Проводим эксперимент
Андрей СуховицкийЧтобы проверить на практике, сколько потребуется потоков в предыдущем кейсе, я написал такой кусочек кода:
class Test {
private val lock = ReentrantLock(true)
private val parallelWorkers = Executors.newFixedThreadPool(1)
fun task() {
parallelWorkers.submit {
var data = prepareData()
process(data)
}
}
private fun prepareData() = lock.withLock {
sum += lock.queueLength
Thread.sleep(5L)
Data(1)
}
private fun process(data: Data) {
Thread.sleep(95L)
}
data class Data(val d: Int)
}
val test = Test()
val start = System.currentTimeMillis()
repeat(1000) {
test.task()
}
println(System.currentTimeMillis() - start)
Результаты нескольких запусков (по 1000 итераций) на различном количестве потоков оказались интересными:
Потоков: 1, Суммарное время: 105729ms (с накладыми расходами около 6s) Потоков: 5, Суммарное время: 21047ms Потоков: 10, Суммарное время: 10605ms Потоков: 16, Суммарное время: 6718ms Потоков: 20, Суммарное время: 6252ms Потоков: 25, Суммарное время: 6259ms Потоков: 32, Суммарное время: 6259ms
До 16 потоков производительность растет практически линейно, а далее остается неизменной при увеличении количества исполнителей.
Напомню, что в предыдущем посте мы воспользовались законом Амдала, чтобы рассчитать количество потоков необходимое для ускорения нашего кода в 10 раз, и получили результат в 20 потоков. А эти измерения говорят, что будет достаточно и 10-11, Давайте попробуем найти какое-то объяснение полученным данным.
Локи, как очередь
Вспомним, что каждая блокировка выстраивает потоки в очередь на доступ в критическую секцию, в этом его суть. Получается, нашу программу можно визуально представить в виде очереди, из которой потоки перемещаются в критическую секцию (наше узкое место, где может в один момент находиться только один поток), а потом потоки перемещаются в пространство где могут независимо и параллельно выполняться.
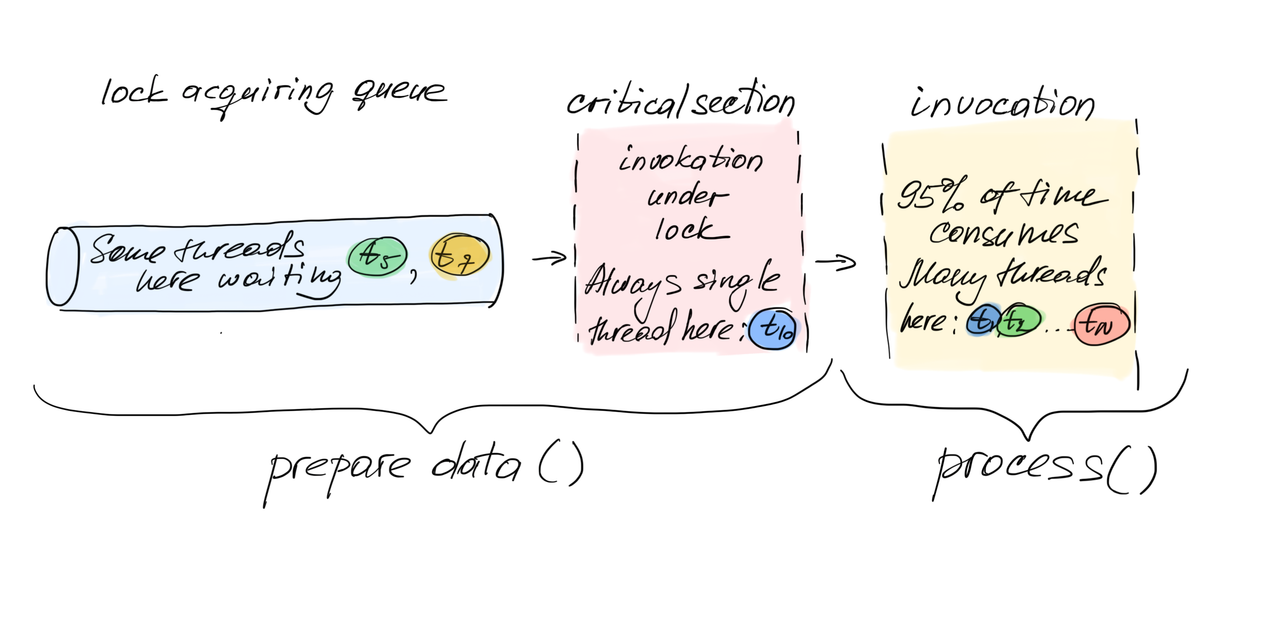
Ранее мы говорили, что выполнение критической секции занимает 5ms, время выполнения оставшегося участка 95ms. Давайте добавим к этому еще одно слагаемое - время ожидания входа в критическую секцию. То есть общее время выполнения функции будет складываться из времени ожидания потока в очереди Tw , времени выполнения критической секции Ts (5ms) и времени выполнения обычного кода Tp (95ms).
