываются в кэш, а потом асинхронно записываются в базу. Кэш в таком случае будет иметь самое свежее состояние данных, а база может иметь устаревшие значения. Это позволяет ускорить процесс записи, но не позволяет достичь строгой консистентности данных межде кэшем и базой.
Write-around. Данные записываются только в базу. Кэш обновляется только в процессе чтения, если данных в кэше нет (cache miss). База при этом будет иметь самые актуальные данные, а кэш нет.
Eviction policies
Кэш хранит данные в памяти (RAM) для быстрого доступа. При этом RAM сильно дороже по сравнению с SSD или HDD дисками. Поэтому в кэше обычно хранится только часть данных из базы. Следовательно нам нужем механизм, который будет часть данных удалять из кэша. Существуют разные подходы к тому, какие данные следует удалять/вытеснять (eviction policies):
- Least recently used (LRU). Вытесняются данные, которые не использовались дольше всего. Если эти данные дольше всего не читали или не обновляли/записывали, то они удаляются/вытесняются из кэша в первую очередь.
- Most recently used (MRU). В этом случае наоборот, вытесняются только что использованные данные.
- Least frequently used (LFU). Вытесняются наименее часто используемые данные.
- Most frequently used (MFU). Вытесняются наиболее часто используемые данные.
Существует много других подходов к вытеснению (eviction) данных в кэше. Например, FIFO (first in first out), данные удаляются в порядке их добавления, и т.д.
Cache invalidation
Кроме eviction policies, существует другой механизм удаления устаревших данных из кэша, который называется cache invalidation. Устаревшие данные можно удалять используя TTL (time-to-live). Например, указать, что время жизни (TTL) записи в кэше не должно превышать 1 часа, или 1 дня, или 30 дней и т.д. Если запись была создана позже этого времени, то она будет удалена.
Существует активная инвалидация (active expiration) данных, при которой есть некий daemon процесс или поток, которые проверяет когда запись была создана и не превысила ли она свое время жизни (TTL). Если превысила, то запись удаляется. При пассивной инвалидации (passive expiration), такая проверка делается во время чтения из кэша. Если при чтение оказалось, что запись устарела, то она будет удалена из кэша.
Следующая часть: Распределенный кэш. Часть 2.