Про metric learning
МишаВ последнее время я что-то совсем мало делал для канала: переезд в другую страну дело не самое лёгкое. Но теперь опять появились силы что-то сюда написать, так что расскажу вам чем я занимался последние пару месяцев.
На новой работе я всё так же занимаюсь CV, но теперь это метрик лёрнинг и домен больше не медицина.
Что же это за задача такая? Объясняю на картинке, но сразу оговорюсь: под метрик лёрнингом дальше буду только домен картиночек, потому что мне он ближе и чаще под этим термином подразумевают именно его.
Про задачу
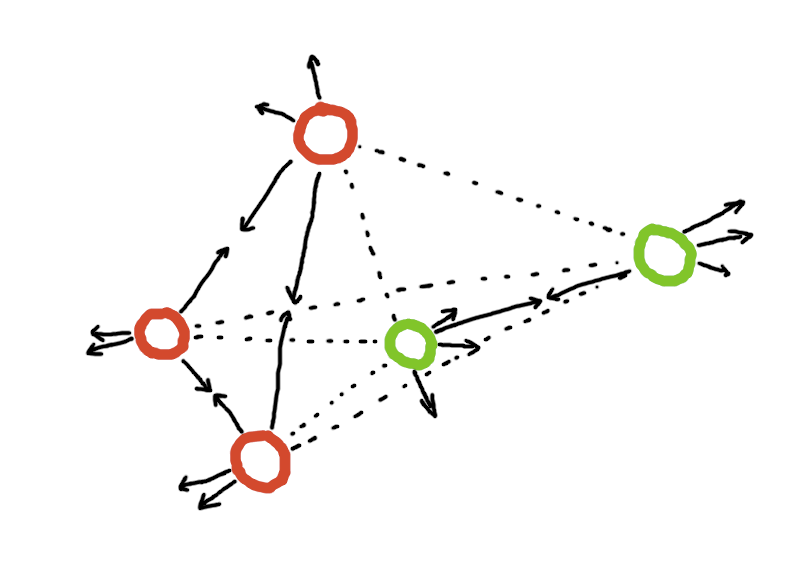
Рассмотрим несколько объектов разных категорий (здесь зелёные и красные). Мы хотим сделать генератор эмбеддингов для объектов, такой, чтобы по выбранной метрике объекты одной категории лежали близко, а объекты разных категорий — далеко. Строго говоря, это не совсем корректное определение метрик-лёрнинга, но наиболее понятное и вполне валидное на практике*.
Сразу встаёт вопрос "почему бы нам не обучить классификатор на два этих класса и просто брать их эмбеддинги?" Всё дело в том, что мы рассчитываем, что может появиться какой-то дополнительный класс, например, синий. В этом случае никто нам не гарантирует, что сетка не положит его в кучу к красным или зелёным объектам. Понять, где же это может использоваться легко вспомнив Google Lens:
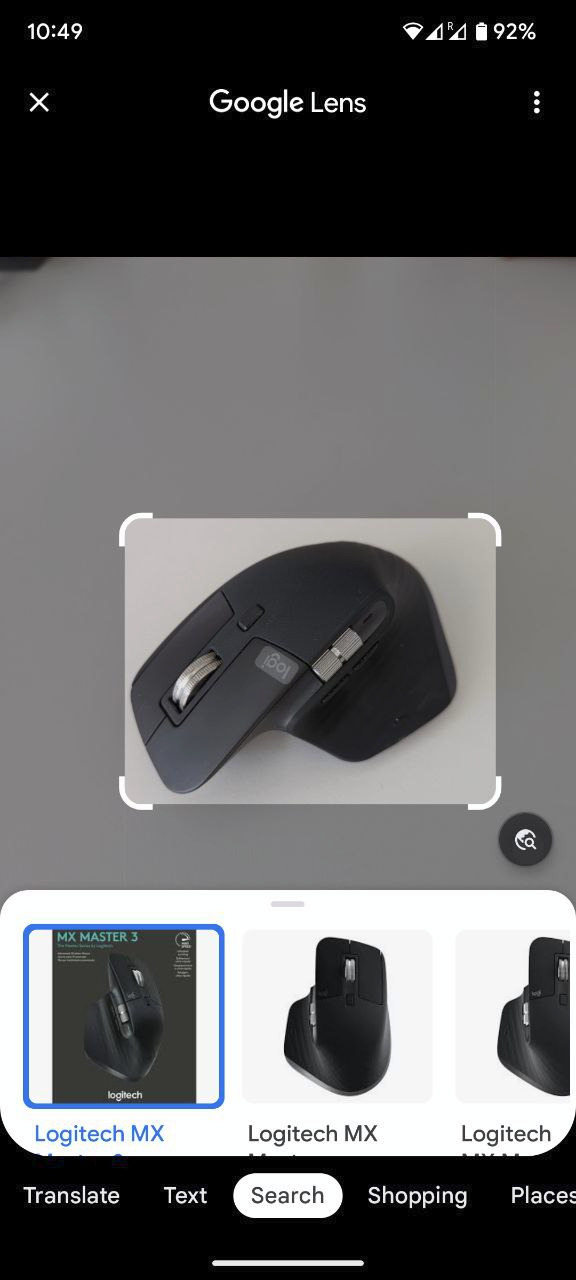
Lens умеет достаточно неплохо находить совершенно разные объекты на картинке: технику, достопримечательности, мебель и так далее. Научить классификатор на такое большое (и постоянно растущее) кол-во классов просто не получится. Другими хорошими примерами использования могут быть ReID, сравнение птичек, поиск похожей одежды и так далее. Таким образом, метрик лёрнинг — это про:
- Поиск ближайших соседей.
