REST и RPC: Введение в архитектуру HTTP API
Дмитрий БахтенковHTTP API
В прошлых статьях мы уже сталкивались с http api: исследовали его, а также писали свою реализацию. Настало время поговорить о подходах и правилах построения API, то есть об архитектуре. Рассмотрим подходы REST и RPC
REST
Что такое?
Самой популярной на сегодняшний день является архитектура REST - Representational State Transfer (передача состояния представления) - подход к построению HTTP API, который основан на передаче определённого представления сущностей и их состояния от сервера к клиенту. Данный подход включает в себя следующие принципы:
- Клиент-серверная архитектура - разделение ответственности на функции клиента - потребителя данных, и сервера - поставщика этих данных. (добавить фото)
- Stateless - этот принцип заключается в запрете хранения сервером контекста общения с клиентом. Например, сессия пользователя не должна храниться в памяти сервера, а для каждого пользователя подтягиваться из БД. Если сервер будет хранить состояние (stateful), то, например, не получится развернуть второй экземпляр сервера для распределения нагрузки (на старом сервере будет текущая сессия пользователя, а новый сервер не будет ничего знать о ней и снова создаст новую сессию)
- Кэширование - каждый ответ сервера должен иметь пометку, можно ли его кэшировать. Например, если мы запрашиваем у сервера прогноз погоды, то для одинаковых дат нам будет выходить одинаковый результат. Его можно сохранить на клиенте, тем самым снизив нагрузку на сервер и уменьшив кол-во сетевых запросов
- Единообразие интерфейса - это фундаментальное требование REST к построению интерфейса запросов. Состоит из 4 правил:
- Все ресурсы идентифицируются в запросах, например в URI:
user/1- это ресурс “Пользователь” с идентификатором “1” - Манипуляция ресурсами через представление - сервер и клиент обмениваются представлениями ресурсов в различных форматах (чаще всего в формате JSON)
- Самодокументируемые сообщения - каждое сообщение содержит достаточно информации, чтобы клиент мог “понять”, как обрабатывать данные
- Гипермедиа как средство изменения состояния приложения (HATEOAS) - REST-клиенту не требуется заранее знать, как взаимодействовать с приложением или сервером, в ответе от сервера возвращаются варианты перехода к другим состояниям в виде гиперссылок
- Слоистая архитектура - между клиентом и сервером общение не всегда происходит напрямую - запрос может обрабатываться прокси-серверами, балансировщиками нагрузки и другими системами. Суть принципа заключается в следующем: ни клиент, ни сервер не должны знать о том, как происходит цепочка вызовов
- Код по требованию - REST предполагает возможность передачи кода (например, JavaScript) от сервера к клиенту. Это позволяет менять логику клиента с помощью сервера, что даёт больше гибкости в написании приложения
Саму архитектуру REST придумал Рой Томас Филдинг.
Модель зрелости REST API
Существует модель зрелости REST-сервисов Леонарда Ричардсона, который классифицировал REST API следующим образом:
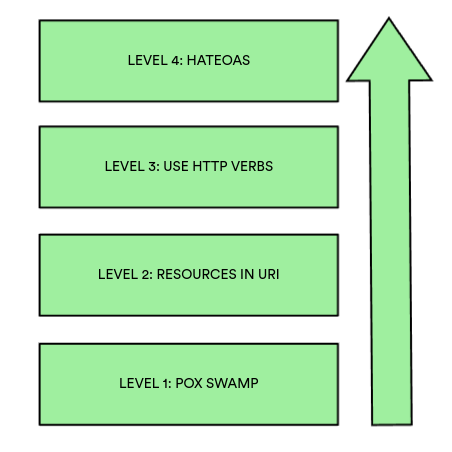
Первый уровень - любые сервисы,которые в качестве транспорта используют HTTP и какой-либо формат представления данных, игнорируя множество эндпоинтов и http-глаголов, таких как POST, PUT и т.д.
Второй уровень - использование различных путей для ресурсов, например
api/users- управление пользователямиapi/orders- управление заказами
Третий уровень - использование http-глаголов для управления сущностями, например:
GET api/users- получить всех пользователейPOST api/users- создать пользователяPUT api/users/{id}- обновить пользователя с определённым идентификатором
И самый верхний, четвёртый уровень - использование HATEOAS, то есть ссылок на соседние сущности в рамках определённого ответа. Например, представим что у нас есть приложение с пользователями, товарами и заказами. Мы выполняем запрос GET api/users/12 и получаем ответ со ссылкой на список заказов, связанных с данным пользователем:
{
"id": 12,
"fio": "Иванов иван иванович",
"links":
[
{ "rel": "orders", "href": "/users/12/orders" }
]
}
Запрашивая заказы - GET /users/12/orders, мы в свою очередь также получим ссылки на товары по данному заказу:
[{
"id": 1,
"userId": 12,
"date": "11/12/2022",
"links":
[
{ "rel": "user", "href": "/users/12" },
{ "rel": "user", "href": "/orders/1/products" }
]
}]
Программный интерфейс, соблюдающий все принципы архитектуры REST, называется RESTful API (полным по REST).
