Про сортировку чисел и SIMD
Ioann_V
Небольшое от себя: ситуация, когда недостаток производительности пытаются покрыть новым железом, не редка. Важно понимать, однако, что железо, которое мы использовали и используем сегодня, содержит в себе множество механизмов, способных актуализировать наш код на года вперед. В моем понимании программист, умеющий грамотно оперировать этими механизмами(в частности в терминах бизнес процессов, требующих 'Здесь и Сейчас', терминах поиска золотой середины между Скоростью и Дизайном) - профессионал. В этой статье речь пойдет про довольно изъезженную и, казалось бы, понятную тему - тему сортировок, но с одним небольшим дополнением - SIMD. Эту тему я выбрал не случайно: в процессе решения довольно важной для индустрии задачи возникла следующая подзадача: есть входное множество целых чисел. Каждому множеству сопоставлено свое уникальное значение. При этом множества элементов, которые отличаются между собой только порядком следования элементов, а не их значениями, считаются одинаковыми и должны возвращать одно и тоже значение. Одно из решений - посортировать множества, а затем использовать результат как ключ в Хеш Таблице. Если сортировать, то быстро!
Современные процессоры реализуют так называемый SIMD: принцип компьютерных вычислений, позволяющий обеспечить параллелизм на уровне данных. Например, в случае Intel это SSE AVX расширения, реализуемые набором специальных 128, 256-битных регистров, которые де-факто представляют некоторый 'Массив' значений меньшей размерности(64, 32, 16 и 8 бит соответственно) и инструкции работы с ними(сложить два таких массива в столбик одной командой, например). Таким образом, одной инструкцией мы получаем результат сразу для нескольких входных значений, что при умелом использовании положительно сказывается на производительности алгоритма.
Хорошим кандидатом на использование SIMD выглядит какая-нибудь параллельная сортировка. Одна из самых известных и нам вполне подходящая - Битонная сортировка. И хотя свою долю славы она давно сыскала на различных многоблочных вычислительных устройствах(например GPU), сегодня мы будем рассматривать ее в контексте векторных SIMD инструкций CPU.
Алгоритм Битонной сортировки таков:
На вход подается последовательность чисел, размерность которой - степень двойки.
Первый шаг алгоритма заключается в получении Битонной последовательности из исходной. Битонная последовательность это такая последовательность, которая сначала монотонно не убывает, а затем монотонно не возрастает, либо приводится к такому виду в результате циклического cдвига. Например, последовательность чисел 1, 2, 4, 3 - битонная. Легко заметить, что из определения, любая последовательность, входящая в битонную, любая последовательность состоящая из одного или двух элементов, а также любая монотонная последовательность также является битонной. Каждое множество неотсортированных элементов можно считать множеством битонных последовательностей, состоящих из двух элементов. Сам алгоритм Битонной сортировки предполагает работу с каждой из половин входящего множества элементов.
Чтобы превратить произвольную последовательность в битонную, нужно:
- Разделить последовательность пополам.
- Первую часть превратить в битонную последовательность и отсортировать по возрастанию.
- Вторую часть превратить в битонную последовательность и отсортировать по убыванию.
На втором шаге алгоритма производится слияние полученных половин Битонной последовательности.
Чтобы превратить любую битонную последовательность в отсортированную, нужно:
- Разделить последовательность пополам, попарно сравнить элементы x[i] и x[n / 2 + i], меняя их местами, если элемент из первой половины больше(или меньше).
- Рекурсивно выполнить сортировку над каждой из получившихся половин.
В коде описанный алгоритм можно представить как:
#include <cstdint>
#include <utility>
template
<bool dir>
void compare_and_swap(uint32_t *input_array, uint32_t i_a, uint32_t i_b)
{
if (dir == (input_array[i_a] > input_array[i_b]))
std::swap(input_array[i_a], input_array[i_b]);
}
template
<bool dir>
void bitonicMerge(uint32_t *input_array, uint32_t input_array_size, uint32_t start_ix)
{
if (input_array_size < 2)
return;
const uint32_t half_size = input_array_size >> 1;
for (uint32_t it_b = start_ix,
it_e = start_ix + half_size; it_b < it_e; ++it_b)
compare_and_swap<dir>
(input_array, it_b, it_b + half_size);
bitonicMerge<dir>
(input_array, half_size, start_ix);
bitonicMerge<dir>
(input_array, half_size, start_ix + half_size);
}
template
<bool dir>
void bitonicSort(uint32_t *input_array, uint32_t input_array_size, uint32_t start_ix)
{
if (input_array_size < 2)
return;
const uint32_t half_size = input_array_size >> 1;
bitonicSort< dir>
(input_array, half_size, start_ix);
bitonicSort<!dir>
(input_array, half_size, start_ix + half_size);
bitonicMerge<dir>
(input_array, input_array_size, start_ix);
}
Ассимптотическая сложность Битонной сортировки для худшего, медианного и лучшего случаев - O(N * log(N) * log(N)).