- Кластеризацию объектов.
- Снижение размерности (например, превращение картинок в небольшие эмбеддинги).
И, наконец, что (как мне кажется) чаще всего используется на практике:
4. Скормить хорошие фичи объектов в какой-нибудь другой МЛ пайплайн в надежде, что метрики вырастут.
Последнее может быть особенно полезно, если вы не знаете как же использовать картинки ваших товаров в предсказании спроса ;)
Однако, метрик лёрнинг — это не всегда про supervised learning, это ещё иногда и про weakly supervised. В этом случае у нас нет разметки "объект a имеет категорию 1, а объект b категорию 2", мы можем иметь разметку на пары (объекты принадлежат одной категории / разным категориям), триплеты (например, первые два объекта ближе друг к другу, чем к третьему) и так далее.
Наконец, хорошо бы отделить метрик лёрнинг от нескольких очень похожих задач: Self-Supervised Learning и Information (а в нашем случае Image) Retrieval.
С SSL всё понятно: он отличается тем, что это unsupervised задача. С IR разница более тонкая и, я бы сказал, зависящая от цели применения: если мы учим сетку, для того, чтобы в целом считать дистанцию между любыми объектами нашего домена, то это метрик лёрнинг, если же мы хотим для новых изображений искать ближайшие в нашей базе данных, то это уже скорее image retrieval.
Немного про терминологию
Теперь, когда мы немного обсудили формулировку задачи, давайте обсудим классическую терминологию для метрик лёрнинга.
Query — объект, для которого мы ищем похожие в Gallery — наборе объектов, часть из которых похожа на query. Часто для обучения применяется триплет лосс — лосс на трёх объектах, их называют anchor, positive, negative. Anchor — объект для которого ищутся poistive и negative. Positive — объект той же категории, что и anchor. Negative — объект категории, отличной от anchor.
Про метрики
В целом, в метрик лёрнинг сравниваются по некоторым метрикам из IR и ReID: Recall@k (он же Precision@k), MAP@k, CMC@k (был ли релевантный объект среди ближайших k).
Почему-то при этом в метрик лёрнинге принято сравнивать модели по Recall@1 (он же Precision@1, он же CMC@1, он же MAP@1): процент пар query-ближайший объект из gallery, где категории совпадают. Метрика, конечно, хорошо интерпретируемая, но очень шумная, на картинке показано почему.
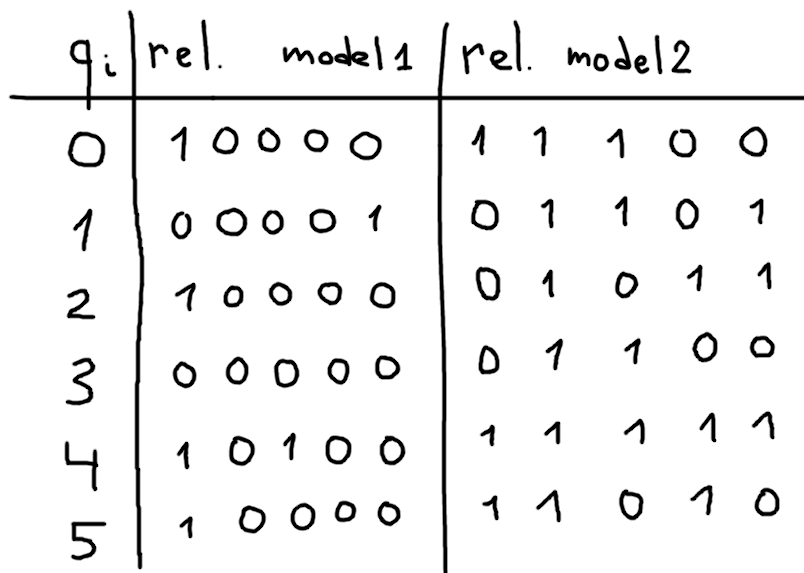
В каждой строке i показаны топ-5 ближайших объектов к query_i, слева направо. Единица обозначает то, что объект той же категории, что и query, иначе ноль.
