Проблемы кэширования с lru_cache
Источник: https://t.me/codeblog8
Источник 2: https://www.youtube.com/watch?v=_pw136PPTKA&t=1s
Небольшие дополнения к видео выше.
Было обнаружено странное поведение lru_cache, который удаляет все значения после переполнения maxsize, в этой статье мы разберемся почему так происходит.
Для начала возьмем следующий код, который переполняет maxsize:
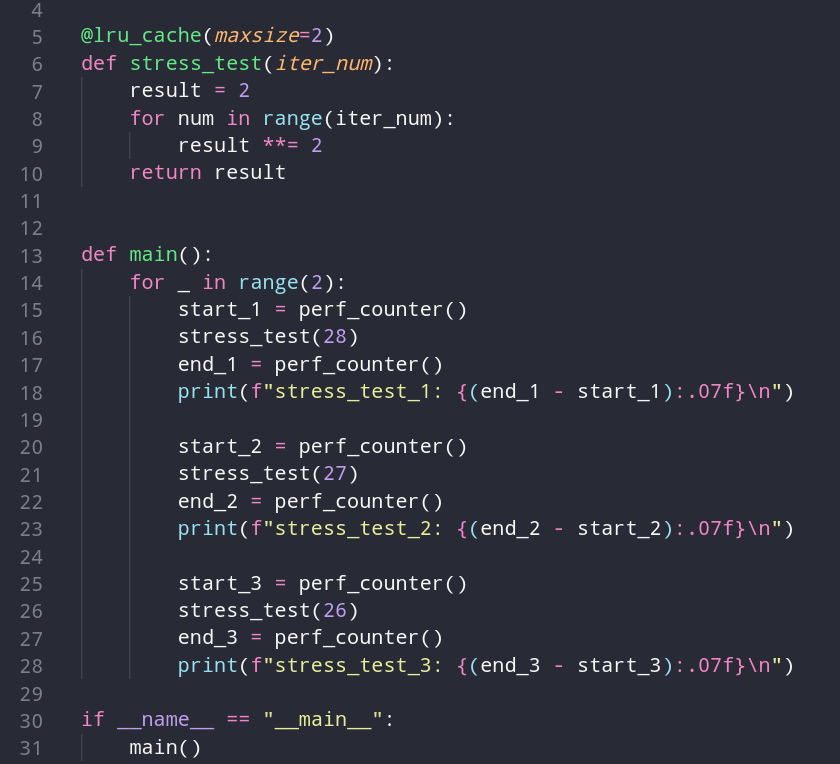
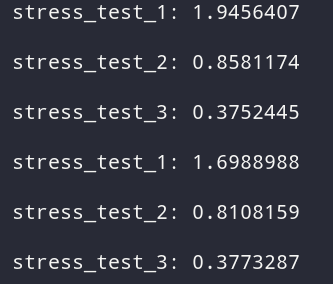
Как можем заметить, все наши значения сбрасываются из кэша, и если мы будем менять maxsize и вместе с ним увеличивать количество значений для кэширования, мы получим такой же результат с полным сбросом всех значений. Но почему так происходит?
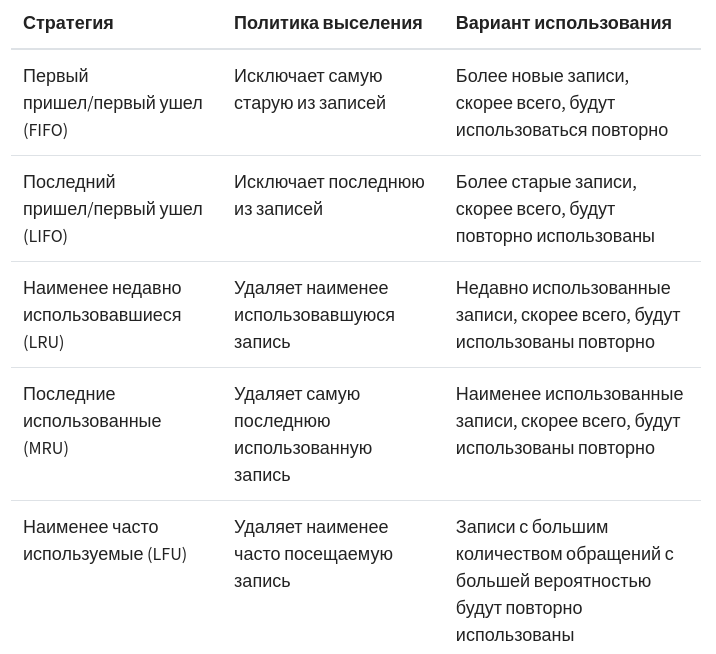
Есть различные стратегии для обработки данных, в данном случае мы можем понять из названия, что в lru_cache используется порядок LRU, который удаляет наименее популярные данные, но почему тогда удаляются все значения?
Дело в том, что мы используем все значения ровно 1 раз, и инструменту не удается определить, какое значение более актуальное, так как все они имеют 1 балл актуальности. Давайте сделаем так, чтобы число 28 запрашивалось 2 раза, это должно привести к тому, что кэш поставит его выше других, сделает цепочку из уровней актуальности, и тогда весь кэш не будет сбрасываться.
