🔵 Preguntas y Respuestas - Server Meshing y Persistent Streaming
Saul "Havok" Specter
Las preguntas de la comunidad han sido respondidas por:
- Paul Reindell (Director of Engineering, Online Technology)
- Benoit Beausejour (Chief Technology Officer en Turbulent)
- Roger Godfrey (Lead Producer)
- Clive Johnson (Lead Network Programmer)
🔹 1.- ¿Cuándo veremos el Persistent Streaming y el Server Meshing en el PU?
Nuestro objetivo actual es lanzar el Persistent Streaming y la primera versión de la "Capa de replicación", idealmente, entre el primer y el segundo trimestre del próximo año. A continuación, y salvo complicaciones técnicas imprevistas, lanzaremos la primera versión del server meshing estático entre el tercer y el cuarto trimestre del próximo año.
🔹 2.- ¿Cuál es el estado actual de la tecnología server meshing y cuáles son los principales problemas que la frenan?
La mayoría de la gente, cuando habla de Server Meshing, suele pensar en el último paso de esta tecnología en el que "enlazamos servidores". La verdad es que, antes de este paso final, es necesario realizar una larga cadena de requisitos previos y cambios tecnológicos fundamentales en nuestro motor de juego. Teniendo esto en cuenta, trataré de responder a esta pregunta teniendo en cuenta el panorama completo.
La respuesta corta es que está realmente muy avanzado.
Ahora la versión larga. El camino hacia el Server Meshing comenzó en 2017/2018:
◾️ Object Container Streaming
Para que el Server Meshing funcione, primero necesitábamos una tecnología que nos permitiera unir/desunir entidades dinámicamente a través del sistema de streaming, ya que esto no es algo que el motor soportase cuando empezamos. Así que cuando lanzamos 'Client Side Object Container Streaming' (OCS) en 2018, ¡también dimos el primer paso hacia el server meshing!
Una vez que este paso inicial fue lanzado, la tecnología que nos permite vincular/desvincular dinámicamente las entidades en el cliente tuvo que ser habilitada en el servidor también (ya que, en última instancia, los nodos del servidor en la malla necesitarán transmitir entidades de entrada/salida dinámicamente). Esta tecnología se llama 'Server Side Object Container Streaming' (S-OCS), y la primera versión de S-OCS se lanzó a finales de 2019. Este fue el siguiente gran paso hacia el Server Meshing.
◾️ Entity Authority & Authority Transfer
Aunque disponíamos de la tecnología que nos permitía transmitir dinámicamente las entidades en el servidor, seguía habiendo un único servidor que era "dueño" de todas las entidades simuladas. Con la idea de tener una malla en la que varios nodos del servidor comparten la simulación, necesitábamos el concepto de autoridad de la entidad o "entity authority". Esto significa que cualquier entidad ya no es propiedad de un único servidor de juego dedicado, sino que hay múltiples nodos servidores en la malla. Así, un nodo servidor que controla la entidad, y otros múltiples nodos servidores que tienen una vista de cliente de esta entidad. Esta autoridad también necesita la capacidad de transferir entre nodos del servidor. Se dedicó una buena cantidad de tiempo de desarrollo al concepto de "autoridad de entidad" y "transferencia de autoridad" en la primera mitad de 2020. Esta fue la primera vez que toda la empresa tuvo que trabajar en el Server Meshing, ya que hubo que cambiar mucho código del juego para trabajar con el nuevo concepto de entidad-autoridad. A finales de 2020 la mayor parte del código (del juego) se modificó para soportar este concepto, por lo que se dio otro gran paso, aunque no había todavía ninguna malla real a la vista.
◾️ Replication Layer & Persistent Streaming
El siguiente paso fue trasladar la replicación de entidades a un lugar central donde podemos controlar la lógica de streaming y de conexión a la red. Esto nos permite replicar el estado de la red a múltiples nodos del servidor. Para conseguirlo, tuvimos que trasladar la lógica de streaming y replicación fuera del servidor a la capa "Replicación", que ahora alberga el código de replicación de red y del streaming de entidades.
Al mismo tiempo, también implementamos el Persistant Streaming, que permite a la capa de replicación persistir el estado de las entidades en una base de datos gráfica que almacena el estado de cada entidad replicada en red. El año 2021 se dedicó a trabajar en la capa de Replicación y en el EntityGraph, que nos permite controlar el streaming de entidades y la replicación desde un proceso independiente (separado del servidor de juegos tradicional). Este trabajo está casi terminado y se encuentra en su fase final.
◾️ Static & Dynamic Server Meshes
Sin embargo, esto todavía no es una "malla". El trabajo en la malla propiamente dicha ha comenzado ahora y nos llevará hasta bien entrado el año que viene para completarla, y todos los requisitos previos que he descrito anteriormente fueron necesarios para llegar a este punto. La primera versión de esta tecnología será una malla de servidor estática, y es el siguiente gran paso. Sin embargo, tampoco será el último. Con la malla estática, tendremos la primera versión de una verdadera malla pero, como el nombre indica, el concepto "estática" significa que la capacidad de escalar esta malla es muy limitada.