Для модели 1 R@1 > чем у модели 2, однако интуитивно модель 2 кажется лучше. Такое может случиться, например, из-за шумной разметки.
Поэтому если вы хотите использовать out-of-the-box метрику, стоит использовать хотя бы MAP@k, а ещё лучше — задизайнить свою. Например, если вы хотите показывать юзеру в рекомендациях 3 слота для похожих объектов, то прекрасной метрикой может быть комбинация из P@3 и MAP@4-10: считаем пресижн на первых трёх и взвешенно добавляем к нему мап по урезанному списку: от 4 объекта до 10-го. Таким образом мы не только будем иметь представление о том, сколько релевантных объектов среди наших слотов показала модель (юзер всё равно увидит все три и порядок не так важен), но и немного обращать внимание на то, что идёт после первых трёх объектов (избегать ситуацию с картинкой выше).
Про подходы
Глобально их 2:
- Контрастив
- Классификация
Но если разбираться чуть глубже, то среди контрастив подхода можно увидеть достаточно чёткое разделение на подгруппы по лоссам: парные, триплет и остальные.
Давайте сначала про классификацию, потому что она проще. Метрик лёрнинг как классификация часто использовался для распознавания лиц, поэтому и статьи про него обычно называются *Face: ArcFace, CosFace, SphereFace, ElasticFace, BroadFace, UniformFace, RegularFace, CenterLoss. По сути это всё способы модифицировать классические классификационные лоссы для их применения в метрик лёрнинг, с надеждой, что эмбеддинги выучатся как раз такие, что похожие объекты лежат рядом, не оптимизируя это напрямую. Из статей рекомендую прочитать ArcFace (как одну из наиболее знаковых), CenterLoss (потому что простая идея, которая работает хорошо) и одну из UniformFace / RegularFace (потому что у них в чём-то похожие неплохие идеи). На бенчмарках классификация уже давно уехала куда-то вниз и сейчас не так популярна как была когда-то.
Популярен сейчас контрастив, но если уходить в него глубоко, то тут чёрт ногу сломит: статей миллион.
Как я уже говорил, существует как минимум несколько больших групп по лоссам: основанные на триплетах, основанные на парах и все остальные. Лоссы, основанные на парах пытаются напрямую оптимизировать постановку задачи: если объекты в паре принадлежат одному классу, то мы стараемся притянуть их друг к другу, если наоборот — разнести их как можно дальше. Самый простой и банальный парный лосс буквально делает это:
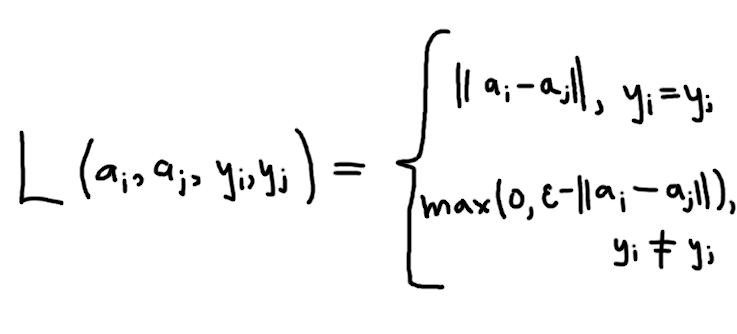
Про терминологию триплетов я так же упоминал выше: у нас есть anchor, positive и negative. Все лоссы этой категории пытаются сделать так, чтобы ReLU(d(a, p) - d(a, n) + ε) был минимальным (здесь d(·, ·) — какая-то дистанция), то есть чтобы дистанция от анкора до позитива была меньше дистанции до негатива.
Как вы наверное заметили, в простых вариациях и парного, и триплет лосса есть какой-то странный гиперпараметр ε, зачем же он нам? Представьте, вы — типичная ленивая сетка, которой не хочется ничего учить, как вам минимизировать лоссы выше, если бы в них не было +ε? Правильно, выдавать абсолютно одинаковые эмбеддинги на всё, в этом случае лосс будет ровно ноль, удобно.