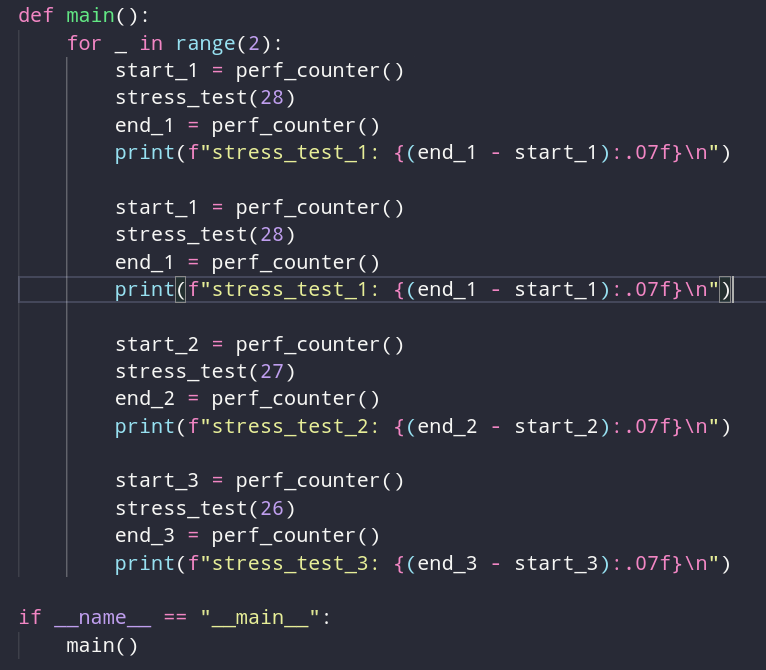
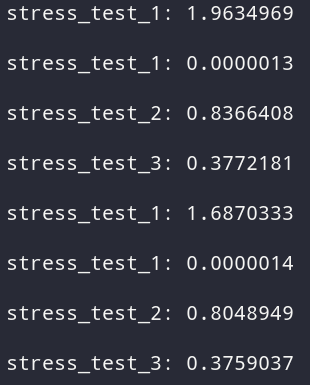
Но тут я обнаружил другой момент. Если делать вызовы подряд, он извлекает их из кэша, но на следующей итерации нужно вычислять значения заново. Но если поставить вызовы одного значения не по порядку, а после вызовов других значений, то все работает нормально. Могу предположить, что следующие 2 вызова с значениями 27 и 26, понижают рейтинг значения 28, что заставляет его упасть ниже в рейтинге.
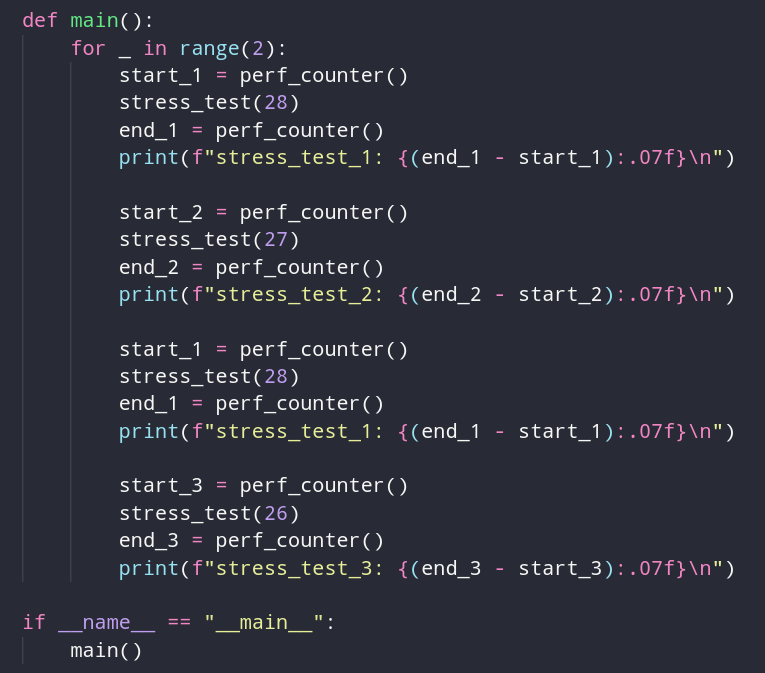
Думаю логика ясна. Другие значения вычисляются заново, так как их актуальность находится на одном уровне. Если накидать много одинаковых вызовов в рандомном порядке, то по идее все будет работать хорошо. Давайте это проверим.

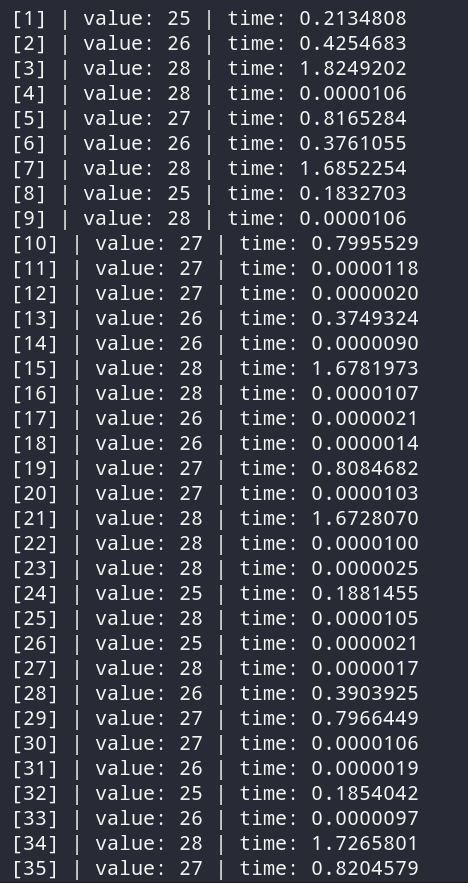
Можно сделать вывод, что сохраняются самые актуальные данные. Устаревшие результаты будут потихоньку удаляться, но удаляются они из конца, начиная от самых старых значений. На lru_cache можно построить что-то вроде системы рекомендации, когда кэшироваться будут только самые популярные ответы, а остальные будут убираться из кэша.