Путешествие в мир валидации данных: почему это важно?

В 2016 году Tesla Motors была на гребне волны. Их инновационные электрокары вызывали восторг у покупателей, а функция автопилота представляла собой настоящий прорыв в автомобильной индустрии.
Однако с течением времени начали возникать слухи о некоторых проблемах. Несколько аварий, в которых были замешаны автомобили Tesla с активированным автопилотом, вызвали общественное недовольство и требования расследования.
Проводившая расследование команда обнаружила, что искусственный интеллект автопилота не был полностью обучен для ситуаций, которые могут возникнуть в реальной жизни. Более того, валидация данных, которую проводила компания, не была достаточно строгой и не учитывала некоторые важные переменные, такие как нестандартные погодные условия или непредсказуемое поведение других водителей.
Важный момент, который не был учтён, — это отличие между тестовыми условиями и реальным миром. В тестовых условиях часто используются идеализированные ситуации, которые не всегда соответствуют сложности и непредсказуемости дорожного движения.
В результате Tesla была вынуждена провести серьёзную работу над улучшением своего алгоритма автопилота и процесса валидации данных. Они усилили проверки и создали более сложные сценарии для тестирования, чтобы лучше подготовить свою систему к реальности.
Эта история стала ценным уроком важности валидации данных и реалистичного тестирования для всей отрасли автономных автомобилей. Она подчёркивает, что качество данных и их правильная обработка имеют огромное значение в создании надёжных и безопасных систем машинного обучения.
Часть 1: Валидация данных — это ваша страховка
В этом разделе мы расскажем о том, как валидация данных помогает улучшить точность моделей машинного обучения и предотвращает потенциальные проблемы.
Возможно, вы слышали утверждение, что модели машинного обучения хороши настолько же, насколько исходные данные. Но как мы можем быть уверены, что наши данные действительно хороши? Именно здесь на сцену выходит валидация данных.
Валидация данных — это процесс проверки качества исходных данных перед их использованием для обучения модели. Это необходимый шаг, без которого любая модель, даже самая сложная и инновационная, может оказаться бесполезной. Помните, в школе и университете вам давали различные тесты, контрольные и экзамены? Это и была валидация ваших знаний, и умные исследователи данных давным-давно используют её для проверки моделей и качества данных.
Давайте посмотрим на некоторые конкретные способы, которыми валидация данных помогает улучшить наши модели машинного обучения:
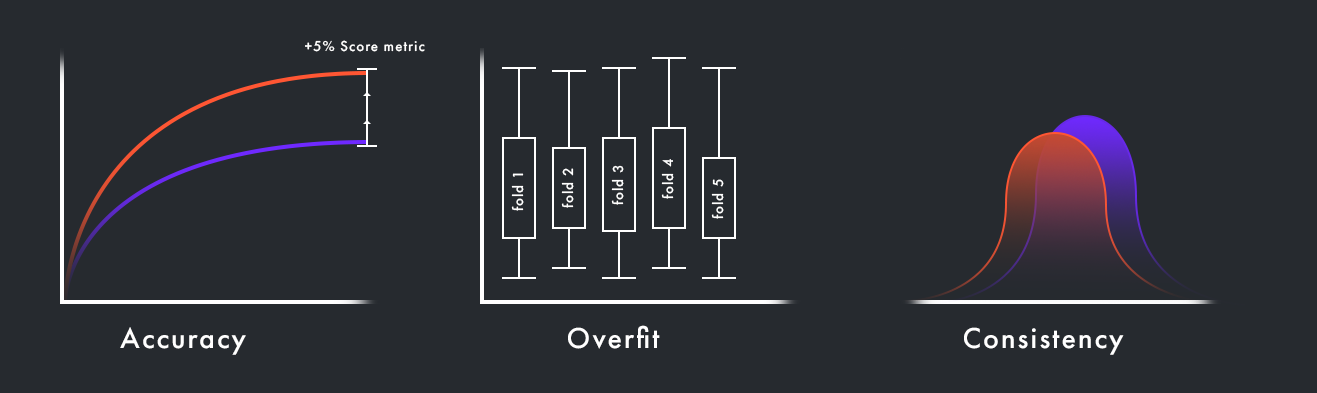
1. Повышение точности: валидация данных помогает обнаружить и исправить ошибки и неточности в данных, такие как опечатки, пропуски и аномалии. Это, в свою очередь, помогает улучшить точность прогнозов модели.