Кроме того, в контрастив-подходах остро стоит проблема формирования триплетов и пар: если давать сетке слишком простые примеры (например, выбирать негативный пример случайно), то ей будет просто и она вряд ли выучит что-то полезное быстро. Для этого в контрастив подходах используется майнинг примеров, то есть подбор хороших триплетов и пар (например, хардмайнинг, когда для случайно выбранного анкора выбирается максимально близкий негативный и максимально далёкий позитивный пример).
Хорошими статьями для погружения в этот подход будут: первая статья про пэйрвайс подход, FaceNet (одна из первых статей про триплет-лосс), N Pairs Loss, Gradient Surgery (+ походить по ссылкам из статьи) и статьи из Metric Learning Reality Check (где автор попытался воспроизвести результаты и оказалось, что не всё так прекрасно). Плюс, совершенно внезапно, рекомендую статьи про SSL (потому что как мы помним self-supervised это тот же метрик лёрнинг, только unsupervised): например, вот эту (из-за мемори-банка), MoCo v2 (из-за моментум энкодера). Ну а если понравилось читать про SSL, то можно ещё SimSiam и то с чем авторы сравниваются (BYOL, SimCLR, SwAV), не то что бы можно оттуда вынести что-то полезное для метрик лёрнинга, но область классная и статьи интересные + вместе с CLIP могут быть использованы как претрейны (ссылка на CLIP для тех, кому ближе видеоформат).
Заметки из практики
Триплет-лосс — работает.
Софт-версия триплет-лосса — тоже, но иногда хуже.
Ауги — ощутимо влияют на качество модели.
Выбор претрейна — критически важно (например, у меня из-за этого не заводился ArcFace: в torchvision в один момент поменялись дефолтные веса для претрейна RN50 и это не давало мне выйти к хорошим метрикам, просадка была 7-8 пунктов).
Хорошие претрейны для ViT — DINO и CLIP.
Сэмлеры и майнеры — очень важно для контрастив подхода. Стоит уделить этому много времени.
Мемори банк — работает (особенно хорошо в сочетании с майнерами).
Не знаете по какой метрике сравниваться — сравнивайтесь по MAP@k.
Размер эмбеддинга может влиять на сходимость вашего подхода, подбирайте с осторожностью.
Разница между хорошим претрейном и файнтьюном на вашем датасете обычно в районе 10-50 пунктов MAP@5, поэтому файнтьюн стоит потраченного на него времени.
Хороший бейзлайн — можно взять в нашей библиотеке, мы много времени потратили на эксперименты и там неплохие дефолты.
Меня заинтересовало, какие библиотеки использовать/какие хорошие статьи по тематике прочитать?
Во-первых, статьи и блоги:
Про контрастив подходы и SSL, здесь написано не только про картинки, но и про текст, и про звук, больше внимания всё-таки уделено unsupervised, но блог очень хороший.
Metric Learning Reality Check — статья, которая когда-то сильно перевернула представление о том, насколько хорошо работают методы из статей про метрик лёрнинг. Уже немножко не новая по меркам области (2020-ый год), но всё равно обязательная к прочтению.
Gradient Surgery — классная статья про то как можно миксовать градиенты в контрастив подходах, беря направление одного и магнитуду другого.
Во-вторых, библиотеки:
Если вы хотите чего-то серьёзного и продакшн-реди, то OML (наша библиотечка) для обучения и, если не хватает лоссов, стырить их из PML. Почему именно так, а не целиком всё в PML/OML? OML появился, когда оказалось слишком сложно встраивать PML в продакшн, но при этом PML более старая библиотека, а поэтому в ней собралось много всего, пока что не имплементированного в OML.
Если же вы хотите учить только последний слой сетки, без твиков всего остального, то Quaterion. Библиотека больше в стиле "обучу на ноутбуке для своего петпроджекта, который в целом вообще о другом, но пусть тут и метрик лёрнинг будет". Кстати, работает и с NLP.
В-третьих, соревнования:
Google Landmark Recognition 2019, 2020, 2021.
Google Universal Embedding 2022 (кстати, не удивлюсь если это для Google Lens).
Facebook AI Image Similarity Challenge.
Заключение
Мерик лёрнинг — прикольная область о которой почему-то не очень много говорят. При этом, для того чтобы использовать какие-то базовые подходы на практике, не требуется много усилий, в то время как результат может быть неплохим.
________________________________________
* Про более корректное определение: поиск параметризации θ метрики F(x, y, θ), такой, чтобы она соответствовала близости объектов x и y в рамках поставленной задачи. Но это в большинстве случаев можно воспринимать как поиск параметризации θ для M(Ф(x, θ), Ф(y, θ)), где M(·, ·) — евклидово или косинусное расстояние, а Ф(·, θ) — нейронка с параметрами θ.