Antes de que podamos considerar que esta función está completa, tendremos que dar otro gran paso, que llamamos "Dynamic mesh" o malla dinámica. Este paso nos permitirá engranar dinámicamente los nodos del servidor y luego escalar la malla dinámicamente en función de la demanda. Gran parte del trabajo de esta parte se realiza en paralelo. Por ejemplo, el gestor de flotas que controla la demanda dinámica de la malla ya está en desarrollo, así como los requisitos de emparejamiento que vienen con la nueva inclusión de "shards".
Mientras tanto, muchos equipos de código de juego también tienen que trabajar en la adaptación del código de juego existente para que funcione plenamente con una malla de servidor (y, lo que es más importante, encontrar todos los casos límite que sólo saldrán a la luz cuando tengamos una malla de verdad). Aunque el trabajo sobre la autoridad de las entidades se completó en 2020, actualmente la autoridad de las entidades solo se transfiere entre el cliente y un único servidor, por lo que es posible que algunos códigos necesiten ajustes adicionales.
🔹 3.- ¿Cómo pensáis gestionar una nave grande, por ejemplo una Javelin? ¿Sería un recurso propio con naves a su alrededor?
Con el "Dynamic server meshing" o mallado dinámico del servidor, es posible que las naves grandes, como la Javelin, tengan su propio servidor asignado para ejecutar la simulación autorizada para esa nave y todo lo que hay en ella. Sin embargo, intentamos evitar tener reglas inflexibles sobre cómo se asignan las entidades a los recursos de procesamiento, por lo que no siempre será así. Se trata de una cuestión de eficiencia, tanto en términos de velocidad de procesamiento como de costes de servidor. Si tuviéramos una regla rígida de que cada Javelin y todo lo que hay en ella tiene su propio servidor, entonces no sería muy rentable cuando un Javelin sólo tiene un puñado de jugadores dentro de ella. La misma regla tampoco sería eficiente en términos de velocidad de procesamiento del servidor si hubiera cientos de jugadores apiñados en la misma Javelin, ya que la regla nos impediría distribuir la carga de procesamiento entre varios servidores.
La malla dinámica de servidores será un poco diferente, ya que reevaluará constantemente la mejor manera de distribuir la simulación, con el objetivo de encontrar el punto óptimo para que ningún servidor esté sobrecargado o infrautilizado. A medida que los jugadores se desplacen por el "verso", la distribución ideal de los recursos de procesamiento cambiará. Para reaccionar a esos cambios, necesitaremos la capacidad de transferir la autoridad sobre las entidades de un servidor a otro, así como poner en línea nuevos servidores y cerrar los antiguos. Esto nos permitirá trasladar la carga de procesamiento de un servidor que corre el riesgo de sobrecargarse a otro que actualmente está infrautilizado. Si ninguno de los servidores existentes tiene suficiente capacidad de reserva para manejar un aumento de la carga, podemos simplemente alquilar más servidores a nuestro proveedor de la plataforma en la nube. Y cuando algunos servidores no tienen suficiente carga para hacerlos rentables, algunos de ellos pueden transferir sus partes de la simulación a los otros y podemos apagar los que ya no necesitamos.
🔹 4.- ¿Cuántos jugadores podrán verse en un mismo espacio? ¿Cuál es el máximo previsto?
Esta es una pregunta difícil de responder, y la mejor respuesta que podemos dar por el momento es que depende.
Asumiendo que la pregunta es sobre el límite de cuántos jugadores podrán verse entre sí desde una perspectiva del cliente, esto está principalmente dictado por el cliente del juego. Ya que esto se debe a la simulación del lado del cliente, como la física y el código del juego, así como al coste de renderización.
Además, también depende en gran medida del escenario; 100 jugadores en combate FPS son más "baratos" de simular y renderizar en el cliente que 100 jugadores luchando en naves espaciales monoplaza, disparándose misiles y láseres.
El equipo de gráficos está trabajando activamente en Vulkan, que nos permitirá aumentar las "llamadas de dibujo" y debería mejorar el número de jugadores/naves que podemos renderizar al mismo tiempo, mientras que el equipo del motor está muy centrado en las optimizaciones del código del juego para aumentar el número de objetos del juego que podemos simular a la vez.
Nuestro objetivo es aumentar el número de jugadores y nuestra expectativa es que podamos soportar escenarios en los que 100 jugadores puedan verse unos a otros a velocidades de fotogramas razonables. Sin embargo, cuando empecemos a escalar nuestros shards para soportar un mayor número de jugadores, la probabilidad de que todos los jugadores de un shard puedan ir a la misma ubicación física y verse sin problemas de rendimiento disminuirá.
Aquí es donde tendremos que empezar a implementar mecánicas de juego que eviten que estos escenarios se den con demasiada frecuencia.
El límite absoluto es difícil de predecir hasta que algunas de las nuevas tecnologías estén en línea y podamos empezar a medir el rendimiento.
🔹 5.- Si hago una base en una luna, ¿se reflejará mi base en los otros shards en los que no estoy?
El equipo de Planet Tech planea implementar la construcción de bases teniendo en cuenta los shards. Al reclamar un terreno para tu base, éste será reclamado en todos los shards, y planeamos replicar tu base en todos los shards.
