Препарируем Viber. Мини-гид по анализу приложений для Android. Часть 2
https://t.me/xakep_1saruman9
Далее я продолжил исследование и выяснил, что некоторые URL находятся в blacklist — для них preview не создается:
rakuten-viber.atlassian.net;jira.vibelab.net.
$ timeout 5 curl jira.vibelab.net ; echo $?
124
Из любопытства я разрешил создание preview для этих сайтов с помощью Frida:
Java.perform(function () {
let LinkParser = Java.use("com.viber.liblinkparser.LinkParser");
const moduleName = "liblinkparser.so";
const moduleBaseAddress = Module.findBaseAddress(moduleName);
const functionRealAddress = moduleBaseAddress.add(0x0000000000013560);
Interceptor.attach(functionRealAddress, {
onEnter: function(args) {
console.log(`check_link_in_black_list = ${args[0]}`);
},
onLeave: function(retval) {
console.log(`return = ${retval}`);
retval.replace(0);
}
});
})
Но ничего интересного из этого не вышло, доступа нет. Странно, зачем тогда их нужно было блокировать? Этот вопрос я оставил на потом, может быть, есть какой‑то способ получить доступ к этим сайтам со стороны обслуживающих серверов Viber через клиент.
Фаззинг
Потратив определенное время на реверс‑инжиниринг, я пришел к выводу, что глазами и интуицией быстро уязвимость найти не получится, поэтому надо применить другие методы.
Раз времени у нас мало, выбираем единственный, но эффективный способ поиска уязвимостей — фаззинг. Кроме него, конечно, можно применить сразу несколько способов. Например, статический анализ на базе декомпилированного кода с помощью Joern или других инструментов, taint-анализ и анализ, основанный на symbolic и concolic execution опасных функций, которые используются в программе (я обычно пользуюсь встроенными возможностями Ghidra на базе PCode, а также angr, Miasm, BAP и другими). Не следует забывать и о поиске 1-day-уязвимостей в open source коде с помощью анализа binary diffing (я применяю Ghidra Version Tracking и BinDiff, а также ручной поиск в случае хорошего реверс‑инжиниринга кода).
В голову приходит несколько вариантов фаззинга:
- AFL++ в эмуляторе с инструментацией на базе Frida.
- AFL++ на Android-устройстве с инструментацией на базе QEMU.
- AFL++ на хосте с инструментацией на базе QEMU.
- Honggfuzz/AFL++ и QBDI.
- LibAFL в эмуляторе с инструментацией на базе Frida.
Первый вариант не хотелось использовать из‑за предположения, что сборка AFL++ под Android займет много времени (я имею в виду время, которое будет потрачено на изучение процесса, а не на саму сборку того же AOSP).
Рассмотрим второй вариант. У меня имелось тестовое устройство с архитектурой AArch64. Я подумал, что здесь может возникнуть еще больше проблем со сборкой. Кроме того, необходимо было бы собирать обвязку для QEMU для Android AArch64, а последний мой печальный опыт говорил, что сборка обвязки под ARM быстро успехом не увенчается.
Вариант за номером три я рассматривал как второстепенный, об основном я расскажу ниже. Если говорить о варианте четыре, то я не имел опыта работы с QBDI, но каждый раз очень хочу попробовать. Видимо, не в этот раз.
Наконец, пятый вариант. Мне этот вариант показался идеальным по нескольким причинам:
- с LibAFL я уже работал;
- я Rust-разработчик, а значит, проблемы будут решаться быстрее;
- мне казалось, что проблем со сборкой Frida возникнет не много;
- у Rust лучше обстоят дела с кросс‑компиляцией.
Для начала я решил собрать тестовый фаззер, который идет в комплекте с LibAFL. С ходу же у меня возникли проблемы, которых, к чести разработчиков, было мало. Исправлялись они простым патчем:
diff --git a/libafl/src/bolts/minibsod.rs b/libafl/src/bolts/minibsod.rs
index 59f6ae6b..40d8e3d5 100644
--- a/libafl/src/bolts/minibsod.rs
+++ b/libafl/src/bolts/minibsod.rs
@@ -10,7 +10,10 @@ use libc::siginfo_t;
use crate::bolts::os::unix_signals::{ucontext_t, Signal};
/// Write the content of all important registers
-#[cfg(all(target_os = "linux", target_arch = "x86_64"))]
+#[cfg(all(
+ any(target_os = "linux", target_os = "android"),
+ target_arch = "x86_64"
+))]
#[allow(clippy::similar_names)]
pub fn dump_registers<W: Write>(
writer: &mut BufWriter<W>,
@@ -408,7 +411,10 @@ fn dump_registers<W: Write>(
Ok(())
}
-#[cfg(all(target_os = "linux", target_arch = "x86_64"))]
+#[cfg(all(
+ any(target_os = "linux", target_os = "android"),
+ target_arch = "x86_64"
+))]
fn write_crash<W: Write>(
writer: &mut BufWriter<W>,
signal: Signal,
Подобного рода исправления говорят о том, что пользователи нечасто использовали LibAFL на Android x86_64 или вообще не использовали.