Таким образом, алгоритм начинает свою основную работу с последовательностей длины два, сортируя и наращивая битонные последовательности большей размерности.
Сам алгоритм можно изобразить графически с помощью сортировочных сетей. Ниже изображена сортировочная сеть для входного набора данных из восьми элементов:
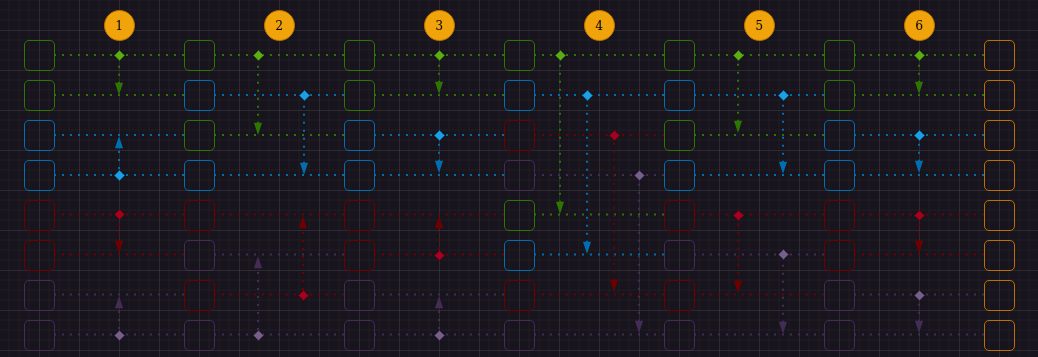
Тем не менее у алгоритма битонной сортировки, описанного выше, есть один существенный для этой статьи недостаток, а именно - компараторы разной направленности(максимум и минимум двух чисел меняются местами в разные стороны). Он легко исправляется изменением индексов сравниваемых элементов и добавлением компаратора, меняющего минимум и максимум только в одном направлении. Таким образом, изображение выше можно представить как:
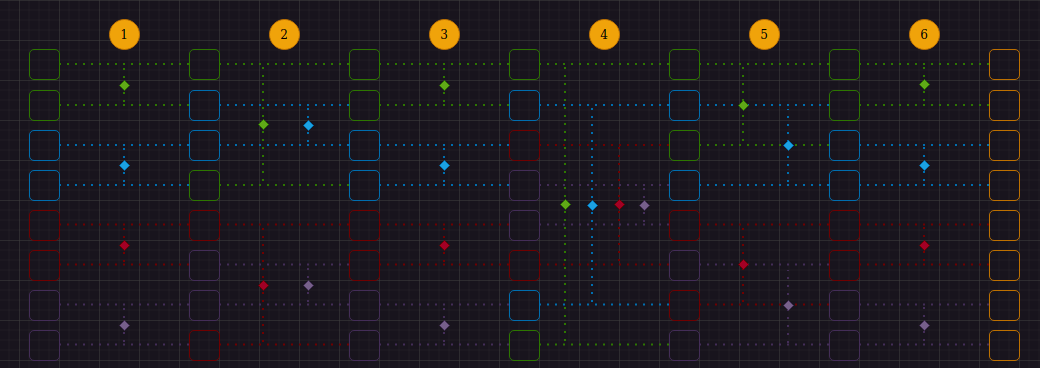
Данное изображение и будет нашей отправной точкой в описании реализации алгоритма Битонной сортировки с использованием SIMD инструкций. Использовать будем Intel AVX. Ниже - подробное, пошаговое описание реализации AVX алгоритма Битонной сортировки для последовательностей из 8 элементов, а также некоторые бенчмарки.
