RG-LRU
История всегда движется по спирали, и быстрая история развития нейронных сетей, оказывается, не исключение. Архитектура трансформеров в LLM в своё время полностью отодвинула рекуррентные нейронные сети, но через несколько лет (то есть примерно сейчас) спираль сделала виток, и вот РНН уже дышат трансформерам в спину. А кое-где даже и обгоняют. Мы уже как-то писали про нео-РНН, новые подходы к старым РНН, которые дают им шанс конкурировать с трансформерами. В этот раз расскажем о уже не самой новой, но более яркой идее.
В Google DeepMind предложили рекуррентный блок RG-LRU (статья), который в состоянии заменить MQA, Multi-query attention (в нём внимание для разных голов рассчитывается с общими векторами K и V, но со своими Q).

Предлагаемая архитектура с RG-LRU состоит из трех блоков: остаточного, мультислойного перцептрона и рекуррентного. Первый определяет глобальную структуру модели, его авторы взяли из pre-norm трансформера. Эмбеддинги входа попадают в эту остаточную часть и проходят через N её слоев, а затем нормируются перед выходом.
После начальной же нормировки скрытые состояния попадают в компонент temporal-mixing. Он собирает состояния из разных по времени положений последовательности. Вообще эта архитектура предполагает, что на месте temporal-mixing может быть механизм внимания — глобальный или локальный MQA (его авторы предпочитают multi-head из-за большей скорости инференса), но в данном случае интереснее, что туда можно вставить рекуррентный блок с новопредложенным RG-LRU. Похожий блок использовался в Mamba и в GSS.
Вход попадает на два линейных слоя параллельно, образуя две ветви. В первой затем идет слой GeLU. Во второй ветви следует небольшой Conv1D слой (действительно очень небольшой — всего 4*D параметров, если D - размерность выхода линейного слоя), а затем главный герой, RG-LRU.
Внутри RG-LRU, простая рекурренция по образу Linear Recurrent Unit (LRU), но дополненная гейтами, идею которых авторы взяли из классических нелинейных РНН.
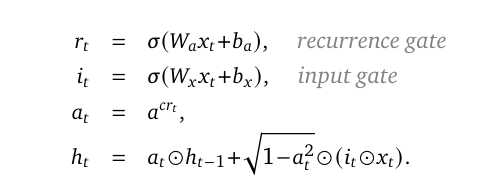
Выход в формулах выше это h, а σ — это сигмоида. Матрица весов a диагональная, так что все преобразования поэлементные. Чтобы рекуррентность была устойчивой, веса находятся как σ(Λ), где Λ — обучаемые параметры. Гейты есть и на входе, и для рекуррентности, но ни те, ни другие не зависят от предыдущего состояния. Это и вообще сама упрощенная структура RG-LRU для более эффективных вычислений.
Входной гейт похож на тот, что был в LSTM, а вот рекуррентный, кажется, ни на что не похож. Например, в Мамбе механизм отбора скорее сравним с гейтом обновлений в GRU, который интерполирует по предыдущему состоянию и текущему наблюдению. Это позволяет обновить состояние и забыть информацию из него (как ворота забывания в LSTM). Тут же гейт рекуррентности интерполирует по стандартному апдейту LRU и предыдущему скрытому состоянию. То есть позволяет сохранить всю предыдущую информацию и не обращать внимания на вход. Отсюда главная роль этих ворот — достигать сверхэкспоненциальной памяти за счет отказа от неинформативного входа.
Главное преимущество рекуррентного блока по сравнению с глобальным вниманием в том, что размер состояния фиксирован, а не растет пропорционально длине последовательности.
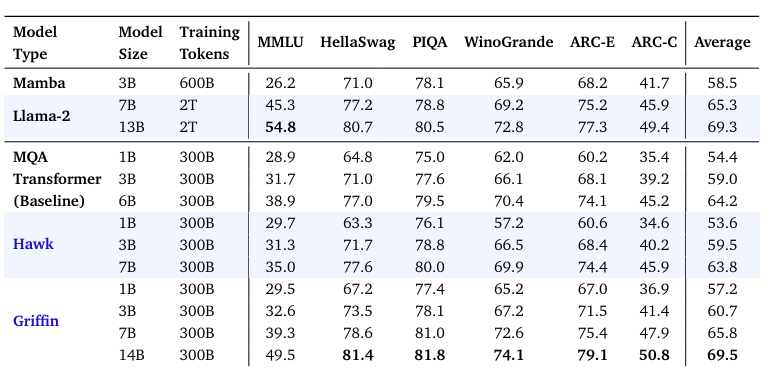
На основе RG-LRU построили две модели. Hawk — собственно, модель, описанная выше. Griffin — микс рекуррентных блоков и MQA. Всё это сравнивали с трансформером (та же архитектура, но со стандартным блоком MQA), а также с Mamba и Llama-2.
Главный результат статьи не сколько в показателях (хотя это, конечно, тоже важно), сколько в масштабируемости. В конце концов, именно этого и добиваются, возрождая РНН. Зависимость лосса от FLOPS при обучении оказалась подчинена тому же степенному закону, что для трансформеров.

Теперь к показателям работы. Griffin на 7В и 14В догнал Llama-2. Только при этом для обучения понадобилось в семь раз меньше токенов. Hawk-3В обошел Mamba того же размера. Если дать на вход последовательности длиннее тех, что были в обучающей выборке, то Griffin оказывается неизменно лучше трансформеров