Для компиляции LibAFL я взял Android NDK: можно скачать готовый либо собрать самому. Затем я собрал фаззер frida_libpng и успешно его протестировал в эмуляторе.
Harness
С harness все вышло не так гладко, как я ожидал, поэтому я вынес его в самостоятельный раздел.
Продолжительное время я проводил реверс‑инжиниринг, чтобы понять, какую функцию можно вызывать без последствий (то есть для нее не требуется контекст выполнения), и при этом ее было бы интересно фаззить. Все детали реверса кода C++ я тактично опущу, поскольку об этом в интернете и так написано немало. Могу только сказать, что для упрощения работы с инструментами я пользуюсь своими скриптами для Ghidra (также не стоит забывать про собственный мощный репозиторий скриптов Ghidra) и сниппетами для Binary Ninja.
Бо́льшая часть работы с сетью происходит в Java-коде. Но есть та, которая отвечает за обработку данных, полученных от Java-кода (загрузка сайтов для preview). К сожалению, эти функции не представляется возможным как‑то проанализировать в короткий промежуток времени, поскольку вся их инициализация происходит вперемешку с использованием кода на Java. Необходимо время, чтобы реализовать все заглушки при инициализации, а уже потом, например, можно фаззить функции разбора данных. Под общей инициализацией я имею в виду инициализацию парсеров: для каждого типа данных используется свой парсер (встроенные сайты, изображения, метаданные сайта и тому подобное).
Также есть конечный автомат для парсинга HTML. Тело сайта считывается потоком и чанками подается на вход конечному автомату, который определяет, какого типа данные внутри HTML. Затем в зависимости от типа данных вызывается тот или иной экстрактор информации:
BareTitleExtractor;ImgTagExtractor;LinkTagExtractor;MetaTagExtractorи другие.
Всё это весьма интересные цели для анализа, но их сложность и зависимость от Java-кода останавливали меня от попыток проанализировать их.
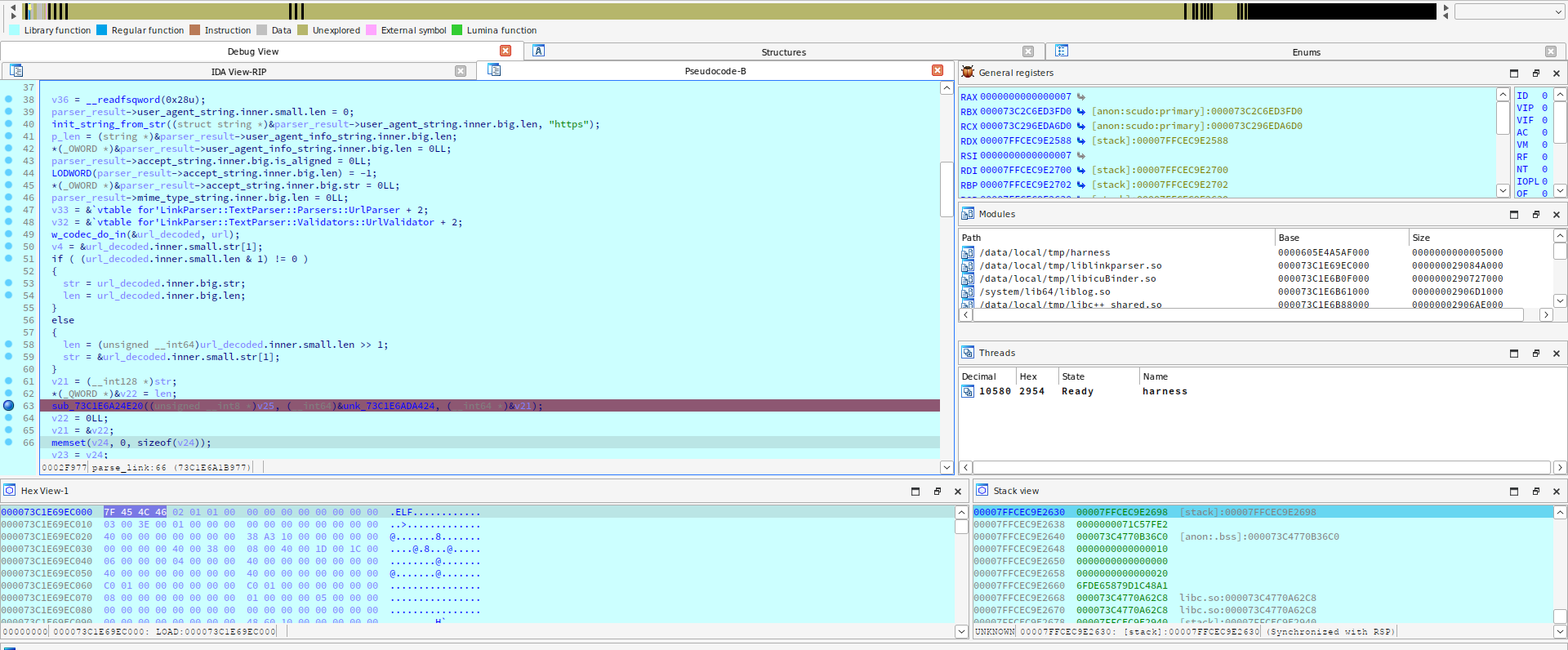
В итоге была найдена функция, которая занимается парсингом URL-строки (parse_link). На первый взгляд, она отлично подходила для анализа и фаззинга.
Приступим к написанию обертки для функции‑цели. Я начал высчитывать и подбирать офсеты необходимых мне функций, затем занимался дополнительным реверс‑инжинирингом нужных структур:
const ptrdiff_t ADDR_JNI_ONLOAD = 0x0000000000011640;
const ptrdiff_t ADDR_PARSE_LINK = 0x000000000002F870;
