Перевод: 5 методов обнаружения API
@Ent_TranslateIBВо время тестирования одной из самых интересных частей является ее API. API - это динамика, они обновляются чаще, чем другие части приложения, и отвечают за многие из тяжелых задач бэкенда. В современных приложениях мы обычно видим REST API, но есть и другие формы, такие как GraphQL и даже SOAP.
Когда мы впервые подходим к цели, нам предстоит провести много исследований, чтобы понять основные функции и то, как они работают за кулисами. Конечно, всегда рекомендуется выделить некоторое время на чтение информации о цели и ее сервисах. Например, если мы тестируем приложение для аренды автомобилей, то в самом начале неплохо было бы почитать об услугах компании (аренда, продажа, поддержка, скидки и т. д.). Зная о сервисах нашей цели, мы будем искать отраженные функции в ее приложении и пытаться их сломать.
В этой статье мы расскажем о методах разведки API, чтобы получить хорошее представление о поверхности атаки. Здесь мы не будем рассматривать распространенные атаки на API, так как это будет в другой статье.

Зачем использовать специальные методы разведки API, а не просто пользоваться приложением?
Важно сказать, что это хорошая практика - "нажимать на каждую кнопку", которую вам показывает приложение. Самый простой способ понять функцию - просто использовать ее и проанализировать полученный ответ.
И все же не всегда кнопки на экране включают в себя все API, которые содержит приложение. Основные три причины, по которым мы должны считать, что видим лишь частичную картину API:
- Мы не знаем, есть ли у пользователя с другим уровнем привилегий больше API, чем у нас.
- Возможно, существуют недокументированные API, для которых разработчики не создали веб-интерфейс
- Могут быть старые API, для которых разработчики удалили веб-интерфейс, но они все еще функционируют на бэкенде.
Еще одна веская причина провести тщательную разведку API - это отличный способ узнать больше об основах и ядре приложения, а заодно и раскрыть секреты.
#1 - Документация API
Не всегда, но во многих случаях мы тестируем цель, которая запускает продукт, приложение, имеющее доступную документацию по своему API, например Swagger или WSDL-файл. Обычно документация выложена для удобства использования другими разработчиками, которые хотят интегрировать API в свои приложения. Но иногда документация находится в открытом доступе без какой-либо причины, кроме чрезмерного раскрытия.
В любом случае, это очень полезная информация. Она не только отображает конечные точки API основного приложения, но и объясняет, как функционирует сам API:
- Какие данные ожидает получить конкретная конечная точка (целое число/строка, JSON/XML, POST/PUT/GET и т. д.)
- Необходимые заголовки для отправки
- Ответ, который мы должны получить в ответ на запрос
- Уровень аутентификации, необходимый для конкретной конечной точки
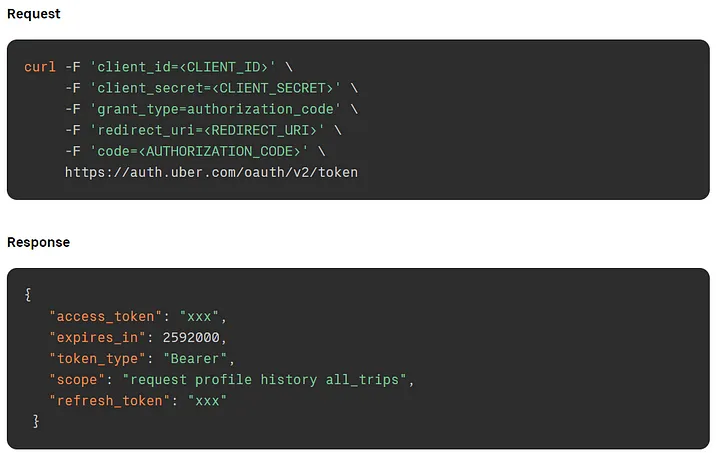
На примере выше мы видим, как Uber предоставляет документацию по API для других разработчиков. Обратите внимание на различные заголовки в запросе, которые включают некоторые параметры, такие как код авторизации, идентификатор клиента и секрет клиента. Эти параметры могут быть важны для корректной работы API, и документация дает нам отличное этому объяснение.
Еще один способ использовать документацию по API приложения - найти его файлы Swagger/WSDL. Мы можем не только прочитать их, чтобы понять структуру API, но и загрузить эти файлы в Postman и начать играть с ними!
Не у каждого приложения она есть, но поиск и чтение документации может сэкономить нам время и дать ответы почти на все вопросы о приложении.
В случае если у нашей цели нет документации по API, мы можем создать собственную документацию к приложению без особых усилий.
#2 - Исследование API (OSINT)
Как мы уже говорили, API - это очень динамичная часть приложения, и она имеет тенденцию меняться время от времени. Это означает две важные вещи:
- Разработчики постоянно работают над API и, вероятно, используют различные инструменты для создания, тестирования и документирования различных версий API.
- Велика вероятность, что существуют старые версии API приложения, которые мы можем найти, и, возможно, они менее безопасны, чем текущая версия, используемая в производстве!
Давайте поговорим о нескольких инструментах OSINT, которые мы можем легко использовать для получения результата.
