Пишем простой веб-скрапер для криптовалют
DartrisenГде-то год назад ко мне обратились с просьбой написать простенький веб-скрапер криптовалют. Это было в качестве тестового задания для какой-то вакансии. Для чего вообще нужен этот скрапер? Для доступа к данным интересующего тебя сайта в автоматическом режиме. Сразу оговоримся, доступа к API у тебя нет. Допустим, ты пишешь специального бота для покупки-продажи криптовалют, и тебе нужно в режиме реального времени отслеживать все колебания курсов. Ты "скрапишь" данные с сайтов, чтобы в дальнейшем их обрабатывать средствами языка python (например, статистически, или как-нибудь еще).
HTTP for Humans™
Начнем, пожалуй с requests. Requests используется для обработки http запросов. На мой вкус, requests гораздо удобнее тех же urllib/urllib2.
Мы будем использовать requests для получения html данных, а дальше мы будем парсить их с помощью bs4. В принципе, ты можешь использовать регулярные выражения, но я бы не советовал.
Получить данные можно с помощью requests.get(url, headers=None). Если разбираться как работает браузер, он передает в headers такие параметры как User-Agent и cookie, это сделано для того, чтобы отличить робота от реального человека. Иногда сайт также проверяет корректность cookie, в таком случае помогут sessions в библиотеке requests. Отметим эту важную для тебя информацию (пригодится в дальнейшем для написания ботов), и едем дальше.
О, прекрасный суп наварили.
Теперь перейдем к получению данных из html. Проще всего можно понять как устроена html-страница, используя функцию "Inspect Element" в браузере.
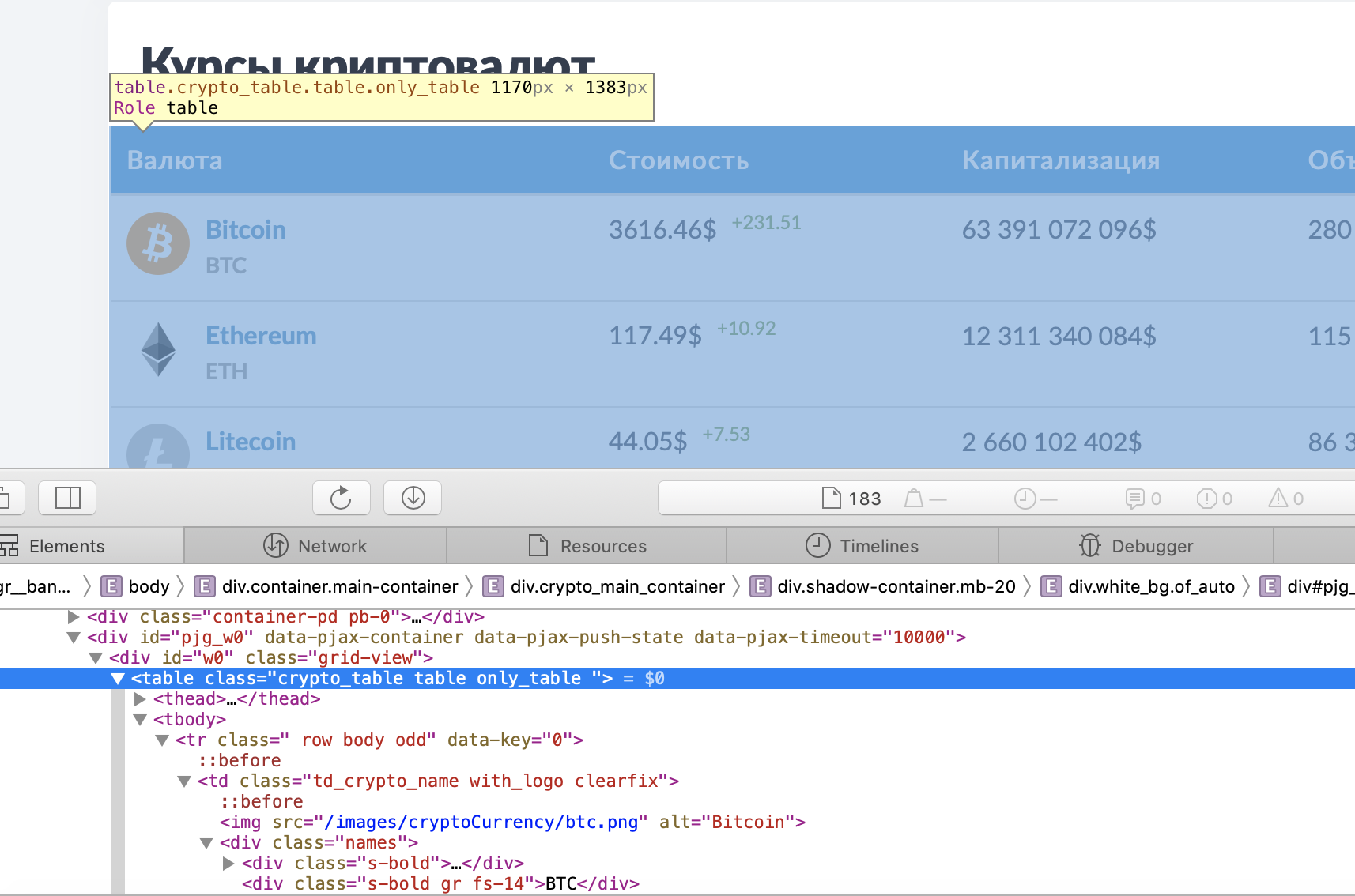
Стоит отметить, что ты можешь выбрать любой удобный для тебя сайт. В моем случае я остановился на https://bankiros.ru/crypto просто потому, что сайт весьма просто устроен и удобно использовать bs4.