Sin embargo, sólo un shard tendrá una versión "activa" de la base, mientras que otros shards generarán una versión de "acceso limitado/sólo lectura" de esa misma base. Por ejemplo, una base dará acceso completo y la posibilidad de expandirse en el shard en el que el propietario juega actualmente, mientras que en todos los demás shards, esta base puede aparecer con las puertas cerradas en un estado inalterable. Sin embargo, el diseño completo aún no está establecido al 100% y puede cambiar.
🔹 6.- El verdadero objetivo final, ¿es tener un único shard para todos los jugadores?
Esta es nuestra ambición, pero no es posible dar una respuesta definitiva en este momento.
Empezaremos con muchos shards pequeños por región y poco a poco iremos reduciendo el número de shards. El primer gran objetivo será reducirlo hasta necesitar un solo shard por región. Para llegar a ello, nuestro plan es aumentar gradualmente el número de jugadores por shard y mejorar constantemente el backend y la tecnología del cliente para soportar cada vez más jugadores.
Para alcanzar este objetivo no sólo se necesitan cambios tecnológicos, sino también un nuevo diseño y nuevas mecánicas de juego. Sin una mecánica que evite que todos los jugadores vayan a la misma ubicación, será muy difícil conseguir un gran mega shard, especialmente en el cliente. Por ejemplo, podría haber una mecánica que cerrara temporalmente los puntos de salto a las ubicaciones abarrotadas, o crear nuevas rutas para ciertas ubicaciones.
Mientras que el backend está diseñado para escalar horizontalmente, el cliente del juego se ejecuta en una sola máquina y está limitado a un número definido de núcleos de CPU/GPU, así como de memoria.
Sólo una vez que superemos estos obstáculos y consigamos un megar shard por región, podremos enfrentarnos al jefe final: Fusionar los shards regionales en un mega shard global.
Esto conlleva su propia serie de problemas, ya que la localidad desempeña un papel importante en la experiencia del jugador. Por ejemplo, la latencia entre servicios dentro del mismo centro de datos es mucho menor que la latencia entre servicios alojados en dos centros de datos separados por regiones. Y aunque hemos diseñado el backend para que admita un shard global, es un reto operativo desplegar el backend de forma que no favorezca a un grupo de jugadores en detrimento de otro.
🔹 7.- ¿La economía del universo será independiente en cada shard o estará asociada?
La economía será global y se reflejará en cada shard.
Por ejemplo, echemos un vistazo a las tiendas. Mientras que cada tienda tiene un inventario local (los artículos que están expuestos en ese momento), las tiendas se reponen a partir de un inventario global compartido en todos los shards. Si muchos jugadores comienzan a comprar un arma específica en la tienda de armas de Port Olisar, el precio de esa arma aumentará en esta tienda en todos los shards. Con el tiempo, el inventario de esta arma se agotará, por lo que las tiendas de todos los shards ya no podrán reponer esta arma.
🔹 8.- ¿Qué evitará que los grandes grupos de "buenos" y "malos" terminen encerrados en un mismo tipo de shard? Las dinámicas sociales implicarían grandes concentraciones de personas que tendrán amigos y estarán en orgs que tienen los mismos intereses. ¿Habrá una solución que garantice la mezcla adecuada de buenos, malos y de los que están en el medio?
Los jugadores no serán asignados permanentemente a los shards, ya que el sistema de matchmaking asigna un nuevo shard para la región seleccionada en cada inicio de sesión. Al principio, esto provocará una distribución natural, ya que empezaremos con muchos shards pequeños en paralelo.
Cuando empecemos a escalar nuestros shards (y por tanto a reducir el número de shards en paralelo), esta cuestión será más relevante. Tenemos previsto abordar esta cuestión con nuestro nuevo sistema de emparejamiento.
El nuevo sistema de emparejamiento, actualmente en desarrollo junto con el de malla de servidores, nos permite emparejar a los jugadores con los shards basándonos en múltiples parámetros de entrada. Estos se utilizan para emparejar a los jugadores con sus amigos, o con el lugar donde dejaron la mayoría de sus objetos en el mundo abierto. Sin embargo, también nos permite utilizar parámetros más avanzados, como la reputación y otras estadísticas ocultas de los jugadores que rastreamos.
Esto nos permitirá intentar garantizar que cada shard tenga una colección semidiversa de individuos. Por ejemplo, podemos asegurarnos de no cargar inadvertidamente un shard sólo con jugadores legales, lo que podría no ser muy divertido si parte de lo que quieren hacer es cazar jugadores criminales.
🔹 9.- ¿Estarán tu personaje y tu nave siempre en el juego cuando te hayas ido; es decir, si me desconecto de mi cama en un planeta, mi nave seguirá allí, lo que significa que la gente podría intentar entrar en mi nave o destruirla?
Cuando una entidad se "despega" de un shard (existiendo físicamente en el shard), existe permanentemente dentro de ese shard hasta que el jugador "almacena" la entidad en un inventario. Esto puede hacerse recogiendo un arma y colocándola en la mochila, o aterrizando una nave en una plataforma de aterrizaje, lo que hará que la nave se guarde en un inventario específico de la plataforma de aterrizaje. Una vez que una entidad está dentro de un inventario, se almacena en la base de datos global y puede ser extraída en cualquier shard. Esto permite a los jugadores mover objetos entre shards.
