Putting up Trees for New Year's 2020
Siddharth ShamThe New Year is upon us. It brings with it a whole new decade - full of possibility and hope. Ah well, let's see how things go.
While half my friends were out partying and the other half were asleep, I was busy constructing a tree. Not a tree of the wooden kind, however. A more digitial tree. Yes, my dear technically savvy reader - I am talking about the data structure.
However, the tree that I've been working upon is no normal tree. Rather, it is something called a Patricia Tree - short for Practical Algorithm to Retrieve Information encoded in Alphanumeric. Clearly a backronym. Oh well.
Where It Began
In my quest to find a way to create efficient autocomplete, I was introduced to the humble Trie.
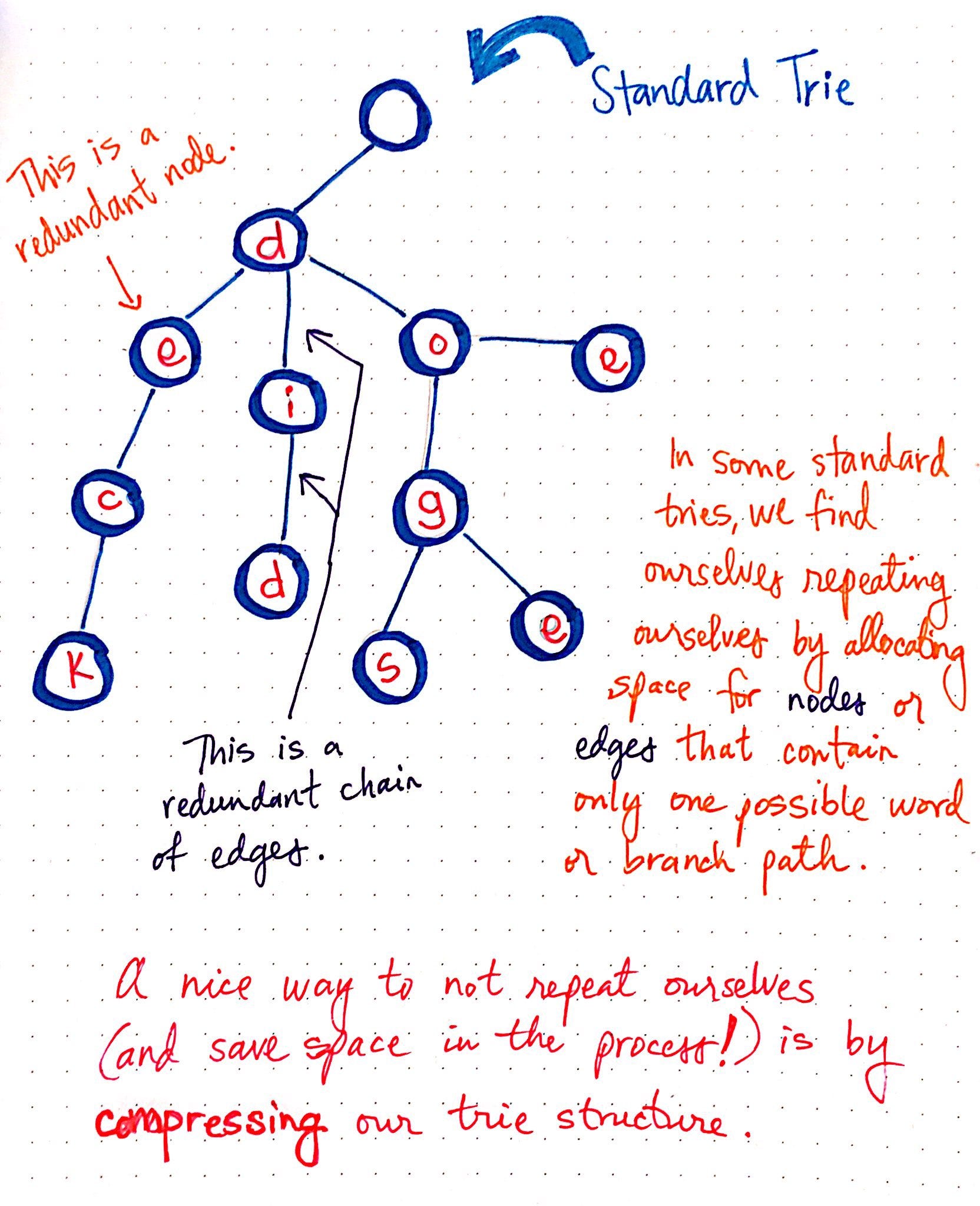
This nifty little data structure is capable of efficiently looking up word completions - far more efficient than a normal O(n) lookup. However, this speed came at a cost - space. Tries aren't space optimised, which was rectified in the Patricia Tree. Yay.
