Почему Твой Шейдер Медленный?
@shiko_qСказ о том как устроен GPU (очень кратко) и о некоторых, не самых очевидных нюансах производительности шейдеров.
Итак, представим, что:
Есть шейдер, который делает простой бокс-блюр. Это фуллскрин шейдер и в нашем примере он будет выполнять только свою фрагментную часть.

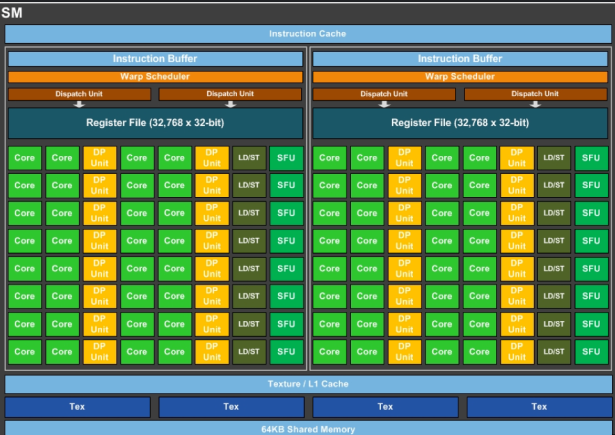
Есть мобильный гпу. У него 4 ядра. Каждое ядро - маленькая фабрика, и поэтому на каждом ядре есть 32 юнита ALU (которые считают математику) и 1 юнит текстурных читок. Так же у нас есть регистровый файл на каждое ядро в размере 8192 байта.
Допустим, разрешение 1920x1080, это даст 2 073 600 пикселей.
Но мы же помним, что TBR (большинство мобильных gpu именно такие) работает по тайлам, представим что на этом устройстве у нас тайл это 32x32 пикселя, значит у нас будет 60x34 тайла.

Тогда в каждый тайлик у нас войдёт 32x32 = 1024 пикселя.
В реальной жизни пиксели обрабатываются в растер пайплайне пачками 2х2 ради дерривативов (ddx/ddy) и растеризации, но предположим, что растеризации в нашем мире не существует и каждый пиксель обрабатывается отдельно, для упрощения.
Итак, у нас есть шейдер, который делает бокс-фильтр.
Что такое бокс-фильтр?
1. Посчитай uv1: сложи это число и это. 2. Сделай сэмпл из текстуры 3. Сложи результат 4. Посчитай uv2 ... N.: раздели результат на число сэмплов ret;
Инструкции зачитывает специальный отдельный модуль на ядре. Он один на ядро, в нашем примере (да и в реальности обычно тоже так).
Что такое тред?
Вот у тебя в шейдере, во frag метод приходит структура vert2frag. На каждый тред будут уникальные значения. Значит тредом можно назвать некий контекст пикселя. Его уникальный UV, его уникальную позицию, тексель текстуры куда будет сохранён результат. Вот этот скоуп значений, информации - это и есть тред. Можно условно представить, что пиксель = тред в нашем случае, но это не совсем так в реальности, ведь считаются 2х2 пикселя, помните? И это один тред, да. Но у нас для примера тред = пиксель, ладно.
Итак, на ядро есть планировщик, шедулер. Объединяет треды в группы, обычно по 32 штуки на группу (ведь у нас 32 ALU). Такую группу мы назовём "варп". Варп - это термин Nvidia, но сам концепт варпа есть во всех современных архитектурах, в amd это wavefront в apple, видимо, просто "группа тредов".
Допустим, у нас может быть максимум 32 варпа на ядро. Тогда планировщик возьмёт все наши треды (а это сейчас 1024 штуки), разобьёт их по 32 штуки и получит 32 варпа.
Это как раз и есть капасити ядра - 32 варпа. И если у нас из 32 возможных варпов загружено 32 - то у нас 100% occupancy, т.е. 100% занятость ядра.
Это количество (32 варпа по 32 треда, на 32х32 пикселя) не случайно, для лучшей утилизации оптимальный размер тайла будет равен максимальному числу варпов на ядро. НО размер тайла может меняться в зависимости от разных условий, например, от количества требуемой тайловой памяти. И если у тебя деферред пайплайн плохо написан (слишком много текстур в сабпассе), то можно по этой причине уменьшить размер тайла от чего перфа тоже может упасть: тредов на тайл будет меньше, чем доступно варпов.
Мы уже поняли, что ALU - это реальная маленькая электронка. Но варп - это "виртуальная единица", т.е. это просто группа лежащих рядом друг с другом, в регистровом файле, данных, которые объединены общим айдишником = оффсетом.
Работу работают только реальные юниты - ALU и текстурный. А нафига тогда варпы? Зачем нам держать целых 32 варпа "на лету", если выполняется только один?
Вот прилетел дроуколл на GPU, ядро взяло в работу первый варп.
Там по порядку идёт:
1. Посчитай uv1: сложи это число и это.
У нас 32 ALU и 32 треда. Посчитали за один такт. Дальше.
2. Сделай сэмпл из текстуры
Оп. А у нас 1 текстурный юнит. А читок нужно 32.