También planeamos una mecánica llamada "Hero item stow/unstow" o almacenar/extraer objetos heroicos. Esto tomará cualquier objeto heroico propiedad del jugador y lo guardará automáticamente en un inventario de transición de shard específico para el jugador. El almacenamiento automático suele producirse cuando no hay otros jugadores cerca y la entidad es expulsada. Los objetos en transición entre inventarios de los shard seguirán al jugador automáticamente, así que cuando un jugador se conecte a un shard diferente, cogeremos las entidades y las extraeremos en el nuevo shard en la posición en la que el jugador las dejó.
Cuando se aterriza la nave en una luna y se cierra la sesión, la nave saldrá y se almacenará automáticamente si no hay otros jugadores en ese momento. Ahora, cuando te conectes a un shard diferente, tu nave será extraída en el nuevo shard. Si, por alguna razón, la nave permaneció en el antiguo shard durante más tiempo y fue destruida mientras estabas desconectado, puede que te despiertes en una cama médica.
🔹 10.- ¿En qué medida el nuevo contenido depende ahora del server meshing?
Si bien el server meshing nos permitirá empezar a aumentar el número de jugadores que pueden jugar juntos en Star Citizen, también nos permitirá empezar a añadir nuevas experiencias de contenido. En este momento, nos centramos en utilizarlo para añadir nuevos sistemas estelares. El server meshing es una de las tecnologías clave para que los puntos de salto funcionen en el juego, permitiendo que los sistemas estelares entren y salgan de la memoria sin necesidad de pantallas de carga. Los jugadores lo verán por primera vez el año que viene, cuando la primera iteración de server meshing se ponga en marcha con la introducción del sistema Pyro.
A medida que vayamos perfeccionando la tecnología y pasemos del server meshing estático al dinámico, los diseñadores podrán utilizar esta tecnología para crear zonas más grandes e interesantes (como asentamientos más grandes o interiores de naves de gran tamaño) con un número más elevado de personajes de la IA y de los jugadores. El server meshing podría abrir las puertas a experiencias de juego que nuestros diseñadores ni siquiera han pensado todavía.
🔹 11.- ¿En qué medida podemos esperar una mejora del rendimiento?
La mayor ganancia será en el rendimiento del servidor. Ahora mismo, el rendimiento de nuestro servidor es bastante limitado debido al gran número de entidades que tenemos que simular en un servidor. Esto da lugar a una velocidad de fotogramas muy baja y a la degradación del servidor, lo que hace que el cliente experimente un retraso en la red y efecto "rubber banding" (ndt: es un efecto problema de la latencia similar a sufrir problemas de teletransporte) y otros problemas de desincronización de la red. Una vez que tengamos incluso el server meshing estático en su lugar, esperamos que el shard del servidor sea considerablemente mayor, disminuyendo estos sintomas.
En cuanto a los FPS del cliente, el server meshing tiene muy poco impacto. El cliente sólo transmite las entidades que están en el rango visible. Es posible que se produzcan ligeras mejoras, ya que podemos ser un poco más agresivos con la selección del alcance en el cliente, ya que, en este momento, algunos objetos tienen un radio de transmisión abultado para que características como el radar o los misiles funcionen correctamente. Con el server meshing, podemos desacoplar el radio de transmisión del cliente y del servidor. Sin embargo, estas mejoras serán mínimas en el cliente. Aun así, los FPS más rápidos del servidor mejorarán la experiencia general, ya que el retardo de la red se reducirá considerablemente.
🔹 12.- Sé que puede que no haya una respuesta a esto todavía, pero, tras el lanzamiento inicial del Server Meshing, ¿cuántos shards se prevé que se necesiten? ¿10, 100, 1000, más? Sabemos que el cambio significará más jugadores por área de juego, pero no estamos seguros de cuántos prevéis.
La respuesta corta es que no podemos adelantar un número.
El concepto de shard es la parte "maleable" de la arquitectura de malla, y sólo podremos decir el número de shards necesarios una vez que todas las piezas que lo componen estén en su sitio y hemos planeado llegar a él de forma iterativa.
Con la primera entrega de Persistent Streaming (que no el server meshing), queremos empezar imitando el comportamiento actual que se ve online teniendo un shard por instancia de servidor y un replicante (llamado el híbrido). La única diferencia es que todas las entidades en esos shards seguirán siendo persistentes. Esto nos permite lidiar con el peor de los casos al tener un número realmente grande de shards persistentes y replicantes muy grandes para probar la mecánica de crear/sembrar, simular con jugadores activos, y dar rotaciones para detectar situaciones donde se deban crear o destruir shards. Queremos que la creación y la destrucción de shards en esta primera fase sean óptimas, rápidas y de coste neutro.
Este enfoque tiene varias ventajas, ya que podemos llegar a probar la persistencia de los shards antes y, lo que es más importante, podemos medir las métricas activas en muchos shards.
Por ejemplo (¡no es exhaustivo!):
- Cuántas entidades permanecen en un shard persistente a lo largo del tiempo (tasa de crecimiento del shard)
- Tamaño del gráfico global (tasa de crecimiento global)
- Cuántos jugadores puede manejar una sola base de datos de shards (uso de jugadores)
- Efecto de varias mecánicas de juego en las actualizaciones de entidades en la base de datos del shard (efectos del juego)
- Perfil de rendimiento de las colas de escritura, tiempos medios de consulta de los clusters de la base de datos de los shards (métricas de la base de datos de shards)
- Perfil de rendimiento de las colas de escritura, tiempos medios de consulta del clúster de la base de datos global (métricas de la base de datos global)
- Eficiencia de la fragmentación de la base de datos del gráfico
Aunque disponemos de estimaciones y mediciones internas adecuadas para ello, nada sustituye a los jugadores reales que generan una carga representativa en el sistema.
