Производительность запросов в SQL Server: ошибка #2
Поиск строк с подстановкой (wildcard)
Сделать поиск по строкам быстрым достаточно сложно. И существует намного больше способов неэффективного перебора строк, чем эффективного.
Для тех столбцов со строками, по которым часто проводится поиск, нужно убедиться, что:
- В искомых столбцах присутствуют индексы.
- Эти индексы возможно использовать.
- Если нет, можно ли использовать полнотекстовые индексы?
- Если нет, можем ли мы использовать хэши, n-граммы или какие-либо другие решения?
Без использования дополнительных возможностей или дизайнерских решений SQL Server плохо справляется с нечетким поиском строк. То есть, если я хочу определить наличие строки в любой позиции в столбце, получение этих данных будет неэффективным:
SELECT Person.BusinessEntityID, Person.FirstName, Person.LastName, Person.MiddleName FROM Person.Person WHERE Person.LastName LIKE '%For%';
В этом строковом поиске мы проверяем LastName на любое появление "For" в любой позиции строки. Когда "%" находится в начале строки, мы делаем невозможным использование любого восходящего индекса. Аналогично, когда "%" находится в конце строки, использование нисходящего индекса также невозможно. Приведенный выше запрос приведет к следующей производительности:
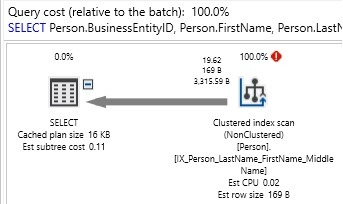

Как и ожидалось, запрос приводит к сканированию Person.Person. Единственный способ узнать, существует ли подстрока в текстовом столбце, - это перебирать каждый символ в каждой строке, ища вхождения этой строки. Для небольшой таблицы это может быть приемлемо, но для любого большого набора данных это будет медленно и мучительно долго.
Существует множество способов решения этой проблемы, в том числе:
- Пересмотрите цель применения такого поиска. Действительно ли нам нужно выполнять поиск с wildcard таким образом? Действительно ли пользователи хотят искать заданную строку во всех частях строки? Если нет, избавьтесь от этой опции, и проблема исчезнет!
- Можем ли мы применить какие-либо другие фильтры к запросу, чтобы уменьшить размер данных перед сравнением строк? Если мы можем фильтровать по дате, времени, статусу или другим часто используемым критериям, мы можем уменьшить объем данных, которые нужно просканировать, до такого количества, чтобы запрос выполнялся достаточно быстро.
- Можно ли выполнить поиск по началу строки вместо поиска по wildcard? Можно ли изменить "%For%" на "For%"?
- Является ли полнотекстовое индексирование доступной опцией? Можем ли мы реализовать и использовать ее?
- Можем ли мы реализовать хэш запроса или n-граммы?
Первые 3 варианта, приведенные выше, являются в равной степени как соображениями дизайна/архитектуры, так и решениями по оптимизации. Они задают вопрос: что еще мы можем предположить, изменить или понять в этом запросе, чтобы повысить его эффективность? Все они требуют определенного уровня знаний о приложении или способности изменять данные, возвращаемые запросом. Для использования этих вариантов очень важно, чтобы все участники процесса были согласны придерживаться правил. Если в таблице миллиард строк, а пользователи хотят часто искать в столбце NVARCHAR(MAX) вхождения строк в любой позиции, то необходимо серьезно обсудить, зачем это нужно и какие альтернативы существуют. Если эта функциональность действительно важна, то бизнесу придется выделить дополнительные ресурсы для поддержки дорогостоящего поиска строк или смириться с большим количеством задержек и потреблением ресурсов в процессе.
Полнотекстовое индексирование - это функция в SQL Server, которая позволяет генерировать индексы, обеспечивающие гибкий поиск строк в текстовых столбцах. Сюда входит поиск с использованием wildcards, а также лингвистический поиск, который использует правила конкретного языка для принятия интеллектуальных решений о том, достаточно ли слово или фраза похожи на содержимое столбца, чтобы считать их совпадением. Несмотря на гибкость, полнотекстовое индексирование - это дополнительная функция, которую необходимо устанавливать, настраивать и поддерживать. Но для некоторых приложений, ориентированных на работу со строками, она может стать идеальным решением!
Последний доступный вариант может стать отличным решением для более коротких строк. N-граммы - это сегменты строк, которые могут храниться отдельно от искомых данных и могут обеспечить возможность поиска подстрок без необходимости сканирования большой таблицы. Прежде чем обсуждать эту тему, важно полностью понять правила поиска, используемые приложением. Например:
- Существует ли минимальное или максимальное количество символов, допустимое в поиске?
- Разрешен ли пустой поиск (сканирование таблицы)?
- Допускается ли использование нескольких слов/фраз?
- Нужно ли хранить подстроки в начале строки? При необходимости их можно собрать с помощью поиска по индексу.
Разобравшись с этими вопросами, мы можем взять столбец со строками и разбить его на сегменты строк. Например, рассмотрим систему поиска, в которой минимальная длина поиска составляет 3 символа, и хранящееся слово "Динозавр". Приведем подстроки слова "Динозавр" длиной 3 символа и более (без учета начала строки, которое может быть получено отдельно и быстро с помощью индексного поиска по этому столбцу): ино, иноз, иноза, инозав, инозавр, ноз, ноза, нозав, нозавр, оза, озав, озавр, зав, завр, авр.
Если бы мы создали отдельную таблицу, в которой хранились бы все эти подстроки (также известные как n-граммы), мы могли бы связать эти n-граммы со строкой в нашей большой таблице, содержащей слово "динозавр". Вместо сканирования большой таблицы для получения результатов, мы можем выполнить поиск соответствия в таблице n-грамм. Например, если я выполнил поиск "дино" с wildcard, мой поиск может быть перенаправлен на поиск, который будет выглядеть следующим образом:
SELECT n_gram_table.my_big_table_id_column FROM dbo.n_gram_table WHERE n_gram_table.n_gram_data = 'Dino';
Если предположить, что n_gram_data индексируется, то мы быстро вернем все идентификаторы для нашей большой таблицы, в которых встречается слово Dino. Таблица n-грамм состоит всего из 2 столбцов, и мы можем ограничить размер строки n-грамм, используя наши правила использования, определенные выше. Даже если эта таблица станет большой, она, скорее всего, все равно обеспечит очень быстрые возможности поиска.
Стоимость этого подхода заключается в необходимости поддержки. Необходимо обновлять таблицу n-грамм каждый раз, когда вставляется, удаляется строка или обновляются строковые данные в ней. Кроме того, количество n-грамм в строке будет быстро расти по мере увеличения размера столбца. В результате, это отличный подход для коротких строк, таких как имена, почтовые индексы или номера телефонов. Это очень дорогое решение для более длинных строк, таких как текст электронной почты, описания и другие столбцы свободной формы или столбцы максимальной длины.
Давайте кратко подытожим: Поиск в строке с подстановочными знаками (wildcards) по своей сути является дорогостоящим. Наше лучшее оружие против него основано на правилах проектирования и архитектуры, которые позволяют либо исключить "%" вначале и конце wildcard, либо ограничить поиск таким образом, чтобы можно было реализовать другие фильтры или решения. Одно из сложных, но возможных решений - использование n-грамм, для случаев, когда другие варианты вас не устроили.
Оригинал статьи: https://www.sqlshack.com/query-optimization-techniques-in-sql-server-tips-and-tricks/