const ptrdiff_t ADDR_COPY_JNI_STRING_FROM_STR = 0x0000000000011160;
[...]
typedef struct ParserResult
{
struct String user_agent_string;
struct String user_agent_info_string;
struct String accept_string;
struct String mime_type_string;
} ParserResult;
[...]
При анализе я выяснил, что перед вызовом целевой функции инициализируются данные из другой библиотеки — libicuBinder.so. Вот тут я и столкнулся с проблемой, которая отняла у меня практически два дня. В недрах функции parse_link происходит вызов функции uidna_nameToASCII_UTF8 из библиотеки libicuBinder.so. В harness же я, конечно, использовал функции «в сыром виде»:
[...]
Functions *load_functions()
{
LIBC_SHARED = dlopen("/data/local/tmp/libc++_shared.so", RTLD_NOW | RTLD_GLOBAL);
LIBICU_BINDER = dlopen("/data/local/tmp/libicuBinder.so", RTLD_NOW | RTLD_GLOBAL);
LIBLINKPARSER = dlopen("/data/local/tmp/liblinkparser.so", RTLD_NOW | RTLD_GLOBAL);
if (LIBLINKPARSER != NULL && LIBC_SHARED != NULL && LIBICU_BINDER != NULL)
{
int (*JNI_OnLoad)(void *, void *) = dlsym(LIBLINKPARSER, "JNI_OnLoad");
void (*binder_init)() = dlsym(LIBICU_BINDER, "_ZN22IcuSqliteAndroidBinder4initEv");
if (JNI_OnLoad != NULL && binder_init != NULL /* && binder_getInstance != NULL */)
{
Dl_info jni_on_load_info;
dladdr(JNI_OnLoad, &jni_on_load_info);
size_t jni_on_load_addr = (size_t)jni_on_load_info.dli_saddr;
Dl_info binder_init_info;
dladdr(binder_init, &binder_init_info);
size_t binder_init_addr = (size_t)binder_init_info.dli_saddr;
int diff_parse_link = ADDR_PARSE_LINK - ADDR_JNI_ONLOAD;
int diff_copy_jni_string_from_str = ADDR_COPY_JNI_STRING_FROM_STR - ADDR_JNI_ONLOAD;
size_t parse_link_addr = jni_on_load_addr + diff_parse_link;
size_t copy_jni_string_from_str_addr = jni_on_load_addr + diff_copy_jni_string_from_str;
printf("[i] parse_link_addr: %zX\n", parse_link_addr);
printf("[i] copy_jni_string_from_str_addr: %zX\n", copy_jni_string_from_str_addr);
void (*parse_link)(ParserResult *, String *) = (void (*)(ParserResult *, String *))(parse_link_addr);
void (*copy_jni_string_from_str)(String *, const char *) = (void (*)(String *, const char *))(copy_jni_string_from_str_addr);
if (parse_link != NULL && copy_jni_string_from_str != NULL)
{
Functions *functions = (Functions *)malloc(sizeof(Functions));
functions->parse_link = parse_link;
functions->copy_jni_string_from_str = copy_jni_string_from_str;
return functions;
}
[...]
