Профилировщик torch.profiler
DeepSchoolАвтор: Александр Лекомцев
Иногда ваш код работает долго, а почему — не сразу понятно. Как выяснить, какие части кода стоит ускорить, а какие работают достаточно быстро? В этом помогают разобраться профилировщики. Профилирование позволяет замерить время работы различных участков кода, чтобы понять где ваша программа тормозит. Стандартные профилировщики типа cprofile могут плохо подходить для специфики DL. Поэтому сегодня расскажем об удобной утилите для профилирования — torch.profiler.
torch.profiler
Встроенный профайлер в торче имеет два варианта — старый torch.autograd.profiler и новый torch.profiler. Старая версия не предоставляет информации об аппаратном уровне и не поддерживает визуализацию. Начиная с версии 1.8.1 можно использовать новую.
Чтобы отобразить информацию о конкретном участке кода, можно использовать метод profiler.record_function (см. Рисунок 1).
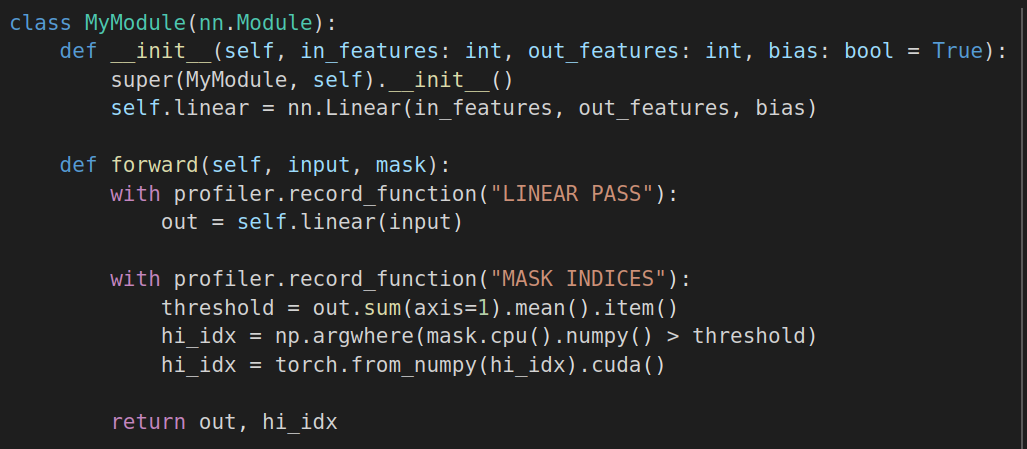
Без использования profiler.record_function информация будет только об операциях копирования, синхронизации и подобных (см. Рисунок 2).
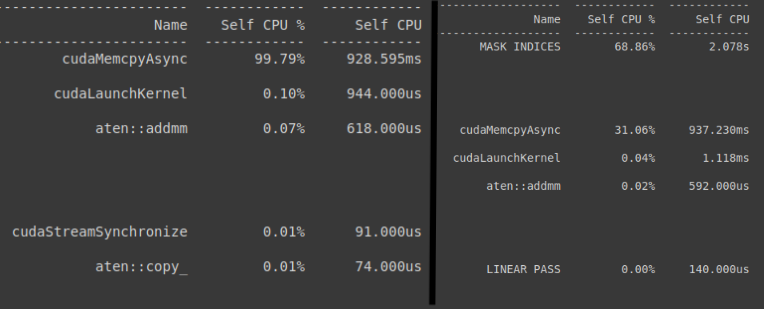
Информация о запуске
На рисунке выше мы обрезали часть столбцов для лучшей визуализации. Полный вывод будет содержать столбцы:
- Self CPU %, Self CPU, Self CUDA %, Self CUDA, — время на выполнение самой функции на cpu и gpu, без учета вызова внутренних функций
- CPU total %, CPU total, CUDA total %, CUDA total — время на выполнение самой функции, с учётом всех вызовов внутренних функций
- CPU time avg, CUDA time avg — среднее время работы за один вызов функции
of Calls — количество вызовов
- Self CPU Mem, CPU Mem, Self CUDA Mem, CUDA Mem — потребляемая память, может быть отрицательной, что говорит об освобождении ресурсов внутри функции
- Source Location — в каком файле и на какой строчке кода находится функция
Проведение замеров
Перед замерами обязательно следует прогнать что-то через сеть, сделав так называемый warm-up (Рисунок 3). Благодаря такому “прогреву” первый долгий forward не повлияет на статистику (почему первый запуск столь долгий можно прочитать в статье в главе “GPU warm-up”).