Moving Forward:
This is when I found out about Patricia/Radix trees. Here's an excellent StackExchange answer that highlights the difference between a Trie and a Radix Tree. I immediately fell in love with the elegance of the idea, and decided that I had to implement it. I wasted no time in finding a Python implementation, and was immediately suprised to find a dearth of examples. With perseverance, however, I found this excellent implementation by Justin Peel, from an ancient StackOverflow thread. I also found this one by the Google team. However, this was overkill for what I needed, and I found it hard to wade through the complete code, despite it being commented very well.
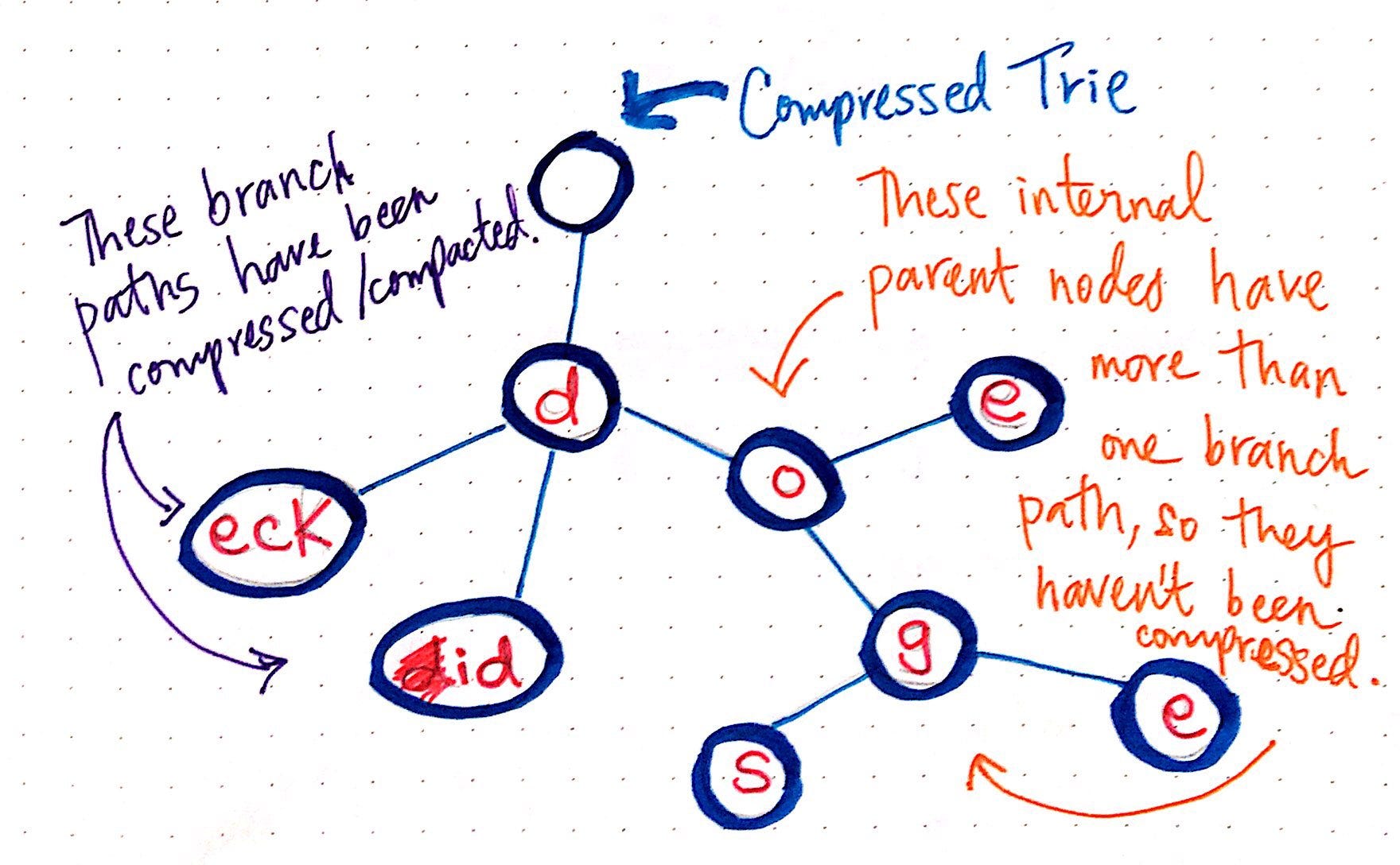
In the face of these hurdles, I thought it prudent to write my own implementation of a Radix Tree. With much effort over the course of a day, I have managed to implement the functionality of adding a word to the tree, and reading the contents of the tree. In my case, this forms the bulk of the problem. I shall eventually get around to adding the functionality of removing words from the tree, at which point it would become a complete Data Structure. As of now, I can simply rebuild the tree with the updated vocabulary.
