Пишем первый ML-пайплайн на Airflow: подробный туториал 2 часть
2. Предсказание модели, zero-shot classification
Для начала определим список классов - тем, на которые мы будем разделять финансовые новости:
LABELS = [
"Crypto",
"SEC",
"Dividend",
"Economics",
"Oil or Gas",
"IPO",
"Politics",
"Buffet",
"Stock",
"Other",
]
Для получения предсказаний загрузим модель valhalla/distilbart-mnli-12-1 из Hugging Face Hub. device=-1 означает, что модель запускается на CPU.
from transformers import pipeline model_hf = pipeline(model="valhalla/distilbart-mnli-12-1", device=-1)
Далее загрузим csv файл с новостями, который мы подготовили в предыдущем пункте. Для предсказания будем использовать объединение текста из заголовка новости (title) и ее краткого описания (summary).
import pandas as pd df = pd.read_csv(data_path, sep="\t") texts_for_pred = (df.title + ". " + df.summary).tolist()
Для получения предсказаний передадим модели список текстов texts_for_pred и классы LABELS:
pred = model_hf(texts_for_pred, LABELS, multi_label=False)
Флаг multi_label определяет, может ли объект быть отнесен к одному или более классам. Когда multi_label=True, модель может присваивать объектам несколько классов одновременно.
Таким образом, мы сами придумали название классов на свое усмотрение. Модель делает предсказание по нашим классам без необходимости предварительного обучения. В этом преимущество zero-shot моделей.
Благодаря библиотеки transformers код занял всего несколько строк.
Выберем предсказание лучшего класса и сохраним результат в json-файл:
df["label"] = [x["labels"][0] for x in pred] df.T.to_json(pred_path)
На этом код предсказания готов.
Добавим логирование и использование Click по аналогии с кодом загрузки данных. Тогда финальная версия model_predict.py будет выглядеть следующим образом:
import logging
import click
import pandas as pd
from transformers import pipeline
LABELS = [
"Crypto",
"SEC",
"Dividend",
"Economics",
"Oil or Gas",
"IPO",
"Politics",
"Buffet",
"Stock",
"Other",
]
logging.basicConfig(level=logging.INFO)
@click.command()
@click.option("--data_path", help="Path to the input data CSV file")
@click.option("--pred_path", help="Path to save the output JSON file")
def model_predict(data_path: str, pred_path: str) -> None:
logging.info("Loading the model...")
model_hf = pipeline(model="valhalla/distilbart-mnli-12-1", device=-1)
logging.info("Model loaded successfully.")
logging.info(f"Reading data from '{data_path}'...")
df = pd.read_csv(data_path, sep="\t")
logging.info("Data read successfully.")
texts_for_pred = (df.title + ". " + df.summary).tolist()
logging.info("Performing model prediction...")
pred = model_hf(texts_for_pred, LABELS, multi_label=False)
logging.info("Prediction completed successfully.")
df["label"] = [x["labels"][0] for x in pred]
logging.info(f"Saving the predictions to '{pred_path}'...")
df.T.to_json(pred_path)
logging.info("Predictions saved successfully.")
if __name__ == "__main__":
model_predict()
Код предсказания модели будет также запускаться в отдельном Docker-контейнере. Поэтому аналогично предыдущему пункту мы добавили свои requirements.txt и Dockerfile.
Итак, мы подготовили код для 2 компонент нашего пайплайна: загрузки данных и получения предсказания модели. Каждый будет выполняться в отдельном Docker-контейнере. Теперь все готово, чтобы мы перешли к написанию DAG на Airflow.
3. Пишем DAG
Вспомним основные компоненты нашего пайплайна:
- 3 последовательные таски, первые 2 из которых должны запускаться в отдельных Docker-контейнерах.
- Локальная директория
data, которую мы будем использовать для сохранения результатов и обмена данными между тасками.
Разберем основные шаги при написании нашего DAG:
- Локальную директорию
dataнужно примонтировать к/opt/airflow/data/- это путь к данным внутри контейнера Airflow.
from docker.types import Mount
dockerops_kwargs = {
"mount_tmp_dir": False,
"mounts": [
Mount(
source="<path_to_your_airflow-ml_repo>/data",
target="/opt/airflow/data/",
type="bind",
)
],
...