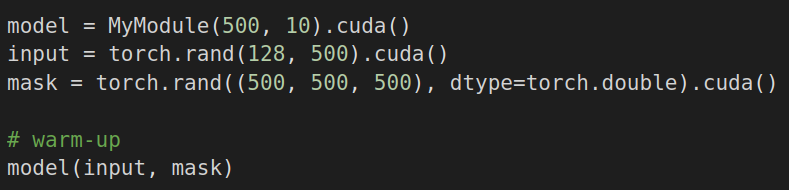
После прогрева можно приступить к замерам. Параметр with_stack добавит столбец Source Location, а profile_memory добавит столбцы с потреблением памяти.

Командой ниже можно вывести таблицу с результатами, как на Рисунке 2. Метод key_averages группирует между собой отдельные вызовы одной функции (по именам) и с параметром group_by_stack_n использует статистику по последним 5 вызовам. Чтобы отсортировать, обрезать и вывести таблицу мы используем метод table. Другие возможности можно посмотреть в документации.

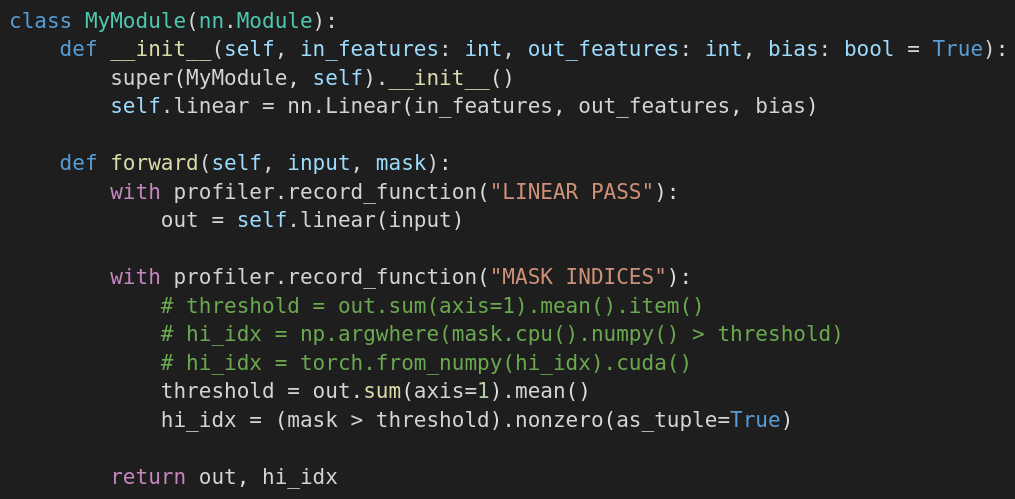
Благодаря профилированию мы заметили, что перекладывание тензора с GPU на CPU и обратно занимает много времени. Поэтому на Рисунке 6 в блоке “MASK INDICES” мы перестали использовать numpy и стали производить все вычисления на GPU.
Tensorboard
Интеграция с tensorboard (tb) делает использование профилировщика ещё удобнее — не нужно открывать трейс в сторонних программах, есть советы по ускорению и видны результаты замеров. Установить плагин для работы с tb можно при помощи pip install torch_tb_profiler.
Чтобы профилировщик сохранил результаты для последующего отображения в tb, необходимо указать параметр on_trace_ready (Рисунок 7).
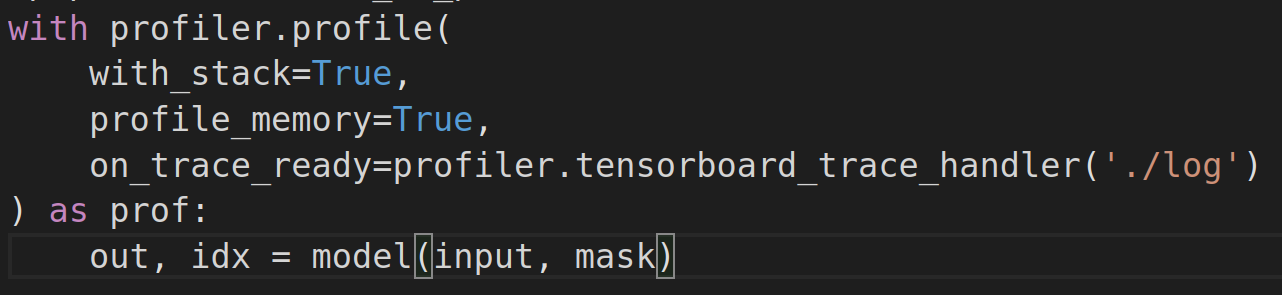
После этого в директории ./log появится json-файл с информацией от профилировщика.