В лучшем случае у нас данные текстуры по запрошенным UV лежат уже в L2 кэше. Тогда текстурный юнит дотянется и за такт заберёт данные, потом ещё за несколько тактов их интерполирует (если включена, например, билинейная фильтрация).
Но что в это время делать 32 ALU?
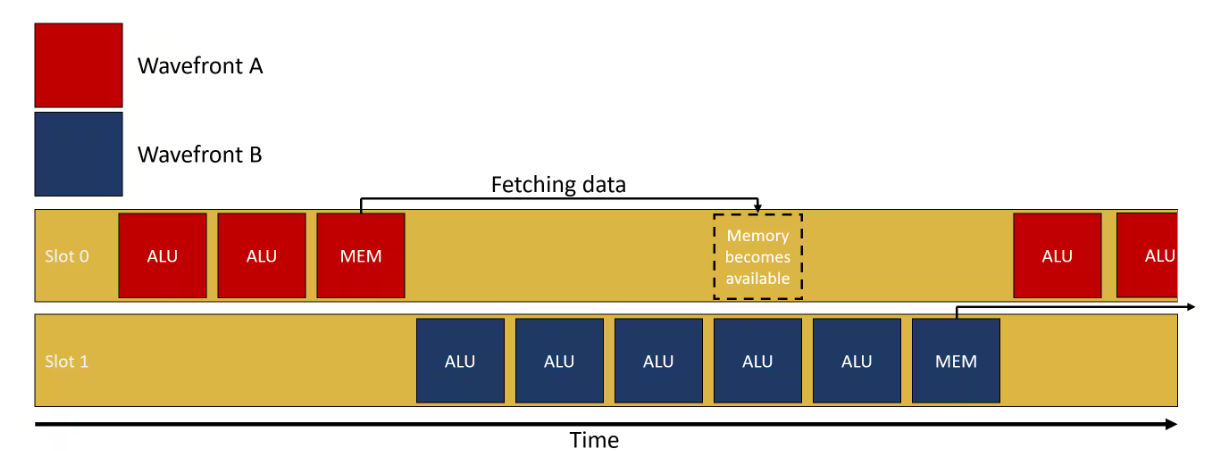
Вот тут нам и пригодятся варпы "на лету", шедулер просто переключит все ALU на другой варп и посчитает их значения.
Регистровый файл - это просто кусок памяти, особенность которого, что он распаян прямо на ядре и доступ к данным в нём буквально мгновенный.
У нас в этом файле лежат данные тредов, всех этих 32х32 пикселей. С оффсетом 32.
Если застряли на первых 32 ячейках, просто прыгни на вторые 32 ячейки и обработай инструкции для них.
(да, в реальности всё сложнее, помимо данных у нас ещё хранится стэк вызова - т.е. номер инструкции, да и ячеек может быть занято куда больше чем одна на тред - об этом чуть позже). Переключение варпов - по сути - мгновенное, ничего не стоит. И пока у нас текстурный модуль застрял на чтении текстур, мы пропрыгаем по всем варпам и посчитаем математику для всех.
В итоге, вот эти "один считаем, 31 в уме" варпы позволяют нам маскировать задержки, добиваясь того, чтобы все физические юниты были задействованы на полную мощь и шейдер выполнялся так быстро, как это только возможно.
Скажем, мы вернулись к первому варпу и обнаружили, что читки закончились а текстурный юнит трудится уже на втором варпе. Тогда делаем работу ALU для первого варпа и.... оп. А текстурный юнит для второго варпа ещё не отработал.
Такую ситуацию мы называем "stall on texture fetches" - и теперь ALU стоят и ждут пока текстурный юнит отработает. Если написать шейдер иначе, то можно от этого избавиться, но это тема для целой отдельной статьи.
Но это тоже не худшее, что может случиться.
Помните, я упоминал, что у нас 8192 байта в регистрах на ядро?
Допустим, у нас каждый тред занимает float2 (uv) + half4(цвет), тогда у нас float4 = 16 байт на тред. Значит у нас максимум может быть 8192 / 16 = 512 тредов нанято. А это всего 16 (512/32) варпов! Из максимальных - 32.
Тогда мы говорим что у нас occupancy = 16 / 32 = 50%. При нормальных условиях она должна быть от 50% до 100%. Если занятость меньше 50, то это грозит "проливкой регистров" - stack spilling, чаша регистров переполнена и она проливается в L1 кэш. А читать из L1 кэша намноооооого дольше, чем из регистров!
А если шейдер написан иначе и у нас считаются сначала uv1, uv2, uv3 и uv4 для разных читок? Мы же не можем использовать один регистр для них всех в таком случае, нам они нужны "раздельно", чтобы использовать для чтения текстуры. Тогда придется держать одновременно float2 + float2 + float2+ float2 + half4 = 40 байт! А это ещё больше занимает регистров и значит ещё меньше варпов можно нанять и стэк может пролиться.
TLDR;
Регистров надо использовать меньше, а код шейдера писать так, чтобы разные юниты (ALU, SFU, TU, и пр) не заставляли остальных ждать себя.
Чат по тех. графону: https://t.me/unity_cg
Источник: https://t.me/unity_cg/76092, https://t.me/unity_cg/76093