Производительность запросов в SQL Server: ошибка #3
Большое количество таблиц
Оптимизатор запросов в SQL Server сталкивается с той же проблемой, что и любой другой оптимизатор: Ему необходимо найти хороший план выполнения при наличии множества вариантов за очень короткий промежуток времени. По сути, он играет в шахматную игру и просчитывает ход за ходом. При каждой оценке он либо отбрасывает кусок планов, похожих на субоптимальный план, либо выбирает один из них в качестве плана-кандидата. Большее количество таблиц в запросе равносильно большей шахматной доске. При значительно большем количестве доступных вариантов у SQL Server появляется больше работы, но определение плана для использования не должно длиться дольше.
Каждая таблица, добавленная к запросу, увеличивает его сложность на факториальную величину. Хотя оптимизатор обычно принимает правильные решения даже при наличии большого количества таблиц, с каждой добавленной в запрос таблицей мы увеличиваем риск неэффективных планов. Это не значит, что запросы с большим количеством таблиц плохи, но мы должны проявлять осторожность при увеличении размера запроса. Для каждого набора таблиц необходимо определить порядок соединения, тип соединения, а также как/когда применять фильтры и агрегацию.
В зависимости от того, как соединяются таблицы, запрос будет иметь одну из двух основных форм:
- Left-Deep Tree: A соединяется с B, B соединяется с C, C соединяется с D, D соединяется с E и т.д. Это запрос, в котором большинство таблиц соединяются последовательно друг за другом.
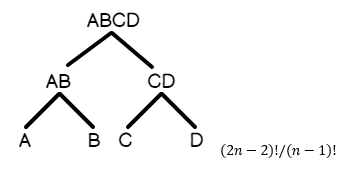
- Bushy Tree: A соединяется с B, A соединяется с C, B соединяется с D, C соединяется с E и т.д. Это запрос, в котором таблицы разветвляются на множество логических единиц в пределах каждой ветви дерева.
На рисунке ниже представлено графическое изображение bushy tree, в котором соединения ведут вверх к итоговому результату:
Аналогично, вот представление того, как будет выглядеть Left-Deep Tree:
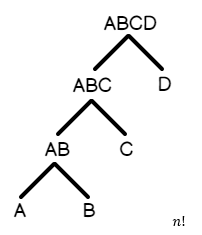
Поскольку left-deep tree более естественно упорядочено на основе того, как соединены таблицы, количество планов-кандидатов на выполнение запроса меньше, чем для bushy tree. Выше приводится математика, лежащая в основе: то есть, сколько планов будет сгенерировано в среднем для данного типа запроса.
Чтобы подчеркнуть масштабность вычислений, в зависимости от количества таблиц, рассмотрим запрос, который обращается к 12 таблицам:
SELECT TOP 25 PRODUCT.ProductID, PRODUCT.Name AS ProductName, PRODUCT.ProductNumber, CostMeasure.UnitMeasureCode, CostMeasure.Name as CostMeasureName, ProductVendor.AverageLeadTime, ProductVendor.StandardPrice, ProductReview.ReviewerName, ProductReview.Rating, ProductCategory.Name as CategoryName, ProductSubCategory.Name as SubCategoryName FROM Production.Product PRODUCT INNER JOIN Production.ProductSubCategory ON ProductSubCategory.ProductSubcategoryID = Product.ProductSubcategoryID INNER JOIN Production.ProductCategory ON ProductCategory.ProductCategoryID = ProductSubCategory.ProductCategoryID INNER JOIN Production.UnitMeasure SizeUnitMeasureCode ON Product.SizeUnitMeasureCode = SizeUnitMeasureCode.UnitMeasureCode INNER JOIN Production.UnitMeasure WeightUnitMeasureCode ON Product.WeightUnitMeasureCode = WeightUnitMeasureCode.UnitMeasureCode INNER JOIN Production.ProductModel ON ProductModel.ProductModelID = Product.ProductModelID LEFT JOIN Production.ProductModelIllustration ON ProductModel.ProductModelID = ProductModelIllustration.ProductModelID LEFT JOIN Production.ProductModelProductDescriptionCulture ON ProductModelProductDescriptionCulture.ProductModelID = ProductModel.ProductModelID LEFT JOIN Production.ProductDescription ON ProductDescription.ProductDescriptionID = ProductModelProductDescriptionCulture.ProductDescriptionID LEFT JOIN Production.ProductReview ON ProductReview.ProductID = Product.ProductID LEFT JOIN Purchasing.ProductVendor ON ProductVendor.ProductID = Product.ProductID LEFT JOIN Production.UnitMeasure CostMeasure ON ProductVendor.UnitMeasureCode = CostMeasure.UnitMeasureCode ORDER BY Product.ProductID DESC;
При 12 таблицах математика будет выглядеть следующим образом:
(2n-2)! / (n-1)! = (2*12-1)! / (12-1)! = 28,158,588,057,600 возможных планов.