A medida que vayamos poniendo en juego los demás componentes del "meshing" o mallado, principalmente la malla estática, tenemos previsto reducir gradualmente el número de shards, agrupando a los jugadores en shards cada vez más grandes hasta que nos sintamos cómodos con el rendimiento de los replicantes, los servidores y el gráfico de entidades. Por supuesto, la malla estática sufrirá problemas de congregación y sólo podremos reanudar el paso a shards mucho más grandes una vez que la malla dinámica esté en marcha.
En última instancia, con la malla dinámica, aspiramos a soportar shards muy grandes.
🔹 13.- ¿Puede un recurso tan pequeño como una bala viajar a través de los shards del servidor?
La respuesta corta es no.
Puedes ver los shards como una instancia completamente aislada del universo simulado, de forma muy similar a como tenemos actualmente diferentes instancias aisladas por servidor dedicado. Para que los objetos se transfieran entre instancias, estos objetos tienen que ser guardados en un inventario antes de que puedan ser extraídos en un shard diferente. Por ejemplo, si un jugador coge un arma en un shard y la coloca en su mochila lo ha alojado en un inventario. Ahora, cuando el jugador se conece a un shard diferente, el jugador puede sacar el arma de su mochila, extrayéndola en el nuevo shard.
Dentro de un shard, una entidad como un misil podrá viajar a través de múltiples nodos del servidor si estos nodos del servidor tienen el misil dentro del área de transmisión del servidor. Sólo un nodo del servidor tendrá el control (ya que tiene autoridad) sobre ese misil, mientras que los otros nodos del servidor sólo verán una vista de cliente del mismo misil.
Las balas se generan en el lado del cliente. Por lo tanto, una versión única de la bala se genera en cada nodo cliente y servidor, por lo que no se trata de una entidad replicada en red como el misil en el ejemplo anterior.
🔹 14.- Cuando nos ocupamos de las diferentes regiones del mundo, ¿está planeando alojar cuatro granjas de servidores principales, como EE.UU., la UE, China y Oceanía? ¿O estáis planeando hacer "un universo global"? Si es global, ¿cómo se gestionaría el equilibrio de los jugadores con variaciones extremas de ping?
Seguimos pensando en mantener la distribución regional de los servicios sensibles a la red. En el despliegue inicial de Persistent Streaming, la base de datos global será realmente global. Los propios shards estarán distribuidos regionalmente, por lo que un cliente de juego que se conecte a la región de la UE será preferiblemente emparejado con un shard de la UE. A medida que los shards crezcan en tamaño (tanto para los jugadores como para las entidades), tenemos previsto revisar este modelo e introducir también servicios a nivel regional para servir datos más cercanos a la localidad.
🔹 15.- Vivo en Europa del Este. Tras el lanzamiento del Server Meshing, ¿podré jugar con amigos de Estados Unidos?
No tenemos previsto limitar el shard y la región que puede elegir un jugador.
Un jugador será libre de elegir cualquier región para jugar y, dentro de esta región, permitiremos una selección limitada de shards. Por ejemplo, el shard con tus amigos o el shard en el que jugaste por última vez.
Dado que todos los datos de los jugadores se almacenan en la base de datos global, los jugadores podrán cambiar de un shard a otro de forma similar a como pueden cambiar de instancia hoy en día. Los objetos que se guarden se transferirán con el jugador y estarán siempre accesibles independientemente del shard.