}
- Определим пути для трех типов файлов: исходные данные, предсказания и файл с результатом. Они используют специальный синтаксис Airflow
{{ ds }}, который будет заменен на дату выполнения при запуске DAG.
raw_data_path = "/opt/airflow/data/raw/data__{{ ds }}.csv"
pred_data_path = "/opt/airflow/data/predict/labels__{{ ds }}.json"
result_data_path = "/opt/airflow/data/predict/result__{{ ds }}.json"
- Создадим DAG. Декоратор
dagсоздает DAG с названиемfinancial_newsс начальной датой сегодня (days_ago(0)) и ежедневным запуском. Функцияtaskflowпредставляет собой сам DAG и содержит задачи, формирующие пайплайн.
from airflow.decorators import dag
from airflow.utils.dates import days_ago
# Create DAG
@dag("financial_news", start_date=days_ago(0), schedule="@daily", catchup=False)
def taskflow():
...
- Создадим две таски для запуска в Docker-контейнерах. Для это будем использовать
DockerOperator. Здесь мы указываем имя образа (этот образ будет описан вdocker-compose.yml) и команду для запуска питоновского скрипта внутри контейнера.
# Task 1
news_load = DockerOperator(
task_id="news_load",
container_name="task__news_load",
image="data-loader:latest",
command=f"python data_load.py --data_path {raw_data_path}",
**dockerops_kwargs,
)
# Task 2
news_label = DockerOperator(
task_id="news_label",
container_name="task__news_label",
image="model-prediction:latest",
command=f"python model_predict.py --data_path {raw_data_path} --pred_path {pred_data_path}",
**dockerops_kwargs,
)
- Создадим последнюю таску, она преобразует полученные предсказания питоновским кодом. Мы будем использовать
PythonOperator, который выполнит несложный скрипт группировки предсказаний.
# Task 3
news_by_topic = PythonOperator(
task_id="news_by_topic",
python_callable=aggregate_predictions,
op_kwargs={
"pred_data_path": pred_data_path,
"result_data_path": result_data_path,
},
)
- Установим зависимости между задачами. В нашем случае они выполняются последовательно:
news_load >> news_label >> news_by_topic
- Наконец, создадим и настроим объект DAG в соответствии с заданными параметрами:
taskflow()
Файл с описанием DAG имеет расширение .py и лежит в директории dags. При запуске Airflow, он сканирует эту директорию (или другую настроенную директорию) в поисках файлов с определением DAG. Когда Airflow обнаруживает файл с определением DAG, он регистрирует его и делает доступным для выполнения по расписанию.
Мы закончили писать наш пайплайн, теперь перейдем к настройке и запуску Airflow.
4. Запуск Airflow с помощью Docker Compose

Для локального запуска Airflow мы будем использовать Docker Compose. Он помогает запустить Apache Airflow с минимальными усилиями, предоставляя унифицированный и изолированный способ запуска всех компонентов Airflow.
У Airflow есть отличная инструкция по запуску с помощью Docker Compose. Там же есть загрузка готового файла docker-compose.yml. Инструкция позволяет запустить Airflow в пару строк.Файл docker-compose.yml имеет раздел services, где определены различные сервисы, которые являются частями кластера Airflow. Каждый сервис имеет свою секцию с настройками, где указывается образ Docker, команда для запуска сервиса, порты, зависимости от других сервисов и другие параметры. В частности здесь описаны сервисы для Metadata Database, Webserver и Scheduler, которые мы упомянали в разделе Знакомство с Airflow.
Модификация docker-compose.yml для запуска тасок в отдельных Docker-контейнерах
Поскольку мы усложнили настройку Airflow, когда решили запускать таски в отдельных контейнерах, будем использовать свой модифицированный docker-compose.yml. Его можно посмотреть тут.
Основные моменты, которые мы изменили для поддержки запуска тасок в Docker-контейнерах:
- Установили пакет для поддержки работы с Docker:
_PIP_ADDITIONAL_REQUIREMENTS: apache-airflow-providers-docker==3.6.0
- В список volumes добавили монтирование директории с данными и сокета Docker:
volumes:
- ${AIRFLOW_PROJ_DIR:-.}/data/:/opt/airflow/data/
- /var/run/docker.sock:/var/run/docker.sock
- Ранее в директориях
ml_pipeline/data_loaderиml_pipeline/model_predictionмы написали инструкции по созданию Docker-образов, которые импользуются для запуска тасок с помощью DockerOperator. Здесь мы также определяем эти сервисы:
data-loader:
build:
context: ml_pipeline/data_loader
image: data-loader
restart: "no"
model-prediction:
build:
context: ml_pipeline/model_prediction
image: model-prediction
restart: "no"
- Добавим сервис
docker-socket-proxy:
# Required because of DockerOperator. For secure access and handling permissions.
docker-socket-proxy:
image: tecnativa/docker-socket-proxy:0.1.1
environment:
CONTAINERS: 1
IMAGES: 1
AUTH: 1
POST: 1
privileged: true
volumes:
- /var/run/docker.sock:/var/run/docker.sock:ro
restart: always
Запуск Airflow
Возможно, в вашем случае запуск потребует выделения больше памяти для Docker Engine.