Если бы запрос был более линейным по своей природе, то мы бы получили:
n! = 12! = 479,001,600 возможных планов.
Это только для 12 таблиц! Представьте себе запрос на 20, 30 или 50 таблиц! Оптимизатор часто может сокращать эти числа очень быстро, устраняя целые блоки неоптимальных вариантов, но вероятность того, что он сможет сделать это и сгенерировать хороший план, уменьшается по мере увеличения количества таблиц.
Каковы основные способы оптимизации запроса, который страдает из-за слишком большого количества таблиц?
- Переместите метаданные или таблицы в отдельный запрос, который поместит эти данные во временную таблицу.
- JOINы, которые используются для возврата одной константы, можно переместить в параметр или переменную.
- Разбейте большой запрос на более мелкие запросы, наборы данных которых впоследствии можно объединить.
- Для очень часто используемых запросов рассмотрите возможность использования индексированного представления, чтобы упростить постоянный доступ к важным данным.
- Удалите ненужные таблицы, подзапросы и соединения.
Разбиение большого запроса на более мелкие запросы требует, чтобы между этими запросами не происходило каких-либо изменений данных, которые могли бы каким-то образом исказить итоговый результат. Разбиение большого запроса на более мелкие запросы требует, чтобы между этими запросами не происходило каких-либо изменений данных, которые могли бы каким-то образом исказить итоговый результат. Если запрос должен быть целостным, то для обеспечения целостности данных может потребоваться сочетание уровней изоляции и транзакций.
Чаще всего, когда мы объединяем большое количество таблиц вместе, мы можем разбить запрос на более мелкие логические единицы, которые могут быть выполнены отдельно. В примере с 12 таблицами мы можем легко удалить несколько неиспользуемых таблиц и разделить получение данных на два отдельных запроса:
SELECT TOP 25 Product.ProductId, Product.Name AS ProductName, Product.ProductNumber, ProductCategory.Name AS ProductCategory, ProductSubCategory.Name AS ProductSubCategory, Product.ProductModelID INTO #Product FROM Production.Product INNER JOIN Production.ProductSubCategory ON ProductSubCategory.ProductSubcategoryID = Product.ProductSubcategoryID INNER JOIN Production.ProductCategory ON ProductCategory.ProductCategoryID = ProductSubCategory.ProductCategoryID ORDER BY Product.ModifiedDate DESC; SELECT Product.ProductID, Product.ProductName, Product.ProductNumber, CostMeasure.UnitMeasureCode, CostMeasure.Name AS CostMeasureName, ProductVendor.AverageLeadTime, ProductVendor.StandardPrice, ProductReview.ReviewerName, ProductReview.Rating, Product.ProductCategory, Product.ProductSubCategory FROM #Product Product INNER JOIN Production.ProductModel ON ProductModel.ProductModelID = Product.ProductModelID LEFT JOIN Production.ProductReview ON ProductReview.ProductID = Product.ProductID LEFT JOIN Purchasing.ProductVendor ON ProductVendor.ProductID = Product.ProductID LEFT JOIN Production.UnitMeasure CostMeasure ON ProductVendor.UnitMeasureCode = CostMeasure.UnitMeasureCode; DROP TABLE #Product;
Это лишь одно из многих возможных решений, но это способ сократить большой, более сложный запрос до двух более простых. В качестве бонуса мы можем пересмотреть таблицы и удалить все ненужные таблицы, столбцы, переменные и все остальное, что возможно не нужно для возврата искомых данных.
Количество таблиц вносит значительный вклад в плохие планы на выполнение, поскольку оно заставляет оптимизатора запросов просеивать большой набор результатов и отбрасывать больше потенциально верных результатов в поисках оптимального плана менее чем за секунду. Если вы проверяете плохо работающий запрос с очень большим количеством таблиц, попробуйте разбить его на более мелкие запросы. Эта тактика не всегда обеспечивает значительное улучшение, но часто оказывается эффективной, когда другие пути уже испробованы, а в одном запросе много таблиц, которые читаются вместе.
Оригинал статьи: https://www.sqlshack.com/query-optimization-techniques-in-sql-server-tips-and-tricks/