Время ожидания в очереди вычислить легко: количество ожидающих потоков (размер очереди) Nt умножаем на время выполнения критической секции: Tw = Nt * Ts. Полное время выполнения функции Ttotal = Tw + Ts + Tp = Nt * Ts + Ts + Tp. В нашем случае получается Ttotal =(Nt * 5ms) + (5ms + 95ms) = (Nt * 5ms) + 100ms
Короче говоря, дополнительно прибавляем временные расходы на ожидание лока. Ведь пока один поток выполняет критическую секцию, другие потоки могут как заниматься полезной работой, так и бесполезно спать в очереди.
Как понять размер очереди? Нам помогает API лока, у него есть метод public final int getQueueLength(), ведь лок ведь в действительности является очередью 🙂
Дорабатываем код, вводим в классе Test счетчик длины очереди и увеличиваем его каждый раз, войдя в критическую секцию. В конце просто разделим суммарное значение на 1000 итераций, чтобы получить средний размер очереди за одно выполнение функции.
var sum: Int = 0 sum += lock.queueLength
Результаты за 1000 итераций:
Потоков: 1, Время: 105729ms , Ср. очередь: 0 Потоков: 5, Время: 21047ms , Ср. очередь: 0 Потоков: 10, Время: 10605ms, Ср. очередь: 0 Потоков: 16, Время: 6718ms, Ср. очередь: 0 Потоков: 20, Время: 6252ms, Ср. очередь: 2,63 Потоков: 25, Время: 6259ms, Ср. очередь: 7.5 Потоков: 32, Время: 6259ms, Ср. очередь: 14,36
Давайте подставим в формулу значение для 20 потоков: Nt * Ts + Ts + Tp = (5ms * 2,62) + 100ms = 113,1ms. То есть к нашим 100 ms выполнения функции в среднем прибавлялось еще 13.1 ms ожидания захвата лока. Время выполнения функции выросло с 100ms до 113.1ms . Но имея 20 потоков, мы можем уменьшить общее время выполнения в 20 раз, то есть получить 5,655ms, а за 1000 итераций будет 5655ms . Прибавив накладные расходы на создания потоков, переключения контекстов и т.д. как раз получаем число довольно близкое к табличному 6252ms.
Ускорение на 25, 32 потоков компенсируется пропорциональным возрастанием очереди. А вплоть до 20 потоков очередь фактически вообще равна нулю и потоки не конкурируют за доступ в критическую секцию!
Практические мысли:
Я не пытаюсь предложить новый способ рассчитывать количество потоков, ведь на практике мы никогда не подсчитываем какая доля кода у нас параллелизуется, а какая нет.
Мне кажутся важными следующие вещи:
1. Стоит всегда держать в голове, что любая блокировка это очередь.
Поскольку эта очередь неявная, мы часто забываем накладывать на нее ограничения и мониторить ее размер.
2. Бывает, мы переоцениваем влияние блокировок на производительность. Иногда логичнее просто использовать блокировку, вместо создания более сложных многопоточных конструкций: во-первых, чем сложнее подход, тем проще допустить ошибку при кодировании, во-вторых, ваши оптимизации могут не принести выигрыш.
3. Такая простая штука, как мониторинг очереди лока может дать вам представление о том, какой вклад он вносит в производительность приложения и есть ли смысл его оптимизировать.
P.S. Для тех, кто дочитал до этого места
Может возникнуть очень много вопросов к моим замерам, буду только рад любым советам и замечаниям.
Вместо Thread.sleep, который я использовал для симуляции работы я еще пробовал такие конструкции для большей утилизации процессора:
val start = System.currentTimeMillis()
while (System.currentTimeMillis() - start < 95) {
count++
}
Результаты были аналогичны, единственное, что очередь было околонулевая аж вплоть до 20 потоков (среднее 0.17)
Вполне могут возникнуть вопросы и к тому, что я делю время ожидания и выполнения критической секции на количество потоков, как будто они линейно масштабируются. Да, в этом подходе издержки учитываются именно в виде времени ожидания в очереди. Однако, когда поток "спит" он почти не занимает процессорное время и дает другим потокам делать полезную работу, поэтому можно считать, что время сна вполне параллелизуется.