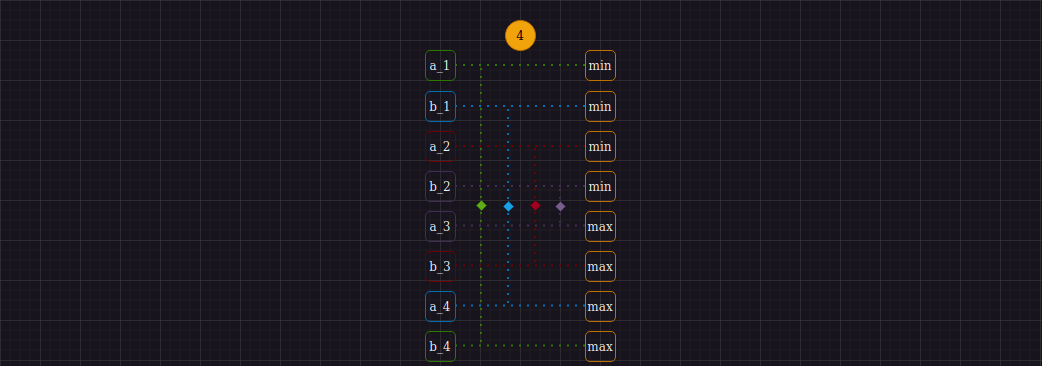
Intel AVX(+SSE) может оперировать 128-ью битными регистрами. Команда _mm_loadu_si128 загружает из памяти 4-е 32-битных целочисленных значения и хранит их в регистре в том же порядке, в котором они идут в памяти. Нам потребуется выполнить две таких команды для загрузки 8-ми 32-ух битных целочисленных значений из памяти прямиком в регистры. Однако порядок загруженных в регистр данных мы будем интерпретировать иначе исходному(линейному). Для понимания причин давайте взглянем на первый шаг алгоритма:
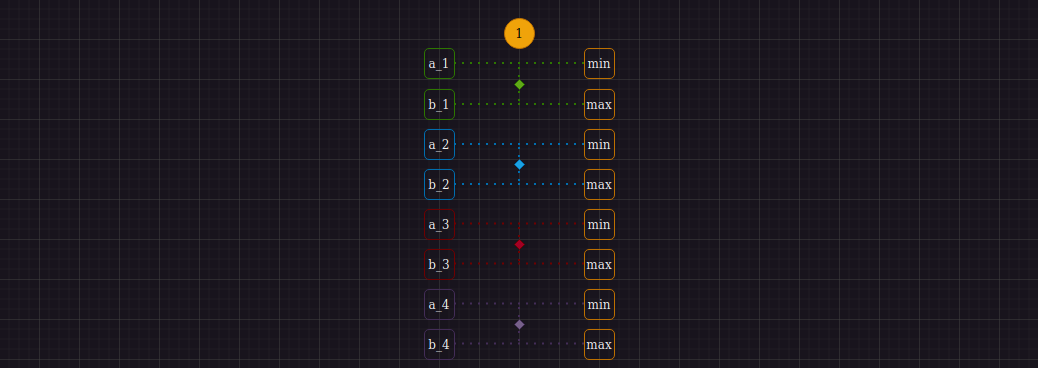
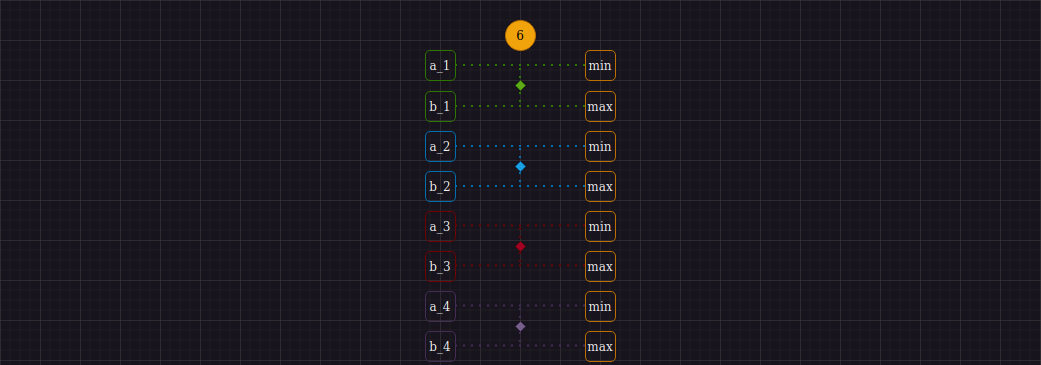
Видим, что для выполнения первой итерации мы должны выполнить 4-е операции сравнения парно идущих двоек элементов исходной последовательности, перемещая минимумы и максимумы на соответствующие шагу 1 индексы. Используя SIMD, мы можем отдельно найти 4-е минимума и 4-е максимума, используя команды _mm_min_epi32 и _mm_max_epi32 соответсвенно. Другими словами, имея два регистра A {a_1, a_2, a_3, a_4} и B {b_1, b_2, b_3, b_4} мы интепретируем данные в них так, как изображено ниже:
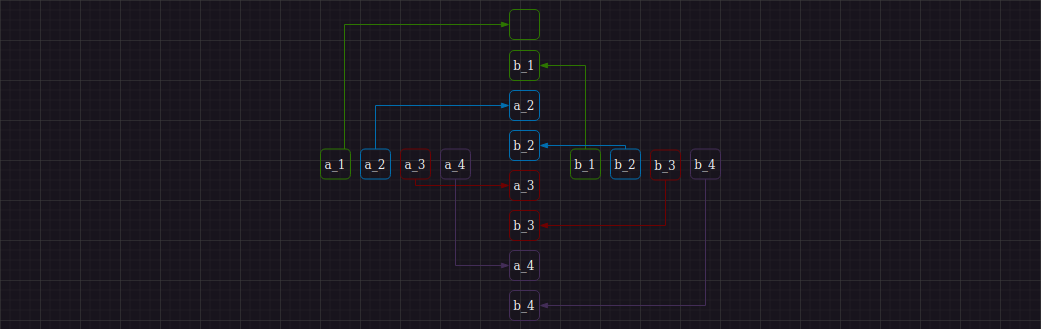
Таким образом, мы можем двумя командами найти нужные нам минимумы и максимумы и перейти к следующему шагу алгоритма. Вообще говоря, поиск минимумов и максимумов - ключевая и неизменная операция, которая понадобится нам на протяжении работы всех шагов алгоритма.