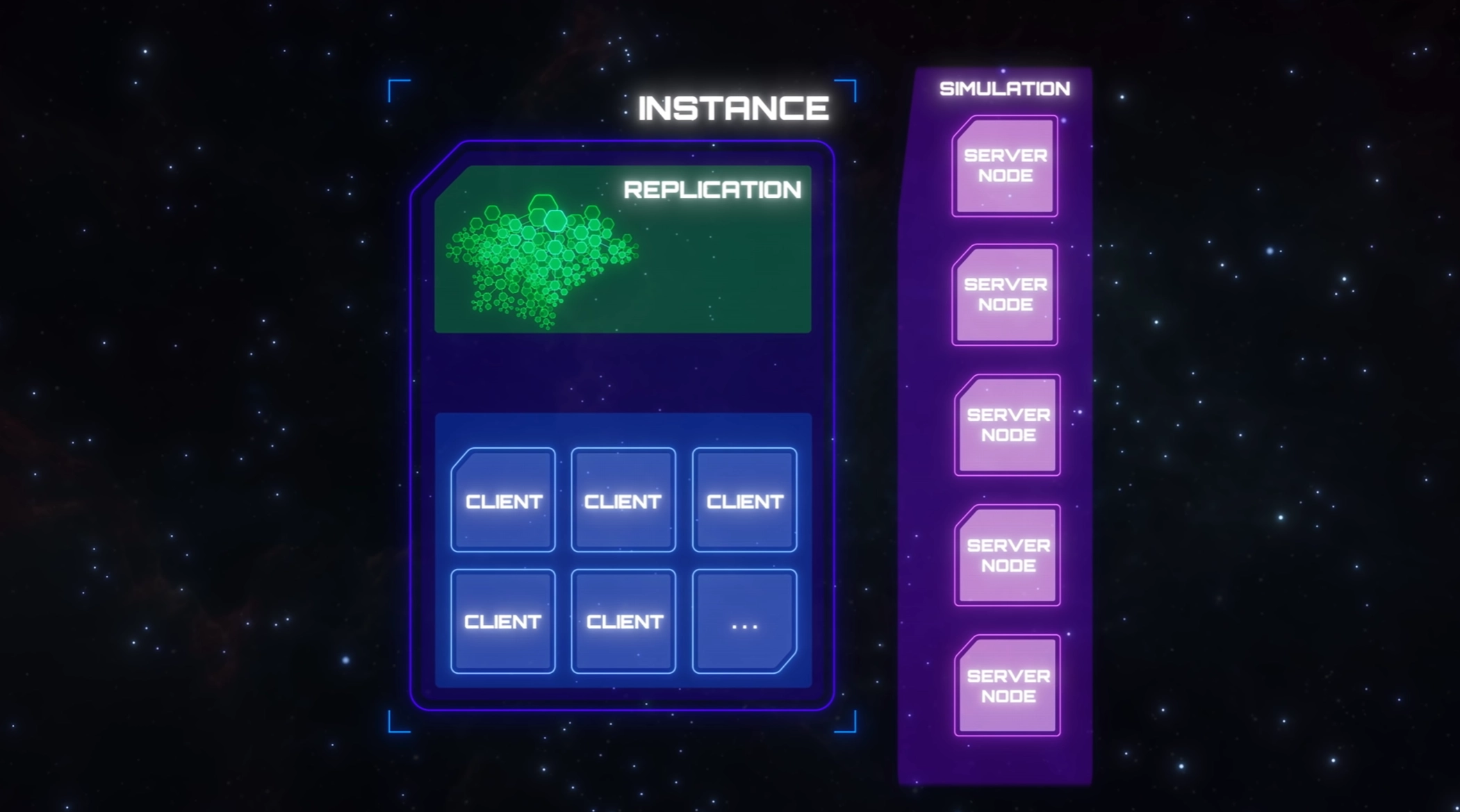
🔹 16.- Sobre "matar" la capa de replicación: ¿Qué experimentarán los jugadores si una capa de replicación se apaga/"muere"? Sabemos que el gráfico de entidades recogerá la información sembrada y la devolverá a una nueva capa de replicación, pero ¿volveremos al menú principal si la capa de replicación muere, en comparación con si muere un nodo del servidor, o tendremos algún tipo de pantalla de carga que nos haga coincidir automáticamente con una nueva capa?
Para responder a esto adecuadamente, primero tengo que dar algunos detalles más sobre cómo será nuestra arquitectura final. En última instancia, la capa de replicación no será un único nodo servidor. En su lugar, consistirá en múltiples instancias de un conjunto de microservicios con nombres como Replicant, Atlas y Scribe. Una de las ventajas de esto es que la propia capa de replicación será capaz de escalar. Otra ventaja, más relevante para esta pregunta, es que aunque un solo nodo/instancia en la capa de Replicación puede fallar, es muy poco probable que toda la capa de Replicación falle a la vez. Desde el punto de vista del cliente, los nodos replicantes son los más importantes, ya que son los que se encargarán de la transmisión de entidades en red y de la replicación de estados entre los clientes y el juego. El replicante está diseñado para no ejecutar ninguna lógica de juego y, de hecho, ejecutará muy poco código; sin animación, sin física, sólo código de red. Al estar construido a partir de una base de código tan pequeña, debería haber menos errores en general. Así que, tras algunos inevitables problemas iniciales, esperamos que los Replicantes sean bastante estables. También es importante saber que, en un momento dado, un solo cliente puede ser atendido por varios replicantes (pero esos replicantes también estarán atendiendo a otros clientes al mismo tiempo). La última pieza del rompecabezas es la capa del Gateway: Los clientes no se conectarán directamente a los replicantes, sino a un nodo de la capa Gateway. El servicio Gateway está ahí para dirigir los paquetes entre los clientes y los distintos replicantes con los que se comunican. El servicio Gateway utilizará una base de código aún más pequeña que la de los replicantes, por lo que debería ser aún menos probable que se bloquee.
◾️ ¿Qué experimentará un cliente si uno de los replicantes que le sirve se bloquea de repente?
El cliente permanecerá conectado al shard pero parte o toda su simulación se congelará temporalmente. La capa de Replicación hará que un nuevo nodo replicante reemplace al que se bloqueó y recuperará el estado de la entidad perdida de la persistencia a través del EntityGraph. Las pasarelas de clientes y los nodos de servidor que estaban conectados al antiguo replicante restablecerán la conexión con el nuevo. Una vez que todo esté reconectado, el juego se descongelará para los clientes afectados. En este punto, el cliente puede experimentar algunos cortes/teleportación de entidades. Esperamos que todo el proceso dure menos de un minuto.
◾️ ¿Qué experimentará un cliente si la pasarela que le sirve se bloquea repentinamente?