И каждый раз при запуске harness я получал segmentation fault. Для первичного анализа я сначала использовал strace. Мне удалось понять, что libicuBinder.so при вызове функции uidna_nameToASCII_UTF8 выполняет инициализацию, но что‑то идет не так, в результате чего внутри вызываемой функции происходит вызов другой функции по адресу 0. В итоге пришлось реверсить библиотеку libicuBinder.so, как и по части инициализации, так и по части вызова функции uidna_nameToASCII_UTF8.
Затем я сначала попытался отладить эту библиотеку в GDB, потом перешел в IDA (использовал IDA android_x64_server), так как к тому времени уже восстановил часть функций и было бы глупо не использовать эту информацию при отладке.
В итоге я понял, в чем дело. Сначала в системе Android выполняется поиск библиотек, в которых реализовано ICU, затем происходит поиск необходимых символов export функций, чтобы их в дальнейшем использовать (поэтому библиотека и называется Binder). Основу для имен символов библиотека берет изнутри, а вот дополнение (версия ICU) получает с помощью Java-вызова. Именно по этой причине не могли прогрузиться необходимые символы функций. Я добавил в harness модификацию версии в памяти без вызова Java-кода (для каждого system image приходится менять версию, чтобы все работало, в будущем можно, конечно, автоматизировать процесс):
void set_icu_version(ptrdiff_t binder_init_addr)
{
ptrdiff_t diff = g_ICU_VERSION - ICU_SQLITE_ANDROID_BINDER__INIT;
ptrdiff_t version_addr = binder_init_addr + diff;
printf("[i] original ICU_VERSION = %X\n", *(uint32_t *)version_addr);
*(uint32_t *)version_addr = ICU_VERSION;
return;
}
После запуска фаззера с обновленным harness начали случаться многочисленные краши. Стало ясно, что опять что‑то идет не так. В этот раз функция std::codecvt<InternT,ExternT,StateT>::do_in в библиотеке liblinkparser.so кидает исключение из‑за того, что не может создать wide-строку из байтов. Я уже не стал проверять (рекомендую сделать это тебе, читатель), есть ли возможность у атакующего отправлять сырые байты в виде сообщения или нет, а просто исправил фаззер, чтобы тот генерировал валидные данные UTF-8.
Эксперименты и улучшения
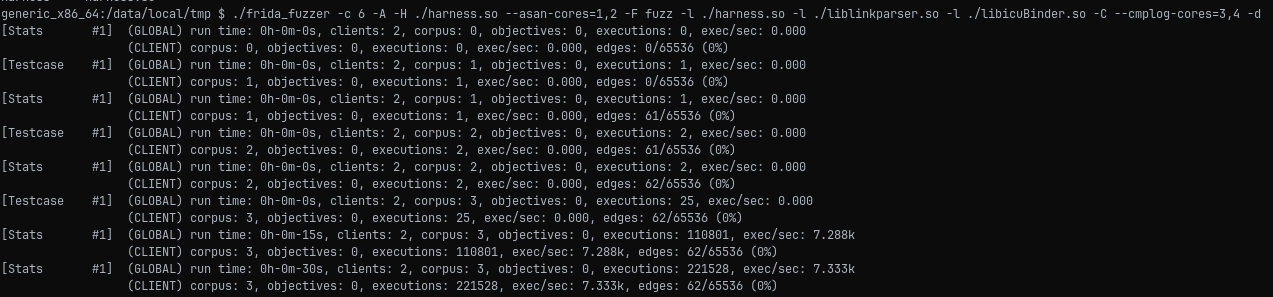
В конечном счете покрытие кода очень низкое, генерации новых входных данных практически не происходит. По этой причине я захотел снять трассу исполнения для анализа. Сделать это можно несколькими способами, но на поверхности, как мне казалось, был способ с помощью того же LibAFL. К сожалению, метод снятия покрытия с помощью Frida работает только на архитектуре AArch64:
$ ./frida_fuzzer --help
[...]