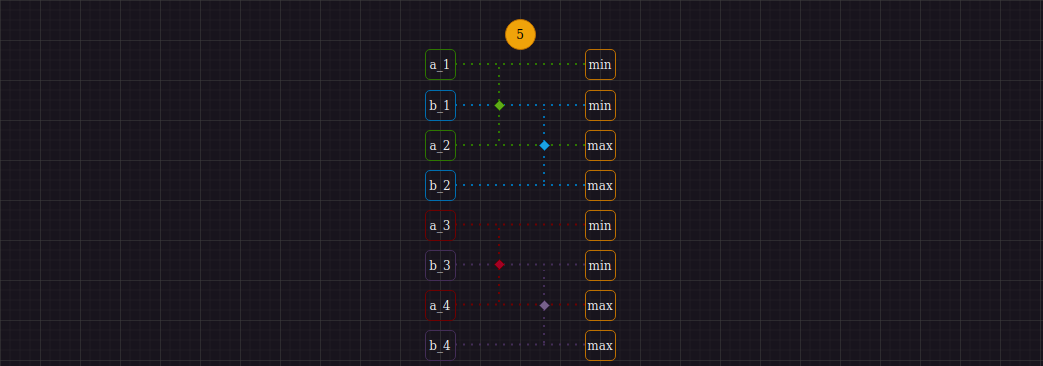
Второй шаг сортировочной сети выглядит следующим образом:
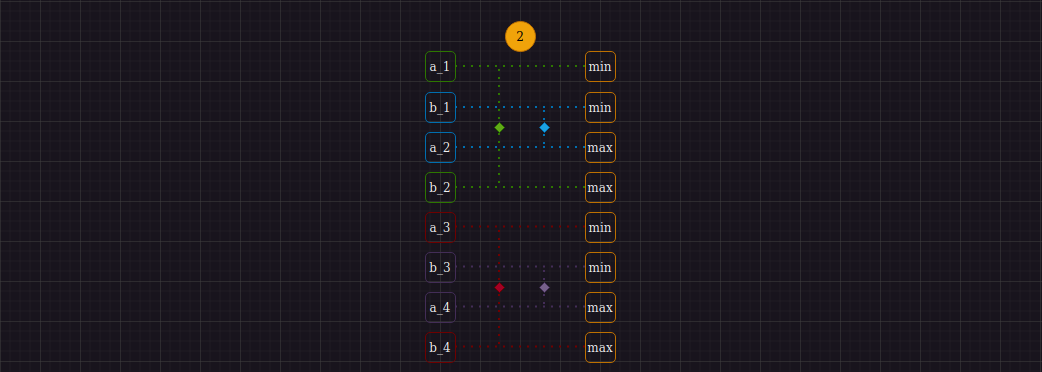
И, как можно заметить, требует некоторых модификаций с одним из регистров, полученных на прошлом шаге, а именно перестановки местами частей регистра B b_1 с b_2, и b_3 с b_4, после чего мы снова сможем выполнить уже привычный нам compare_and_swap(поиск минимумов и максимумов среди двух пар регистров). Для перестановки данных внутри регистра AVX(SSE) предоставляет команду _mm_shuffle_epi32, на вход которой мы подаем регистр, внутри которого выполняем перестановку, а также маску, по которой перестановка происходит. Результат описанных действий можно увидеть ниже:
Стоит также обратить внимание, что после compare_and_swap операции элементы b_1 и b_3 ушли наверх. Так происходит потому, что получившийся верхний регистр содержит минимумы, а нижний - максимумы. Если мы посмотрим на изображение Шага 2 алгоритма, то увидим, что после применения компараторов, b_1 и b_3 и правда содержат минимумы, а a_2 и a_4 - максимумы.