El servicio de la pasarela no guarda ningún estado del juego y tendrá su propia forma de recuperación de fallos. Como es un servicio mucho más sencillo que un replicante, el tiempo de recuperación debería ser mucho más rápido, más bien en torno a los segundos. Mientras la recuperación está en curso, el cliente experimentará una congelación temporal, seguida de algunos cortes/teleportación.
◾️ ¿Qué pasa con el servicio híbrido?
Durante la presentación de la CitizenCon sobre Persistent Streaming y Server Meshing, Paul y Benoit hablaron de la capa de replicación en términos del servicio Hybrid. El servicio Hybrid es, como su nombre indica, un híbrido de los servicios Replicant, Atlas, Scribe y Gateway que he mencionado anteriormente (pero no EntityGraph), así como un puñado de otros servicios que aún no se han discutido. Hemos optado por desarrollar esto primero antes de dividirlo en los servicios que lo componen, ya que reduce el número de partes móviles que estamos tratando de manejar a la vez. También nos permite centrarnos en probar todos los grandes conceptos en lugar de la chapuza de hacer que todos esos servicios individuales se comuniquen correctamente. En esta implementación inicial, la capa de Replicación será un único nodo de servidor Híbrido. Si este nodo híbrido falla, la situación será similar a la que los clientes experimentan ahora cuando un servidor de juegos falla. Todos los clientes serán devueltos al menú del frontend con el famoso error 30k. Una vez que el híbrido de reemplazo haya comenzado, los clientes podrán volver a unirse al shard y continuar donde lo dejaron. Con suerte, podremos implementarlo de forma que los clientes reciban una notificación en pantalla de que el shard está disponible de nuevo y una sola pulsación de tecla les devolverá al shard (de forma similar a como funciona la recuperación de la caída del cliente).
🔹 17.- En el panel se habló mucho de qué nodos tienen autoridad de escritura dentro de un shard, pero ¿qué pasa con la autoridad de escritura entre shards independientes? ¿Se mantienen bases de datos de persistencia separadas para los distintos shards o los estados de los elementos del universo persistente acabarán sincronizándose entre shards aunque se hayan dejado en estados diferentes (por ejemplo, una puerta se deja abierta en un shard y se deja cerrada en otro: ¿un shard acabará escribiendo su estado en la base de datos, actualizando el estado de la puerta en el otro shard?)
En general, cada shard es su propia y única copia del universo, y cualquier elemento dentro del shard no compartirá el estado con un elemento de un shard diferente, ya que cada shard tiene su propia base de datos. Por otro lado, tenemos una base de datos global para los datos del inventario del jugador. Esta base de datos se utiliza para almacenar cualquier artículo en el inventario de un jugador, y los artículos pueden transferirse entre shards si primero se almacenan desde un shard en un inventario y luego se extraen en otro shard.
Algunas características, como las bases creadas por los jugadores o los recursos minables, implementan un código especial que replicará un estado global a todos los shards, por lo que una base puede existir en múltiples shards en paralelo y replicar lentamente (en relación con la velocidad del juego en tiempo real) su estado entre shards. No se trata de una replicación instantánea (una puerta que se abre/cierra no se replica), sin embargo, un estado persistente como una puerta que se cierra o se abre puede replicarse entre los shards.
Lo mismo ocurre con los recursos minables: Mientras que cada shard tiene una versión única de una roca minable, la cantidad global se replicará entre shards, así que cuando los jugadores empiecen a minar una determinada zona, el mapa global de recursos de esta zona se modificará y el número de rocas minables en esa ubicación se verá afectado en todos los shards.
🔹 18.- Cuando tienes a un grupo que se mueve (en viaje cuántico por ejemplo) de un nodo de servidor a otro o la instancia está llena, ¿creará el Static Meshing otro nodo de servidor de forma preventiva? ¿O cómo se gestionará esto?
Con el server meshing estático, todo está fijado de antemano, incluyendo el número de nodos del servidor por shard y qué servidor del juego es responsable de simular qué lugares. Esto significa que si todo el mundo en el shard decide dirigirse a la misma ubicación, todos acabarán siendo simulados por el mismo nodo servidor.
En realidad, el peor caso es que todos los jugadores decidan repartirse entre todas las localizaciones asignadas a un único nodo servidor. De este modo, el pobre servidor no sólo tendrá que lidiar con todos los jugadores, sino que también tendrá que hacer streaming en todas sus localizaciones. La respuesta obvia es permitir más servidores por shard, para que cada nodo servidor tenga menos localizaciones en las que tenga que hacer streaming. Sin embargo, como se trata de una malla estática y todo está fijado de antemano, tener más nodos servidores por shard también aumenta los costes de funcionamiento. Pero hay que empezar por algún sitio, así que el plan para la primera versión del Static Server Meshing es empezar con el menor número de nodos servidor por shard que podamos, sin dejar de probar que la tecnología realmente funciona. Está claro que eso va a ser un problema si permitimos que los shards tengan muchos más jugadores que los 50 que tenemos ahora en nuestros "shards" de un solo servidor.
Así que no esperes que el número de jugadores aumente mucho con la primera versión. Esto evita el problema de que un nodo de un solo servidor se llene antes de que los jugadores lleguen a él, ya que limitaremos el número máximo de jugadores por shard basándonos en el peor de los casos. Una vez que esto funcione, analizaremos el rendimiento y la economía y veremos hasta dónde podemos llegar. Pero para que una mayor expansión sea económicamente viable, tendremos que estudiar la posibilidad de dinamizar la malla del servidor lo antes posible.