Затем останется лишь запустить tb командой tensorboard —logdir=./log — и тогда по адресу http://localhost:6006/#pytorch_profiler станут доступны результаты.
Ниже перечислим основные возможности, которые предоставляет патч torch_tb_profiler. Полный туториал по использованию Tensorboard с PyTorch Profiler доступен по ссылке.
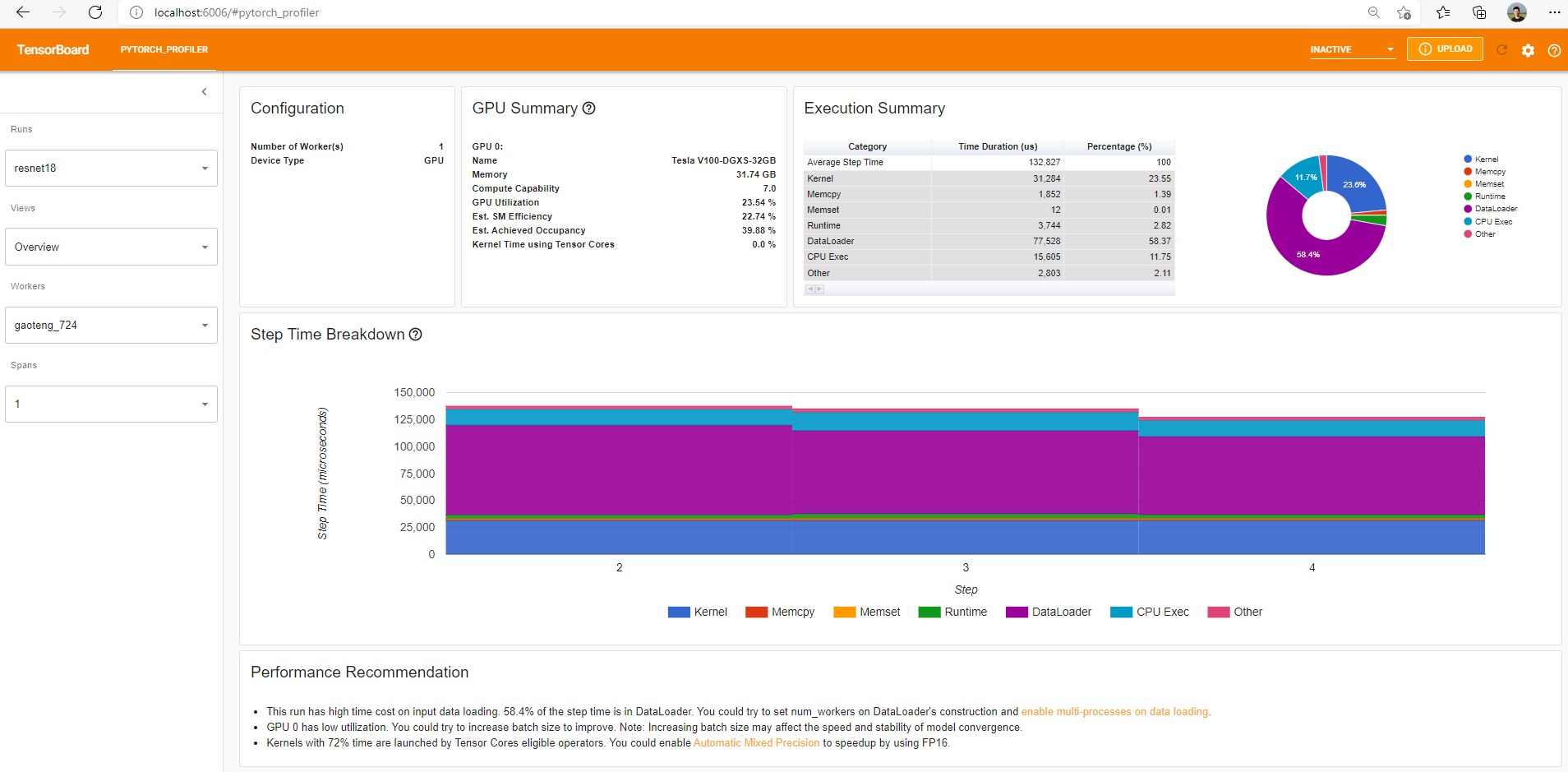
В стартовой вкладке Overview (Рисунок 8) отображается общая информация о работе модели:
- GPU Summary показывает конфигурацию графического процессора и его использование
- Execution Summary высокоуровнево отвечает на вопрос “что занимает время выполнения?”