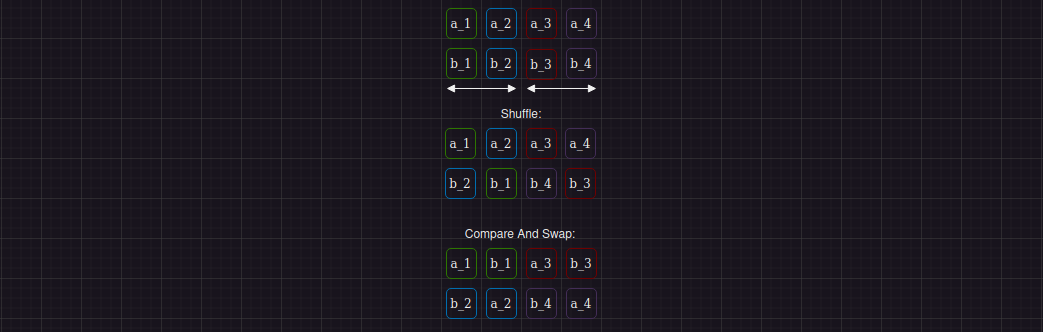
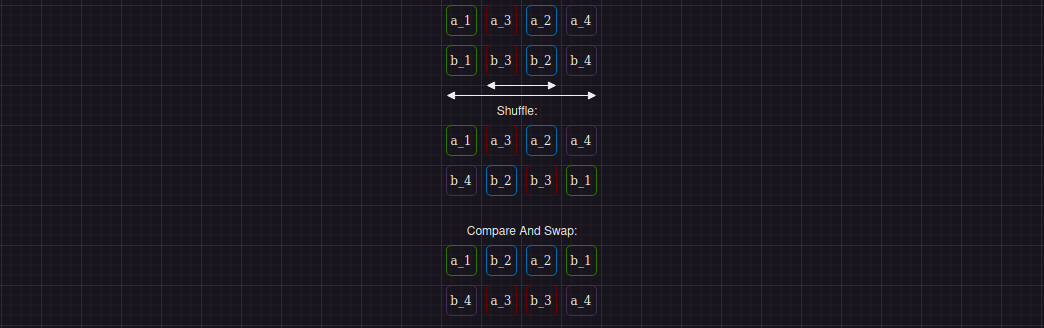
Переходим к третьему шагу:
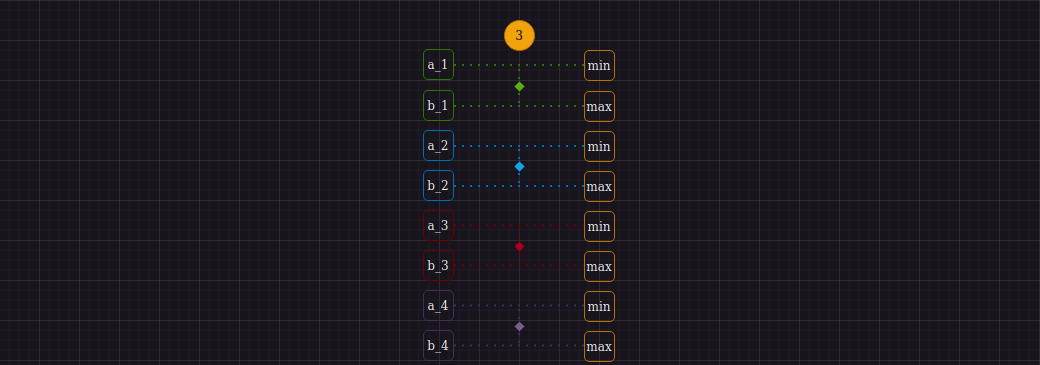
В целом это повторение шага 1, однако перед его выполнением нам снова нужно перемешать данные в регистрах. И если данные внутри одного регистра перемешивались командой _mm_shuffle_epi32, то перемешать и закинуть данные из двух регистров в один можно с помощью команды _mm_shuffle_ps. Особенность этой команды в том, что итоговый регистр смешивания должен в первой половине содержать данные из первого регистра, а во второй половине - второго. Другими словами, во второй половине результата не может быть данных первого регистра, а в первой - данных второго.
Ниже иллюстрация описанного процесса смешивания и применения к нему compare_and_swap операции.
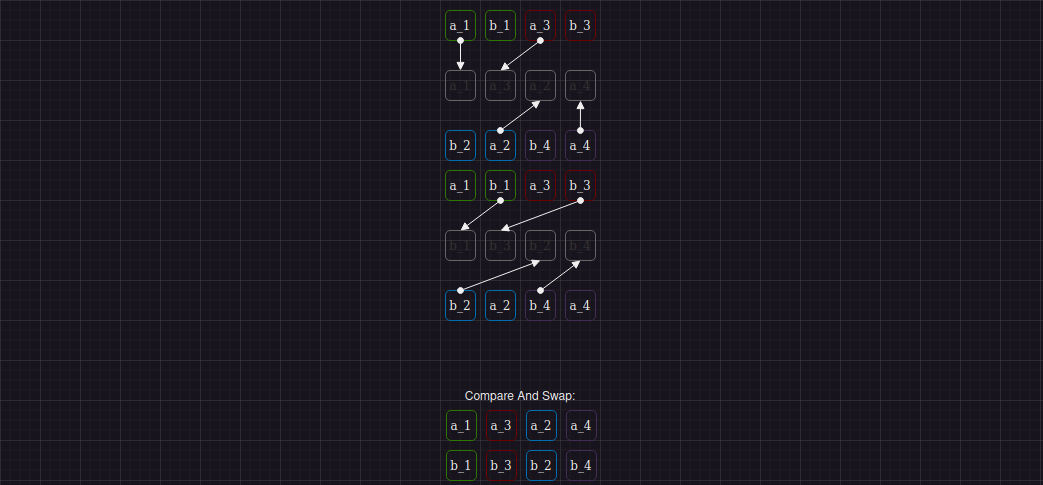
Шаг 4 выглядит так:
Опять же, для его выполнения, нам потребуется аналогично шагу 2 проделать перемешивание элементов внутри регистра с использованием _mm_shuffle_epi32:
Шаг 5:
Необходимые операции перемешивания внутри регистров на шаге 5:
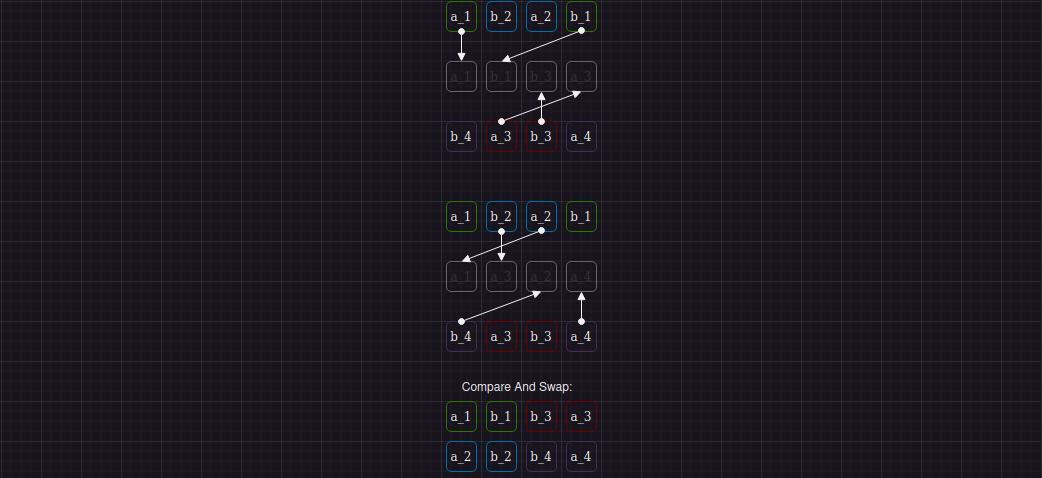
Шаг 6:
Необходимые операции перемешивания внутри регистров на шаге 6:
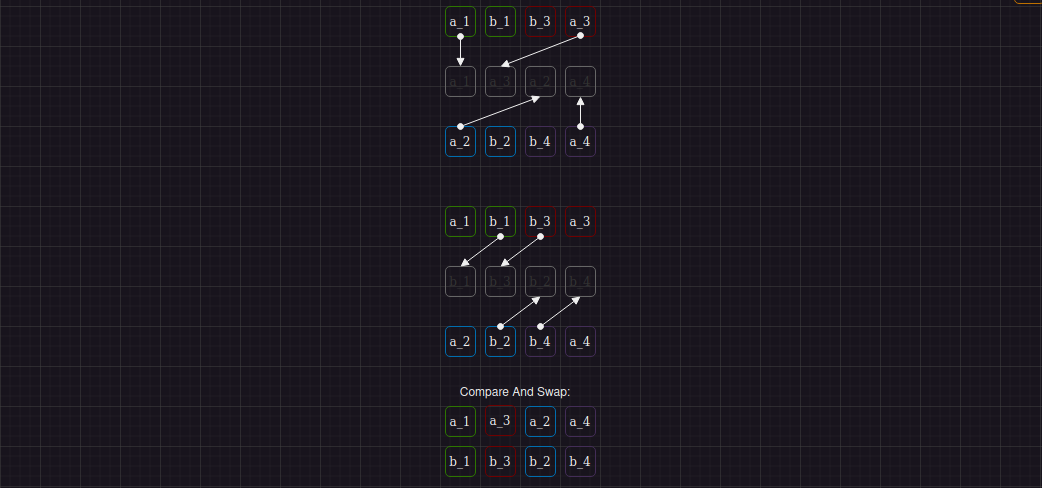