🔹 19.- Con el enorme volumen de datos que viajan entre los clientes y los nodos del servidor, y la necesidad de una latencia extremadamente baja, ¿cómo se gestiona esto o qué tecnologías se utilizan para ayudar a acelerar las cosas, o más bien evitar que se ralenticen?
Los principales factores que afectan a la latencia son la frecuencia de los servidores, el ping de los clientes, la aparición de entidades y la latencia de los servicios persistentes.
La tasa de tics del servidor es la que más afecta y está relacionada con el número de localizaciones que simula un servidor de juego. El server meshing debería ayudar en este sentido, reduciendo el número de localizaciones que cada servidor de juego necesita transmitir y simular. Menos localizaciones significarán un recuento medio de entidades mucho menor por servidor y el ahorro puede utilizarse para aumentar el número de jugadores por servidor.
El ping del cliente está dominado por la distancia al servidor. Vemos que muchos jugadores eligen jugar en regiones de continentes completamente diferentes. Parte de nuestro código de juego sigue siendo de autoría del cliente, lo que significa que los jugadores con un ping alto pueden afectar negativamente a la experiencia de juego de todos los demás. No hay mucho que podamos hacer al respecto a corto plazo, pero es algo que queremos mejorar una vez que el server meshing esté funcionando.
La lentitud en generar entidades puede causar latencia al retrasar la entrada de entidades en los clientes. Esto puede causar efectos no deseados, como que las localizaciones no aparezcan del todo hasta minutos después de que hayas viajado en quantum a una localización, que te caigas a través del suelo después de respawnear en una localización, que las naves tarden en aparecer en las terminales ASOP, que se cambie el loadout del jugador, etc. Los cuellos de botella con esto están principalmente en el servidor. En primer lugar, las entidades no se replican a los clientes hasta que no han aparecido por completo en el servidor. En segundo lugar, el servidor tiene una única cola de generación que debe procesar en orden. En tercer lugar, cuantas más ubicaciones necesita un servidor para hacer streaming, más generaciones (spawning) tiene que hacer. Para mejorar las cosas, hemos modificado el código de spawn del servidor para hacer uso de colas de spawn paralelas. El server meshing también ayudará, no sólo por la reducción de la carga en las colas de spawn al reducir el número de ubicaciones en las que un servidor tiene que hacer streaming, sino también porque la capa de replicación replica las entidades a los clientes y servidores simultáneamente, permitiéndoles hacer spawn en paralelo.
Seguimos utilizando algunos de nuestros servicios persistentes heredados, adecuados como se diseñaron pero que se sabe que tienen problemas de rendimiento y escalabilidad bajo nuestras demandas. Esto puede dar lugar a largas esperas cuando se obtienen datos persistentes de los servicios para saber qué hay que generar, como generar una nave desde un terminal ASOP, examinar un inventario, cambiar el equipamiento del jugador, etc. Dado que el streaming persistente completo y el server meshing aumentarán drásticamente la cantidad de datos que necesitamos persistir, sabíamos que teníamos que hacer algo al respecto. Por eso, Benoit y su equipo de Turbulent han reinventado por completo la forma de persistir los datos en forma de EntityGraph, que es un servicio altamente escalable construido sobre una base de datos altamente escalable que está optimizada exactamente para el tipo de operaciones de datos que realizamos. Además, también estamos desarrollando la capa de replicación, que actúa como una caché en memoria altamente escalable del estado actual de todas las entidades en un shard, eliminando la necesidad de la mayoría de las consultas que hemos estado enviando a los servicios persistentes heredados. Así es, ¡se trata de servicios altamente escalables en todo momento!
Para ayudar a reducir/eliminar cualquier latencia adicional que la capa de Replicación pueda introducir, la estamos construyendo para que sea impulsada por eventos en lugar de por una tasa de ticks como un servidor de juegos tradicional. Esto significa que, a medida que entren paquetes, los procesará inmediatamente y enviará la respuesta y/o reenviará la información a los clientes y servidores de juegos pertinentes. Una vez que se haya completado el trabajo en la versión inicial de la capa de replicación (el servicio híbrido), realizaremos un pase de optimización para asegurarnos de que responda lo mejor posible. Y, aunque en última instancia se trata de una decisión de DevOps, los desplegaremos en los mismos centros de datos que los propios servidores del juego, de modo que la latencia de la red en el cable debido al salto adicional entre la capa de replicación y el servidor del juego debería ser inferior a un milisegundo. Ah, ¿y he mencionado que la capa de replicación será altamente escalable? Eso significa que si detectamos que la capa de replicación está causando problemas de latencia en determinadas partes del universo, podremos reconfigurarla para solucionar el problema.
---------------------------------------
Descargo de responsabilidad
Las respuestas reflejan con exactitud las intenciones del desarrollo en el momento de la redacción, pero la empresa y el equipo de desarrollo se reservan el derecho de adaptar, mejorar o cambiar las características y los diseños en respuesta a los comentarios, las pruebas de juego, las revisiones de diseño u otras consideraciones para mejorar el equilibrio o la calidad del juego en general.
FUENTE: