Прячем изображение в спектрограмме звука
BLOCKED
На сегодняшний момент физики под звуком понимают «воспринимаемое слухом физическое явление, порождаемое колебательными движениями частиц воздуха или другой среды».
Звук как физическое явление характеризуется определенными параметрами: высотой, силой звуковым спектром.
Если записать на графике декартовой системы с осями Ox(время) и oY(частота) точки, определенные частотой конкретного звука в промежуток времени n секунд с шагом в 1 секунду, то получится Спектрограмма. Под спектрограммой следует понимать «изображение, показывающее зависимость спектральной плотности мощности сигнала от времени». Иными словами, спектрограмма – это графическое изображение звука. Спектрограмму сформировать можно двумя способами: аппроксимировать как набор фильтров или рассчитать сигнал по времени с помощью оконного преобразования Фурье.
С появлением цифровой возможности обработки звука, открылись новые возможности для стеганографии. Проанализировав спектрограмму любого аудиофайла можем увидеть хаотичное изображение. В данном случае спектрограмма является дополнительным объектом аудиофайла, если сделать акцент на формирование именно спектрограммы, а не звука, а именно сформировать звук таким образом, чтобы на спектрограмме отобразилось нужное нам изображение, допустим, в виде текста.
Для того, чтобы скрыть картинку в спектрограмме нам необходимо выполнить следующий алгоритм: преобразовать картинку в аудиофайл, а затем микшировать полученный звук с исходным файлом.
Преобразование изображения будем осуществлять скриптом на Python. Скрипт– spectrology.py [solusipse - Overview]
sudo apt-get install git python-matplotlib python sox; mkdir stegano; cd stegano; git clone https://github.com/solusipse/spectrology.git; cd spectrology; python spectrology.py hide.bmp -b 10000 -t 18000
Нам необходимо заранее подготовить картинку в формате Windows 24-bit bmp file.
Скрипту можно указать диапазон частот где осуществить размещение изображения. На выходе мы получаем out.wav.
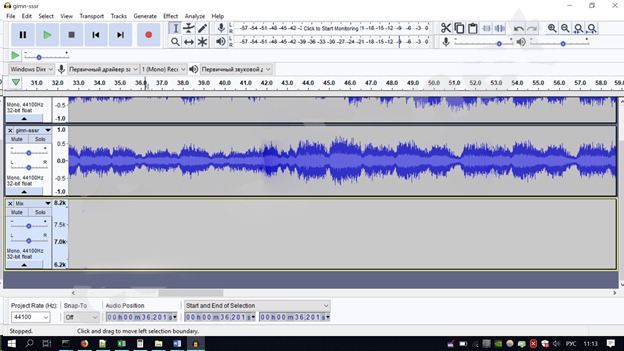
Затем открываем Audacity и помещаем вновь созданный файл в программу. Как мы видим, скрипт создал определенные частотные зависимости.
А на спектрограмме в выбранном нами частотном диапазоне отразилось наше изображение.
Далее мы добавляем исходный аудиофайл, в котором мы хотим зашифровать информацию. Выставляем громкость зашифрованного аудио в минимальную. Выделяем оба трека, затем Tracks->Mix->Mix and render to new track.
На выходе получаем следующий файл.
Но это слишком "палевно". Мы модифицируем этот способ и пойдем дальше.
Можно скрыть изображение только в левом или правом канале либо сделать эту операцию с моно-файлом.
Для обеспечения лучшей анонимности модифицируем данный способ.
- Создадим файл с диапазоном частот 5000 – 10000.
- Загрузим полученный файл и исходный в программу Audacity.
- Преобразуем Stereo исходный файл в mono.
- Копируем в новую дорожку.
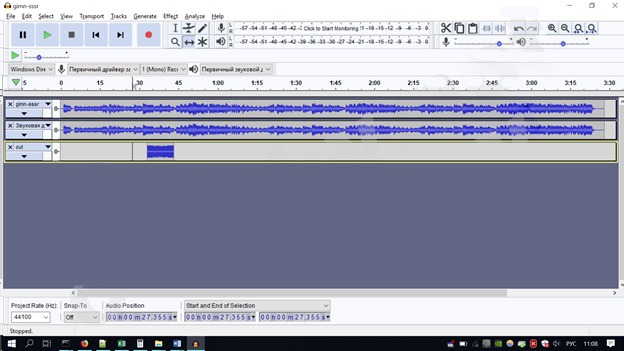
Внедряем изображение в одну из дорожек выставив громкость шифротекста в минимум. Миксуем и рендерим. В итоге получаем две дорожки: оригинал в моно и модифицированное в моно. Сводим в стерео трек, раскидав по каналам, выделяем и микшируем. Получаем зашифрованный файл.
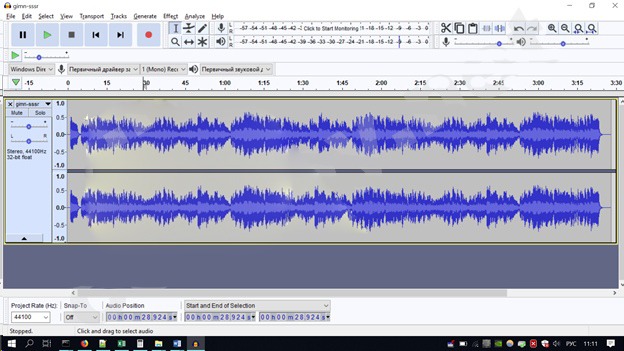
Чтобы расшифровать текст делаем следующее:
Разделяем на моно треки. Инвертируем (Effects->Invert) канал с оригинальным звуком (у нас это левый) и миксуем треки в новый файл. Происходит вычитание аудио информации и у нас остается наше изображение.