--drcov Enable DrCov (AArch64 only)
[...]
Поэтому мне пришла в голову идея запустить фаззер на платформе AArch64. Заодно использую отдельное физическое устройство вместо эмулятора.
И тут снова посыпались проблемы, начавшиеся со сборки фаззера. Пришлось немного поиграть с toolchain для AArch64, да и в целом с Android NDK, так как последние версии не хотят работать с Rust. Всякие грязные трюки и патчи не помогли, поэтому я просто стал использовать старую версию NDK.
Затем стала возникать ошибка при сборке frida-gum-sys crate. Суть ошибки состоит в том, что для сборки Frida Gum используются заголовочные файлы из системы (x86_64 в моем случае), что несовместимо с AArch64 (проблема с pthread.h). Я исправил это, склонировав репозиторий зависимости (frida-rust целиком), и руками исправил файл build.rs, добавив директиву для использования sysroot из Android NDK. Это сработало. Но появилась другая проблема: в Android NDK не было необходимого заголовочного файла frida-gum.h, что, в принципе, понятно. Тогда я снова добавил директиву, в которой говорилось, где можно взять этот файл.
diff --git a/frida-gum-sys/build.rs b/frida-gum-sys/build.rs
index 6afbb737..adcb2c02 100644
--- a/frida-gum-sys/build.rs
+++ b/frida-gum-sys/build.rs
@@ -65,9 +65,11 @@ fn main() {
bindings.clang_arg("-Iinclude")
} else {
bindings
+ bindings.clang_arg("-Iinclude")
};
let bindings = bindings
+ .clang_arg("--sysroot=./ndk/22.1.7171670/toolchains/llvm/prebuilt/linux-x86_64/sysroot/")
.header_contents("gum.h", "#include "frida-gum.h"")
.header("event_sink.h")
.header("invocation_listener.h")
Дальше возникла другая проблема: новая версия frida-gum просто не собирается — видимо, разработчик недавно что‑то сломал или вышла новая версия Frida, и API изменился. Я починил и это: ошибка была старая, это был фикс какой‑то другой ошибки, из‑за чего на более новых версиях Frida функция перестала работать.
diff --git a/frida-gum-sys/src/lib.rs b/frida-gum-sys/src/lib.rs
index d689106a..f8d5cbed 100644
--- a/frida-gum-sys/src/lib.rs
+++ b/frida-gum-sys/src/lib.rs
@@ -16,10 +16,4 @@ mod bindings {
pub use bindings::*;
-#[cfg(not(any(
- target_os = "macos",
- target_os = "ios",
- target_os = "windows",
- target_os = "android"
-)))]
pub use _frida_g_object_unref as g_object_unref;
Снова посыпались ошибки, только в другом месте: конфликты зависимостей. Несколько крейтов использовали разные версии зависимостей. Выяснилось, что в libafl_frida применяется старая версия frida-gum и frida-gum-sys. Здесь я остановился, потому что после обновления версий зависимости всплыла куча ошибок в libafl_frida, которые исправлять я уже не хотел, поскольку времени на это не оставалось. Сейчас я уже занимаюсь исправлением и попыткой собрать libafl_frida для AArch64, поэтому о применении LibAFL + Frida на AArch64 архитектуре расскажу в следующий раз.
В итоге я решил пойти другим путем — вслепую без покрытия пытаться улучшить фаззер. Мутации и сырые входные данные, которые используются в фаззере, не подходят для нашей цели, так как у нас стоит проверка на валидную строку UTF-8. Я решил переписать фаззер с использованием токенайзера. Чтобы сделать это грамотно, необходимо время, которого у меня нет, поэтому я реализовал примитивный токенайзер, как в работе Tartiflette: Snapshot fuzzing with KVM and libAFL.
В итоге фаззер стал вести себя значительно лучше и выдавать ожидаемый от него результат.
ВЫВОДЫ
Таким образом мы прошли бесхитростный путь с самого начала и до потенциального нахождения уязвимости. Можно повторить этот путь самому, а местами многое улучшить, располагая свободным временем. К тому же множество интересных моментов в анализе я оставил на потом, поэтому, дорогой читатель, изучай и пробуй! На GitHub ты сможешь найти исходные коды фаззера и harness.
Кроме того, такой подход к поиску уязвимостей можно применить ко многим приложениям, которые в своем составе имеют разделяемые библиотеки.
Читайте ещё больше платных статей бесплатно: https://t.me/xakep_1