Перед первым запуском Airflow нужно подготовить окружение.
Если вы работаете на Linux перед запуском нужно указать AIRFLOW_UID:
echo -e "AIRFLOW_UID=$(id -u)" > .env
Далее независимо от вашей ОС необходимо выполнить миграцию базы данных и создать первую учетную запись пользователя. Для этого выполните команду:
docker compose up airflow-init
Созданная учетная запись имеет логин airflow и пароль airflow.
Запуск и остановка Airflow
Для создания и запуска всех необходимых контейнеров, определенных в файле docker-compose.yml, используется команда:
docker compose up
В нашем случае также необходимо предварительно собрать образы data-loader и model-prediction, которые также указаны в файле docker-compose.yml. Поэтому модифицируем команду:
docker compose up --build
Когда вы закончите работу и захотите очистить свое окружение, выполните:
docker compose down --volumes --rmi all
После запуска Airflow продолжим работу в веб-интерфейсе.
5. Веб-интерфейс Airflow, запуск пайплайна
Пользовательский интерфейс Airflow упрощает мониторинг и запуск пайплайнов. Он доступен по адресу http://localhost:8080. На странице входа нужно ввести логин и пароль от учетной записи, в нашем случае airflow и airflow.
Запуск и мониторинг пайплайна
На домашней странице вы увидете список всех дагов, включая дефолтные от Airflow. Здесь можно найти и выбрать созданный нами DAG financial_news.

На странице нашего DAG доступна разная информация о пайплайне: графическое представление, время ближайшего запуска, логи запуска, код и многое другое.
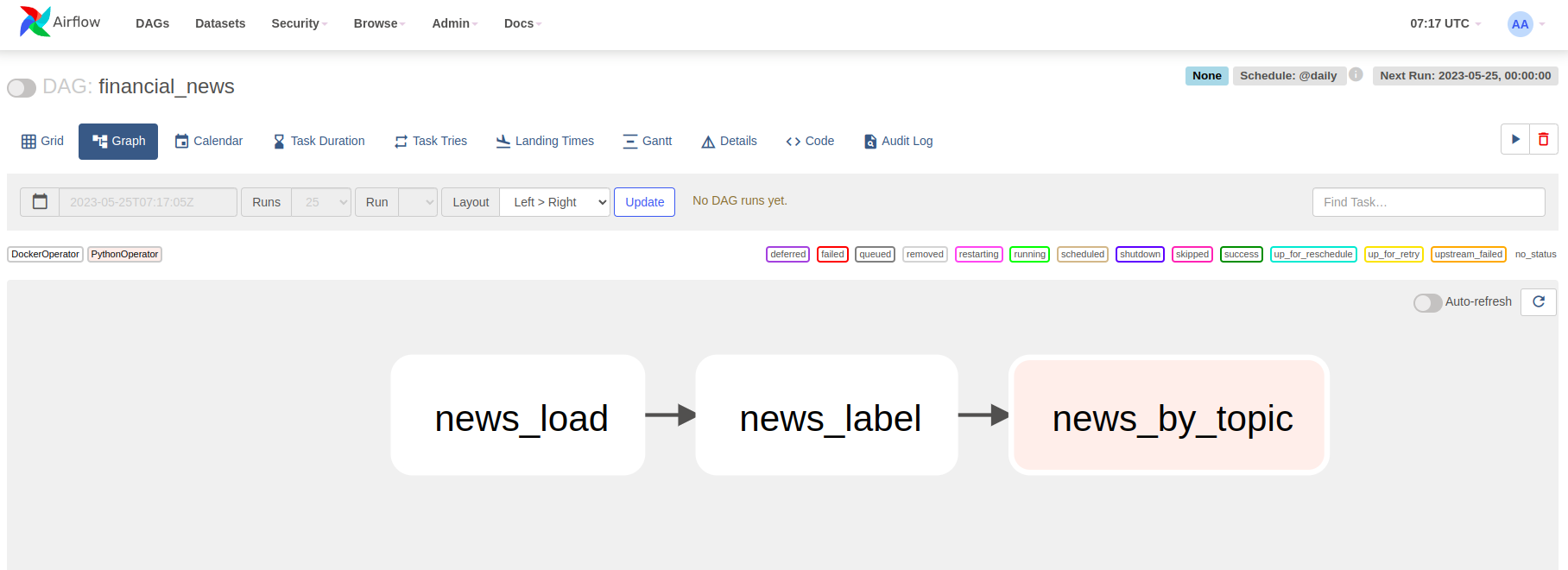
Не дожидаясь планового запуска пайплайна, запустим DAG, нажав на кнопку старта. Для отслеживания выполнения отдельных тасок, можно нажать на нужную таску и посмотреть ее логи:
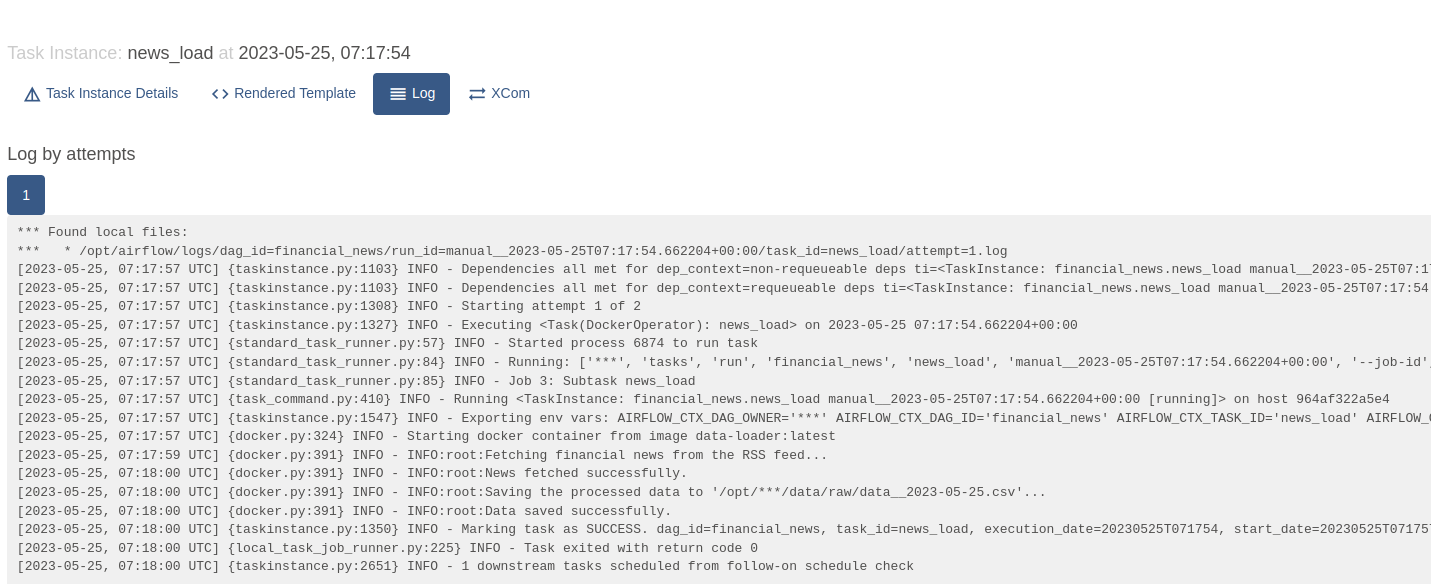
Здесь мы можем видеть логи, которые добавили специально для отслеживания выполнения отдельных шагов.
После того, как выполнение пайплайна успешно завершилось, посмотрим на результаты.
Смотрим результат пайплайна. Как классифицировались новости?
Результаты выполнения пайплайна сохранились в data/predict/result__<date>.json. Изначально мы ставили задачу написать пайплайн, которые будет автоматически загружать актуальные новости из финансового мира и группировать их по заданным нами темам. Посмотрим, что у нас получилось.

Таким образом, мы справились с поставленной задачей. Новости успешно загружаются и классифицируются. Напомним, что темы заданы нами произвольно, без предварительного обучения модели.