Порядок исполнения SQL
Оригинал статьи: https://www.sisense.com/blog/sql-query-order-of-operations/

Создание очередности
Порядок шагов, которые вы предпринимаете для достижения цели, имеет значение! Когда вы печете пирог, нужно сначала разогреть конфорку, смазать сковороду и смешать ингредиенты в правильном порядке, иначе вместо вкусного лакомства получится каша. Выбор правильного порядка операций в SQL тоже важен, если вы хотите писать эффективные запросы. В этой статье мы рассмотрим несколько лучших практик, которые помогут вам оптимизировать SQL-запросы.
Определение порядка исполнения SQL
Порядок исполнения SQL означает очередность, в которой обрабатываются фрагменты запроса. Некоторых распространенных проблем, с которыми сталкиваются пользователи при выполнении запросов, можно было бы легко избежать при более четком понимании порядка выполнения SQL, который иногда называют порядком операций SQL. Понимание порядка выполнения SQL-запросов может помочь вам выяснить, почему запрос не выполняется, а еще чаще поможет вам оптимизировать запросы, чтобы они выполнялись быстрее.
В современном мире планировщики запросов SQL могут использовать всевозможные приемы для более эффективного выполнения запросов, но они всегда должны приходить к тому же конечному ответу, что и запрос, который выполняется в соответствии со стандартным порядком выполнения SQL. Этот порядок следующий:
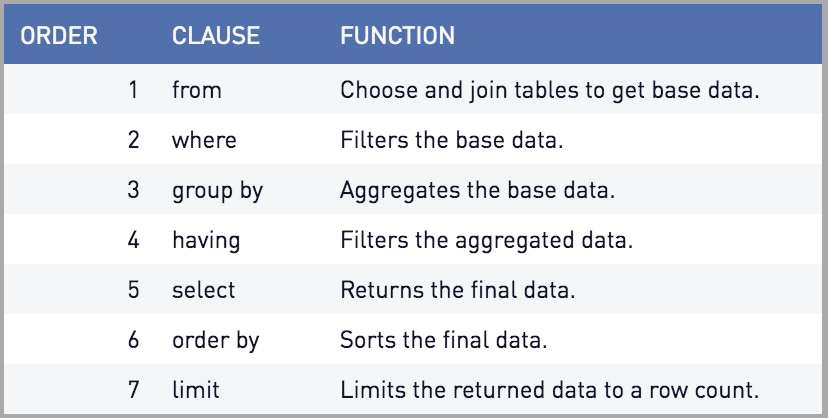
Оператор FROM
Оператор FROM в SQL выбирает и соединяет таблицы и является первой выполняемой частью запроса. Это означает, что в запросах с объединениями объединение происходит первым.
Хорошей практикой является ограничение или предварительная агрегация таблиц перед потенциально большими соединениями, которые в противном случае могут занимать много памяти. Многие современные планировщики SQL используют логику и различные типы JOINS для оптимизации различных запросов, что может быть полезно, но на это не стоит рассчитывать.
В примере, приведенном ниже, планировщик SQL может знать, что нужно предварительно отфильтровать pings. Это технически нарушает правильный порядок запросов SQL, но возвращает правильный результат.
select count(*) from pings join signups on pings.cookie = signups.cookie where pings.url ilike '%/blog%'
Однако если вы собираетесь использовать столбцы таким образом, чтобы предотвратить предварительную фильтрацию, базе данных придется отсортировать и объединить обе полные таблицы. Например, следующий запрос требует столбца из каждой таблицы и будет принудительно объединен до того, как произойдет какая-либо фильтрация.
-- || используется для объединения строк select count(*) from first_names join last_names on first_names.id = last_names.id where first_names.name || last_names.name ilike '%a%'
Чтобы ускорить выполнение запроса, можно предварительно отфильтровать имена, содержащие "a":
with limited_first_names as (
select
*
from
first_names
where
name ilike '%a%'
)
, limited_last_names as (
select
*
from
last_names
where
name ilike '%a%'
)
select
count(*)
from
limited_first_names
join
limited_last_names
on
limited_last_names.id = limited_first_names.id
Оператор WHERE
Оператор WHERE используется для ограничения объединенных данных значениями столбцов вашей таблицы. Его можно использовать с любым типом данных, включая числа, строки или даты.
where nmbr > 5; where strng = 'Skywalker'; where dte = '2017-01-01';
Одна из частых "загвоздок" в SQL - попытка использовать оператор WHERE для фильтрации агрегаций, что нарушает правила порядка выполнения SQL. Это происходит потому, что когда оператор WHERE выполняется, оператор GROUP BY еще не выполнен и значения агрегатов неизвестны. Таким образом, следующий запрос завершится неудачей:
select country , sum(area) from countries where sum(area) > 1000 group by 1
Но эту проблему можно решить с помощью оператора HAVING.
Оператор GROUP BY
Оператор GROUP BY группирует поля итогового результата в отдельные значения. Этот оператор используется с такими функциями, как SUM() или COUNT(), чтобы показать одно значение для каждого сгруппированного поля или комбинации полей.
При использовании GROUP BY: Сгруппировать по X означает поместить в одну строку все данные с одинаковым значением для X. Группировать по X, Y означает поместить в одну строку все те, у которых одинаковые значения для X и Y.