Все шаги проделаны и дело за малым - преобразовать наши регистры так, чтобы при сохранении данных в память они располагались в ней как {a_1, b_1, a_2, b_2, a_3, b_3, a_4, b_4}.Если бы мы выгружали данные из регистров сразу по окончании шага шесть, то только часть элементов находилась бы на нужном месте в памяти:

Выходит, нужно проделать некоторые дополнительные действия, чтобы получить нужный результат. Во-первых, понадобятся временные регистры, в которые мы сохраним результат перемешивания данных внутри исходных регистров таким образом, чтобы вторая группа данных с изображения выше шла на своих местах. Во-вторых, нам потребуется команда блендинга регистров _mm_blend_epi32. Принцип ее работы таков: по 4-ем битам входной маски создается выходной регистр, в котором на i-ой позиции стоят данные либо из первого регистра, если бит маски установлен в единицу, либо из второго, если соответствующий бит равен нулю. Иллюстрация этого процесса изображена ниже:
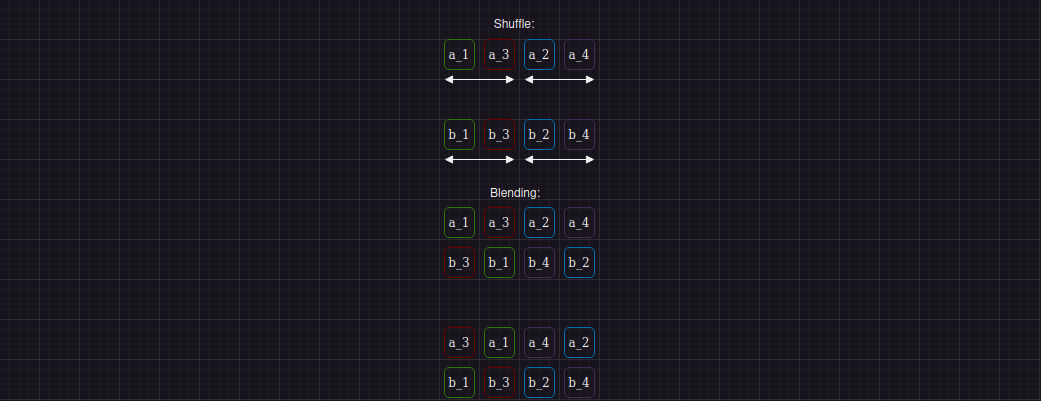
В коде описанный алгоритм можно представить как:
inline void compare_and_swap(__m128i &a, __m128i &b)
{
__m128i c = a;
a = _mm_min_epi32(a, b);
b = _mm_max_epi32(c, b);
}
inline __m128i shuffle_two_vecs(__m128i &a, __m128i &b)
{
return reinterpret_cast<__m128i>(_mm_shuffle_ps( \
reinterpret_cast<__m128>(a), reinterpret_cast<__m128>(b), mask));
}
inline void sort_8()
{
__m128i a = _mm_loadu_si128(reinterpret_cast<__m128i *>(arr));
__m128i b = _mm_loadu_si128(reinterpret_cast<__m128i *>(arr + 4));
/* шаг 1 */
compare_and_swap(a, b);
/* шаг 2 */
b = _mm_shuffle_epi32(b, _MM_SHUFFLE(2, 3, 0, 1));
compare_and_swap(a, b);
/* шаг 3 */
auto t = a;
a = shuffle_two_vecs(a, b, 0b10001000);
b = shuffle_two_vecs(t, b, 0b11011101);
compare_and_swap(a, b);
/* шаг 4 */
v2 = _mm_shuffle_epi32(b, _MM_SHUFFLE(0, 1, 2, 3));
compare_and_swap(a, b);
/* шаг 5 */
t = a;
a = shuffle_two_vecs(a, b, 0b01000100);
b = shuffle_two_vecs(t, b, 0b11101110);
compare_and_swap(a, b);
/* шаг 6 */
t = a;
a = shuffle_two_vecs(a, b, 0b10001000);
b = shuffle_two_vecs(t, b, 0b11011101);
compare_and_swap(a, b);
/* перед сохранением в память - меняем порядок */
auto t_1 = _mm_shuffle_epi32(a, _MM_SHUFFLE(2, 3, 0, 1));
auto t_2 = _mm_shuffle_epi32(b, _MM_SHUFFLE(2, 3, 0, 1));
b = _mm_blend_epi32(t_1, b, 0b00001010);
a = _mm_blend_epi32(a, t_2, 0b00001010);
/* сохраняем данные регистров в память */
_mm_storeu_si128(reinterpret_cast<__m128i *>(arr + 0), a);
_mm_storeu_si128(reinterpret_cast<__m128i *>(arr + 4), b);
}
Итак, выше мы получили SSE версию алгоритма Битонной Сортировки. Полученный алгоритм - inplace сортировка(не требует дополнительной оперативной памяти) реализованная на регистрах.
Настало время самого интересного, а именно бенчмарков. Сравнивать будем получившийся алгоритм для 8-ми элементов с std::sort для 4-ех и 8-ми элементов.