- Step Time Breakdown используется во время обучения модели и показывает разбивку по шагам обучения и типам нагрузки
Кроме Overview, есть и другие вкладки с дополнительной информацией:
- Operator — статистика по использованию каждого оператора pytorch, такого как nonzero, linear и другие. Дает больше информации о том, на что тратится время при запуске программы.
- GPU Kernel — затраты времени при работе графического процессора.
- Memory — затраты памяти
- Module — общая информация о времени работы модулей, то есть как составных частей сети (Linear, Conv2d, …), так и самих сетей
- Trace — отображает работу операторов и вызов GPU ядер, позволяя отследить когда CPU/GPU простаивает зря и какие операции действительно занимают много времени.
Очень полезна последняя, потому что позволяет визуализировать время, затраченное на каждый шаг. На Рисунке 9 изображена часть вывода вкладки Trace. Красным выделена операция enumerate(Dataloader), которая заставляет синхронизироваться CPU и GPU, что отнимает много времени.
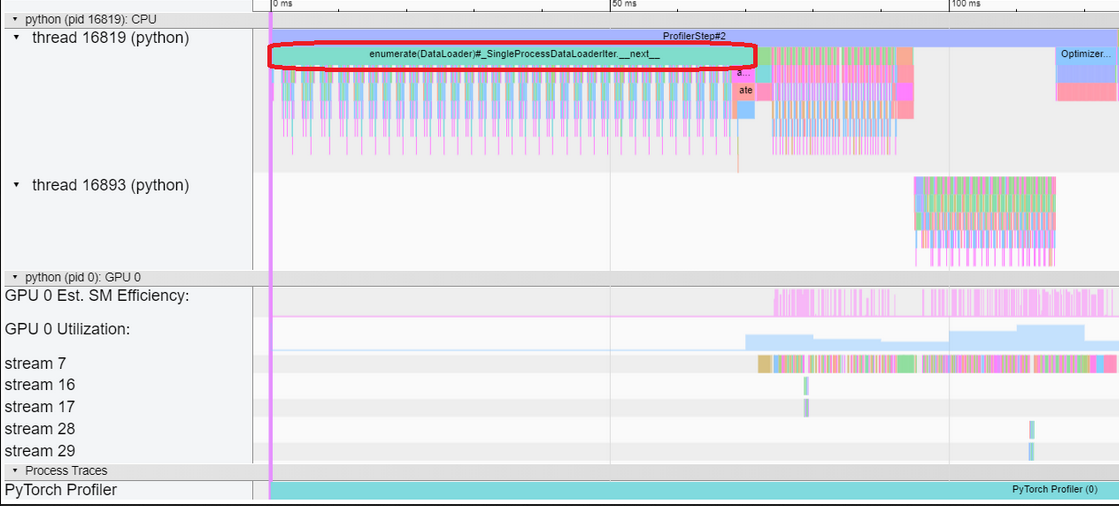
Кстати, в некоторых ситуациях профилировщик дает понять, что в оптимизации нет необходимости. Например, если CPU читает батч картинок 2 секунды, а прогон через GPU с постобработкой занимает 3, то нет смысла ускорять чтение изображений — CPU успеет их прочитать, пока производятся вычисления на GPU.
Итог
Итак, мы узнали:
- как с помощью профилировщика найти ресурсоемкие участки кода;
- какую информацию нам могут дать стандартные средства профилирования в torch;
- как получить доступ к куче информации о запуске в удобном виде через tensorboard и найти bottleneck при обучении или инференсе модели.