Вся интересующая нас информация по крипте заключена в теге <table class="crypto _table">. Выделим эту ноду.
import requests
from bs4 import BeautifulSoup
url = "https://bankiros.ru/crypto"
html = requests.get(url).text
soup = BeautifulSoup(html, "html.parser")
table = soup.find("table", {"class" : "crypto_table"})
Для того, чтобы узнать что именно лежит внутри выбранной ноды в BeautifulSoup, можно просто распечатать ее.
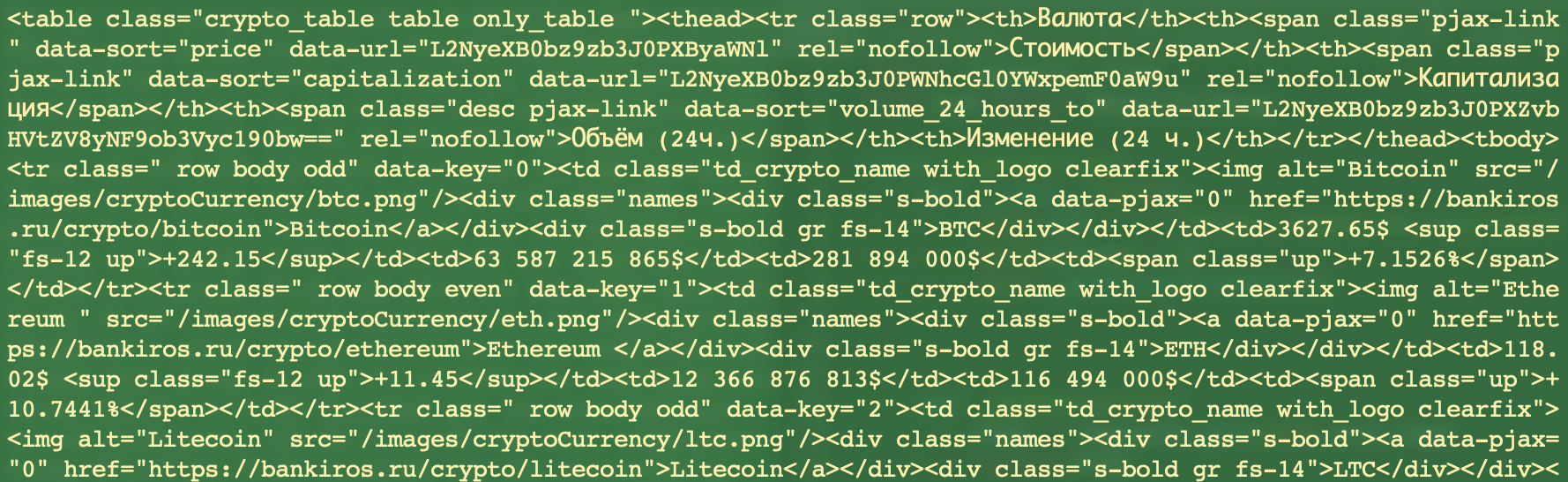
То, что нас интересует, находится между блоками <tr> и <td>. Теперь оформим код с помощью класса.
import requests
from bs4 import BeautifulSoup
class Crypto:
def __init__(self):
self.url = "https://bankiros.ru/crypto"
self.prices = []
def get_Html(self):
html = requests.get(self.url).text
return html
def parse_Html(self, html):
soup = BeautifulSoup(html, "html.parser")
table = soup.find("table", {"class" : "crypto_table"})
rows = []
for row in table.findAll("tr"):
cells = []
for cell in row.findAll("td"):
text = cell.text
cells.append(text)
rows.append(cells)
del rows[0]
return rows
Иногда между <tr>:<td> попадается пустой блок, который стоит удалить во избежание IndexError при обходе списка.
Создадим функцию get_prices_from_site
def get_prices_from_site(self):
self.prices = self.parse_Html(self.get_Html())
и добавим ее в __init__(self):
class Crypto:
def __init__(self):
self.url = "https://bankiros.ru/crypto"
self.prices = []
self.get_prices_from_site()
Таким образом, мы "спарсили" лист с данными по всем криптовалютам. Что с ними делать, решать уже тебе. Можешь, например, собирать их для дальнейшего статистического анализа с помощью pandas.
Исходники можно найти здесь.