Was It That Simple? No, Not Really...
My implementation of the tree relies on the concept of recursion - calling a function from within itself. This approach greatly simplifies the problem by breaking it down into smaller chunks, but it comes at the cost of scalability. Python has an inbuilt recursion limit of 1000 recursive function calls, but can be modified if required.
However, for the case of storing words, I believe I'm safe, as it would be an extremely rare case of exceeding 1000 calls. Hence, I shan't worry about it for now.
The Innovation
The idea of combining Deep Learning with this tree structure is what makes this special. At each node of the Radix Tree, I attach a Neuron object - a black box that takes in a vector and a symbol as input, and provides the next traversal step, and an incremented symbol as output.
For reference, here is what a standard Deep Neural Network looks like:
The first step in implementing this Neuron class would be a statistical approach - add all the words over a large corpora, and assign frequency to each node. The idea is simple - higher frequency nodes are likelier to be traversed. For example, the word the would appear more than the word thesaurus, hence making it more likely to be typed by the user.
However, the problems with this approach is that it does not understand context and will always provide the same suggestions for a given set of characters. To overcome this problem, we would ideally train the model to take into account context vectors in the form of Word Embeddings. This gives the model the ability to take into account the context of the word being typed, hence providing a dynamic and intelligent suggestion for autocomplete.
An added advantage of this model is performance. Since at each timestep only one neuron (or atmost, a small number of neurons) provides an output, the prediction becomes logarithmically faster as we near the end of each word.
The Future is Now
A possible extension in the future is using this model for next-word prediction as well. The idea being - since the model becomes faster at the end of a word, we can use precompute the most likely word endings, and pass the context vector to the root of the tree again. In theory, if the model is well trained enough, it should be able to predict the next word to be typed - very efficiently. This could be recursively done until the model's confidence diminishes to a point where it is less than 50% sure of a word being typed.
Possible Implementations of the Neuron Class
This being the most crucial part of this project, I have pondered over various approaches to implement the Neuron class. In theory, using a attention-based Transformer model with frequency/softmax determined biases would be the most efficient and accurate model.
Transformer-Softmax model
Each neuron has three components: Encoder, Decoder, Softmax weight.
The Softmax weights - The easiest component to explain. Since frequency of words does play a significant role in selecting paths, using a fixed weight as the softmax probability of the frequency of each node being traversed is a good idea.
The Decoder - The input vector needs to be transformed into a form that can be used to identify the next nodes to traverse. This can be done with a Transformer architecture Decoder.
The Encoder - Before passing the context vector to the next node, we need to account for the symbol that was just consumed at the current node. So we again use a Transformer architecture Encoder to achieve this.
The Process - The input symbol and the context vector is provided to the Tree. The Decoder present at the Root node of the Tree passes it's output to the Softmax weights. This layer selects the next most probable node through Multinomial Sampling. The updated context vector is then constructed by accounting for the symbol just consumed, and is then passed to the next node.
Final Thoughts
This entire project has helped me in many ways - exercise and sharpen my poor Python skills, expand upon my understanding and appreciation of Data Structures and Neural Networks, and hopefully, will give me the experience of building a working neuron from scratch, without relying on libraries such as TensorFlow and Keras.
Oh, and also,
Happy New Year, folks :D