2. Предотвращение переобучения: переобучение — это когда модель хорошо работает на тренировочных данных, но плохо на новых, ранее не виденных. Валидация позволяет разделить наши данные на тренировочные и тестовые наборы, что помогает предотвратить переобучение.
3. Поддержание консистентности: валидация данных также обеспечивает консистентность данных, гарантируя, что все данные соответствуют заданным форматам и стандартам. Это помогает убедиться, что модель получает правильную и полезную информацию для обучения.
Часть 2: Разновидности валидации данных
Давайте рассмотрим три основных метода валидации данных: проверку на отложенной выборке (holdout validation), кросс-валидацию и бутстрап.
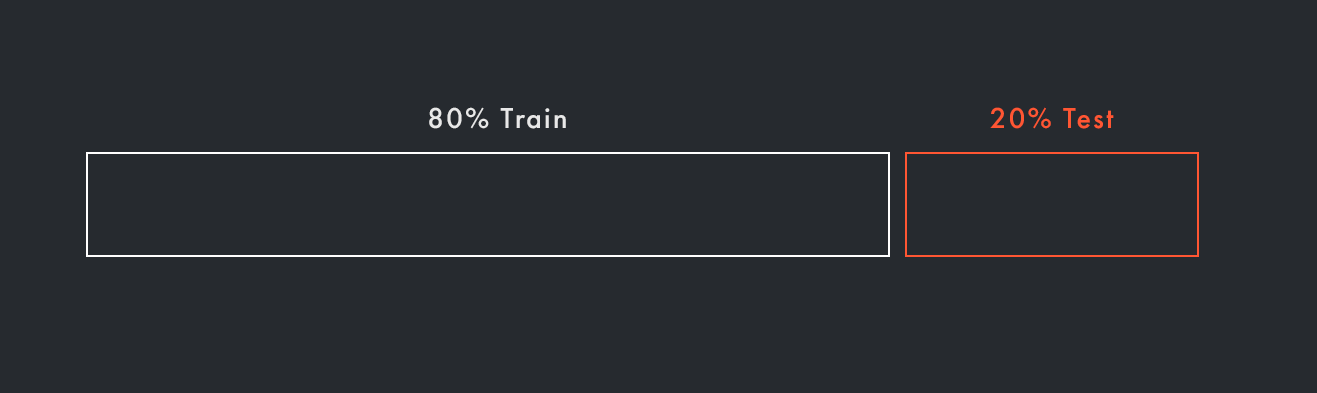
● Проверка на отложенной выборке (Holdout Validation)
В этом методе мы разделяем наши данные на две части: тренировочную и тестовую. Модель обучается на тренировочной выборке, а затем проверяется на тестовой выборке. Этот метод прост, но он может быть недостаточно надёжным, если тестовая выборка не отражает полностью структуру тренировочных данных или если у нас недостаточно данных.
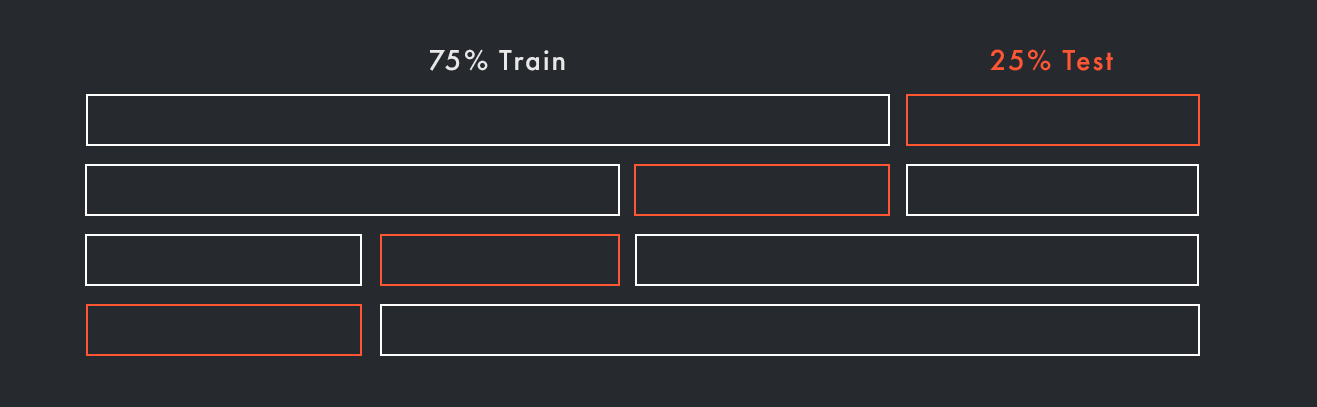
● Кросс-валидация (Cross-Validation)
Как вы уже могли заметить, мы размечаем лишь один небольшой кусочек (20-30%) теста, а все остальные данные, которые ушли в 80% обучения остаются без внимания. В методе k-блочной кросс-валидации мы разделяем данные на k равных блоков. Затем повторяем процесс обучения k раз, каждый раз используя один из блоков как тестовую выборку, а остальные — как тренировочную выборку. Этот метод дает более надёжную оценку производительности модели, а так же проверяет полноту данных.