Код google бенчмарка:
#include "benchmark/benchmark.h"
#include <array>
#include <random>
#include <immintrin.h>
static constexpr uint32_t arr_size = 8;
static constexpr uint32_t data_size = 4096;
static constexpr uint32_t num_iters = 1000000;
inline void compare_and_swap(__m128i &a, __m128i &b)
{
__m128i c = a;
a = _mm_min_epi32(a, b);
b = _mm_max_epi32(c, b);
}
#define shuffle_two_vecs(a, b, mask) \
reinterpret_cast<__m128i>(_mm_shuffle_ps( \
reinterpret_cast<__m128>(a), reinterpret_cast<__m128>(b), mask));
inline void sort_8(int *arr)
{
__m128i a = _mm_loadu_si128(reinterpret_cast<__m128i *>(arr + 0));
__m128i b = _mm_loadu_si128(reinterpret_cast<__m128i *>(arr + 4));
/* шаг 1 */
compare_and_swap(a, b);
/* шаг 2 */
b = _mm_shuffle_epi32(b, _MM_SHUFFLE(2, 3, 0, 1));
compare_and_swap(a, b);
/* шаг 3 */
auto t = a;
a = shuffle_two_vecs(a, b, 0b10001000);
b = shuffle_two_vecs(t, b, 0b11011101);
compare_and_swap(a, b);
/* шаг 4 */
b = _mm_shuffle_epi32(b, _MM_SHUFFLE(0, 1, 2, 3));
compare_and_swap(a, b);
/* шаг 5 */
t = a;
a = shuffle_two_vecs(a, b, 0b01000100);
b = shuffle_two_vecs(t, b, 0b11101110);
compare_and_swap(a, b);
/* шаг 6 */
t = a;
a = shuffle_two_vecs(a, b, 0b10001000);
b = shuffle_two_vecs(t, b, 0b11011101);
compare_and_swap(a, b);
/* перед сохранением в память - меняем порядок */
auto t_1 = _mm_shuffle_epi32(a, _MM_SHUFFLE(2, 3, 0, 1));
auto t_2 = _mm_shuffle_epi32(b, _MM_SHUFFLE(2, 3, 0, 1));
b = _mm_blend_epi32(t_1, b, 0b00001010);
a = _mm_blend_epi32(a, t_2, 0b00001010);
/* сохраняем данные регистров в память */
_mm_storeu_si128(reinterpret_cast<__m128i *>(arr + 0), a);
_mm_storeu_si128(reinterpret_cast<__m128i *>(arr + 4), b);
}
const std::array<std::array<int, 8>, 4096> test_data = []
{
std::random_device random_device;
std::mt19937 generator;
std::array<std::array<int, arr_size>, data_size> data;
generator.seed(random_device());
std::uniform_int_distribution<uint32_t> uniform_distribution(0, 1 << 24);
for (int i = 0; i < data_size; ++i)
{
for (int j = 0; j < arr_size; ++j)
data[i][j] = uniform_distribution(generator);
}
return data;
}();
static void bench_sort_bit(benchmark::State& state)
{
for (auto _ : state)
{
for (const auto& elem : test_data)
{
auto tmp_arr = elem;
sort_8(tmp_arr.data());
benchmark::DoNotOptimize(tmp_arr);
}
}
}
BENCHMARK(bench_sort_bit)->Iterations(num_iters)->MinWarmUpTime(1);
static void bench_sort_stl_8(benchmark::State& state)
{
for (auto _ : state)
{
for (const auto& elem : test_data)
{
auto tmp_arr = elem;
std::sort(tmp_arr.data(), tmp_arr.data() + 8);
benchmark::DoNotOptimize(tmp_arr);
}
}
}
BENCHMARK(bench_sort_stl_8)->Iterations(num_iters)->MinWarmUpTime(1);
static void bench_sort_stl_4(benchmark::State& state)
{
for (auto _ : state)
{
for (const auto& elem : test_data)
{
auto tmp_arr = elem;
std::sort(tmp_arr.data(), tmp_arr.data() + 4);
benchmark::DoNotOptimize(tmp_arr);
}
}
}
BENCHMARK(bench_sort_stl_4)->Iterations(num_iters)->MinWarmUpTime(1);
BENCHMARK_MAIN();
Результаты на Ryzen 7 5800H, компилятор GCC 10.:
bench_sort_bit/min_warmup_time:1.000/iterations:1000000 6940 ns 6940 ns 1000000 bench_sort_stl_8/min_warmup_time:1.000/iterations:1000000 186336 ns 186337 ns 1000000 bench_sort_stl_4/min_warmup_time:1.000/iterations:1000000 27400 ns 27400 ns 1000000
Результаты на Intel I5-8265U, компилятор GCC 12.2:
bench_sort_bit/min_warmup_time:1.000/iterations:1000000 14029 ns 14013 ns 1000000 bench_sort_stl_8/min_warmup_time:1.000/iterations:1000000 234728 ns 234364 ns 1000000 bench_sort_stl_4/min_warmup_time:1.000/iterations:1000000 83696 ns 83581 ns 1000000
Результаты на Intel I5-8265U, компилятор Clang 15:
bench_sort_bit/min_warmup_time:1.000/iterations:1000000 16745 ns 16602 ns 1000000 bench_sort_stl_8/min_warmup_time:1.000/iterations:1000000 212830 ns 212484 ns 1000000 bench_sort_stl_4/min_warmup_time:1.000/iterations:1000000 54523 ns 54436 ns 1000000
По результатам видим, что SIMD версия битонной сортировки 8-ми элементов минимум в 16 раз обгоняет C++ STL сортировку, так же обгоняя STL сортировку и для меньшего числа элементов.
Наверное, SIMD одна из тех технологий, используя которую, можно сказать "Зачем платить больше, если можно платить меньше?". Многие начинающие программисты, часто находят интересное в оптимизации простейших алгоритмов по типу memcpy с использлванием SIMD, но эта технология применима и в более комплексных алгоритмах: сортировки, хширование, численные методы, геометрические задачи, работа со строками и т.д
Огромную благодарность хотел бы выразить Игорю Аскарову: человеку, давшему мне огромную мотивацию делать и доделывать до конца, в частности и эту статью.
P.S: А еще у меня есть Хабр: