Поиск анаграмм
PainНашел 15 минут накидал бенчмарк, для задания, выбрал два варианта метода(один из комментариев, второй из головы)
В проекте я использовал самую длинную в русском языке анаграмму(лесопромышленность-солепромышленность) и зеркальную анаграмму(телекс-скелет), что бы понять имеет ли порядок символов и длинна значение для скорости поиска.
Методы:
-Вариант от Арсена преобразовать в словарь, а затем проверить есть такой ключ или нет и сравнить количество.
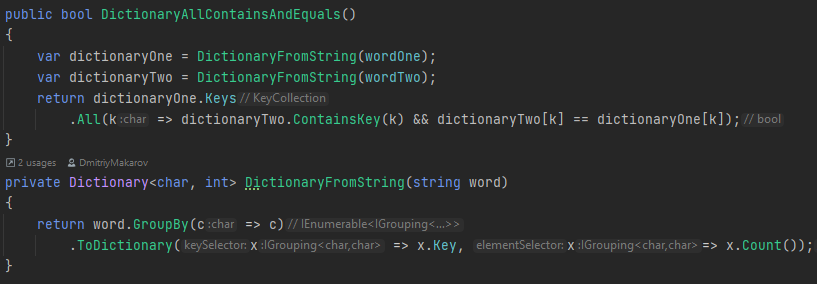
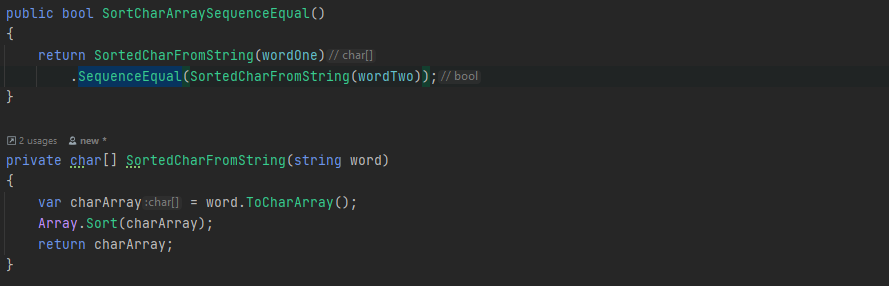
-Вариант из головы, преобразовать строку в массив символов отсортировать и применить SequenceEqual.
Выяснил что порядок символов не особо важен(бенч показал что разница в где то в 5 наносекунд), а вот количество символов для 6 и 18 символьных анаграмм играет очень большую роль т. к. поиск по меньшей прошел за 100 наносекунд, а по большей 300 наносекунд.
Вариант с отсортированным массивом символов, работает быстрее и занимает меньше места в памяти. В GitHub(лайк тоже приветствуется) прикрепил в описании полный бенчмарк, так же если есть еще какие либо варианты пишите в комментарии.
Поставил себе цель, набрать аудитории 100 человек, если ты мой читатель и можешь поспособствовать я буду очень благодарен.