Кросс-валидацию можно улучшать различными модификациями, разбивать по времени (out of time validation) или по каким-то другим параметрам, либо разбивать на два теста для проверки гиперпараметров.
Мы уже говорили о важности консистентности данных, и в связи с этим стоит упомянуть несколько методов, которые полезны не только для моделей, но и для анализа самих данных. Как бы вы определили, отличаются ли данные внутри ваших валидационных блоков? Есть ли различия между вашими обучающими (train) и тестовыми (test) данными? Если да, насколько существенны эти различия?
Для ответа на эти вопросы предлагается использовать метод adversial validation. Идея проста: всё, что нам нужно, — это разметить данные бинарным признаком 0 (для обучающих данных) и 1 (для тестовых данных). Затем мы обучаем классификатор (например, градиентный бустинг или логистическую регрессию), чтобы увидеть, сможет ли он обнаружить различия между данными. Если модель показывает, что данные различаются, это указывает на наиболее значимые признаки модели, которые можно преобразовать или удалить.
Одной из наиболее распространенных метрик для определения adversarial validation является AUC-ROC — это мера, которая оценивает, насколько хорошо модель классификации может отличать два класса данных. Значение AUC-ROC варьируется от 0 до 1. Чем ближе значение к 1, тем лучше модель разделяет классы, тогда как значение 0,5 указывает на то, что модель работает не лучше случайного угадывания.
Однако можно также воспользоваться классическими статистическими методами, такими как t-тест Стьюдента, тест Фишера или тест Манна-Уитни и Сиджела-Тьюки для определения схожести распределений данных. Это поможет нам определить «дрифт» данных, то есть существенные изменения в структуре данных, которые могут влиять на работу модели.
● Бутстрап (Bootstrap)
Этот метод основан на генерации множества подвыборок из исходной выборки с возвращением. Скорее всего, вы уже с ним сталкивались: так, например, работает модель random forest. Для каждой случайной подвыборки мы обучаем модель и тестируем её на остальных данных. Метод бутстрапа позволяет нам оценить вариабельность оценки производительности модели. Его также можно использовать и в оценке статистических методов, например, оценить квантили распределений.
Пример из реального опыта: на соревновании Raifhack команда Канапе использовала так называемое семплирование для преобразования распределений двух значимых признаков (которые как раз можно определить на adversial validation или визуально посмотрев на распределения), что дало им преимущество над другими командами и, как результат, 2 место.
Важно помнить, что не существует «лучшего» метода валидации данных для всех случаев. Все зависит от специфики задачи, доступных данных и ресурсов. Отбор и применение подходящего метода валидации данных — это один из ключевых навыков, необходимых для успешного применения машинного обучения.
Часть 3: Резюме и заключение
От надлежащей валидации данных зависит эффективность и точность прогнозирования моделей машинного обучения. Помимо того, что валидация данных помогает улучшить качество наших моделей, она также служит важной защитой от проблем, таких как переобучение или дрейф данных.
Консистентность и качество ваших данных в значительной степени определяют успех ваших моделей машинного обучения. Без правильной валидации данных вы рискуете создать модель, которая хорошо работает только на тренировочных данных, но не предоставляет полезные прогнозы на новых данных.
Теперь, когда вы обладаете всей этой информацией, пришло время применить её на практике! Попробуйте эти методы на своих данных и моделях машинного обучения. Сможете ли вы улучшить свои текущие результаты? Какие методы оказались наиболее полезными для вас? Поделитесь своим опытом и обсудите свои результаты. И помните, что в мире машинного обучения постоянное обучение и практический опыт —- ключ к успеху! А так же не забудьте подписаться на автора статьи, в его блоге больше интересных постов!
________________________________________________________________________
Стало интересно? Присоединяйтесь к Симулятору ML!