Преимущества REST:
- Понятность программного интерфейса - достаточно просто трактовать HTTP-глаголы и понимать на основе URI с какой сущностью мы работаем
- Масштабируемость - за счёт подхода Stateless можно создавать несколько копий одного API и распределять нагрузку между ними, также чётко разделены клиент и сервер
Недостатки REST:
- Очень много запросов. Для примера рассмотрим сайт с пользователем, заказами и товарами. Чтобы определить список заказов и товаров определённого пользователя, нужно:
a. Получить список заказов по пользователю
b. Для каждого заказа получить информацию о товаре
- Таким образом, если у пользователя 2 заказа, в каждом из которых по 2 товара, в рамках чистой архитектуры REST необходимо выполнить минимум 4 запроса. А заказов в интернет магазинах у людей обычно больше 🙂
- Не всегда можно определить корректную иерархию сущностей. Рассмотрим пример мессенджера, где есть пользователи и групповые чаты. У каждого пользователя может быть несколько чатов, а в каждом чате - несколько пользователей. Образуется связь многие-ко-многим, которую достаточно тяжело представить в рамках REST. Запрос на добавление пользователя в чат должен выглядеть так:
POST api/chats/{chatId}/users/{userId}
Или так:
POST api/user/{userId}/chats/{chatId}?
Мы добавляем пользователя в чат, или чат к пользователю?
На самом деле оба варианта верны. У каждого разработчика “свой” REST, и необходимо просто следовать принципам, определённым в вашей организации
RPC
Общее определение RPC звучит так:
RPC - (Remote Procedure Call, удалённый вызов процедур) — класс технологий, позволяющих программам вызывать функции или процедуры в другом адресном пространстве (на удалённых узлах, либо в независимой сторонней системе на том же узле)
{
"jsonrpc": "2.0", // версия протокола
"method": "", // название функции, которую необходимо выполнить
"params":
{
"param1": "value",
"param2": "value"
}
}
Например, создание пользователя: POST api/userservice/execute:
{
"jsonrpc": "2.0",
"method": "CreateUser",
"params":
{
"login": "mail@example.com",
"password": "12345",
"fio": "Иванов Иван Иванович "
}
}
И ответом на такой запрос может быть:
// 201 - created
{
"jsonrpc": "2.0",
"result":
{
"id": 6582
}
}
По сути RPC представляет собой самый нижний уровень зрелости REST-сервисов Леонарда Ричардсона. Ну, потому что rpc это не rest 🙂
Архитектура RPC была придумана гораздо раньше REST и использовалась, например, десктопных технологиях экосистемы Microsoft. Протокол SOAP также является расширением xml-rpc
Преимущества RPC
- Проще в реализации - единый эндпоинт, вызов конкретных функций
- Высокая производительность
- Более понятен при описании сложных операций (не CRUD)
Недостатки RPC
- Практически нет стандартизации
- Сложность обнаружения и документирования
- Сложности кэширования на уровне инфраструктуры HTTP (например, кэширование в веб-сервер nginx выполняется с помощью uri и глаголов запроса, что очень удобно в случае REST - когда у нас разные глаголы и пути, и усложняется при использовании RPC)
Что когда использовать?
REST:
- Открытое внешнее API (например для интеграции с вашей системой)
- Много незнакомых потребителей (например, когда мы разрабатываем соцсеть, мы не знаем кто будет потребителем и что он будет делать с системой; в случае какого-то внутреннего приложения автоматизации, мы нацелены на конкретных потребителей и сами определяем бизнес-процесс)
- Простые CRUD-операции
- Необходимо использование HTTP-инфраструктуры, например кэширование
RPC:
- Общение между несколькими бэкэндами (back-to-back)
- Заранее знаем потребителей нашего API
- API представляет сложные бизнес-процессы (например, движение какой-то сущности по статусам с вызовом дополнительных триггеров и какими-то доп. настройками)
- Сложные запросы на получение информации (вместо тысячи стандартных REST-запросов выполнить один-два и получить нужную информацию)
Несмотря на то, что в некоторых случаях RPC может быть более предпочтительным вариантом, чаще всего всё равно используют REST. Например, при выполнении какой-то функции, которая изменяет состояние сущности, название этой функции обычно трактуется как подресурс: POST api/requests/{id}/change-status. А в случаях, когда на странице отображается очень много информации, которая, если следовать REST, вытаскивается с помощью большого количества запросов - просто делается один эндпоинт, в рамках которого вытягивается всё что нужно для загрузки страницы.