Google Dorking
Сочетание расширенных возможностей поиска Google и некоторых ориентировочных ключевых слов для API - одно из первых, с чего стоит начать, когда мы приближаемся к цели. Быстрый поиск по доркингу в Google может дать нам:
- Поддомены цели, связанные с API
- Страница документации API цели
- конечные точки API - старые и текущие версии
Вот пример некоторых результатов о Starbucks:
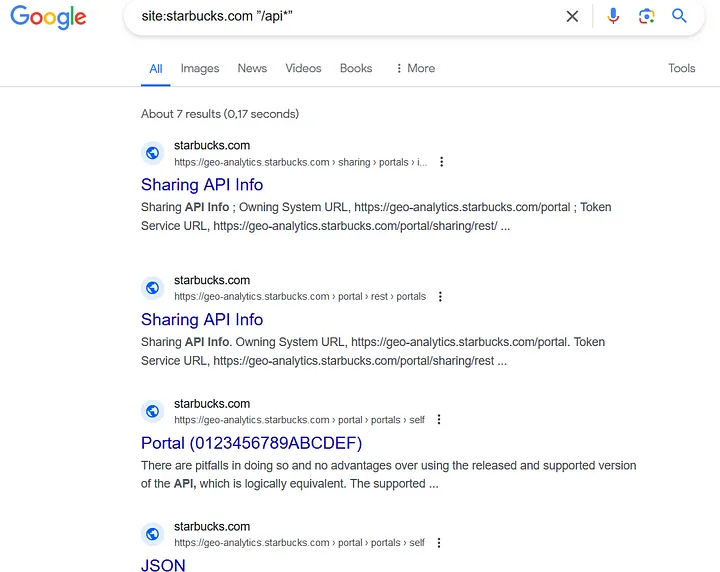
Этот простой поиск, конечно, не отображает всю поверхность API Starbucks, но он дает нам несколько ссылок на поддомены компании, содержащие ее API.
Вот еще несколько полезных форм поиска:
- site:target.com inurl:"/v1"
- site:target.com inurl:"/api"
- site:target.com inurl:"/graphql"
- site:target.com intitle: "api*"
WaybackMachine
Одним из лучших инструментов для поиска конечных точек API и одновременного сбора секретов является WaybackMachine. Все мы знаем, что с помощью поиска по URL-адресу мы можем просмотреть страницу цели в определенную дату. Волшебство заключается в том, что мы также можем получить список URL в GET-запросах. Обратите внимание на изображение ниже:
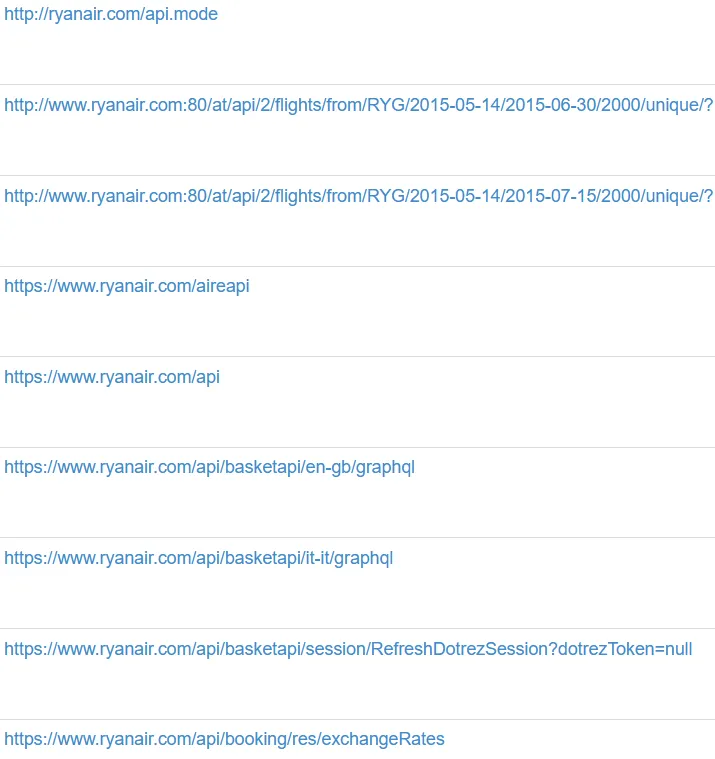
Просто выполнив поиск по домену компании и отфильтровав его по слову "api", мы получили несколько конечных точек API, содержащих даже GraphQL.
А если мы посмотрим на другие поддомены компании, то, вероятно, увидим все больше и больше конечных точек API. Во многих случаях мне удается найти в Wayback такие учетные данные, как имена пользователей, токены, аутентификационные ключи и JWT.

Используя эти найденные учетные данные, я могу иногда проверять конечные точки API после аутентификации с различными правами пользователей.
Также рекомендуется интегрировать GAU или Waymore в автоматизацию разведки для получения большего количества конечных точек API.
Postman
Это один из самых распространенных инструментов для разработчиков, позволяющий тестировать API без необходимости использования внешнего интерфейса для отправки запросов и гораздо более удобный, чем просто использование curl.
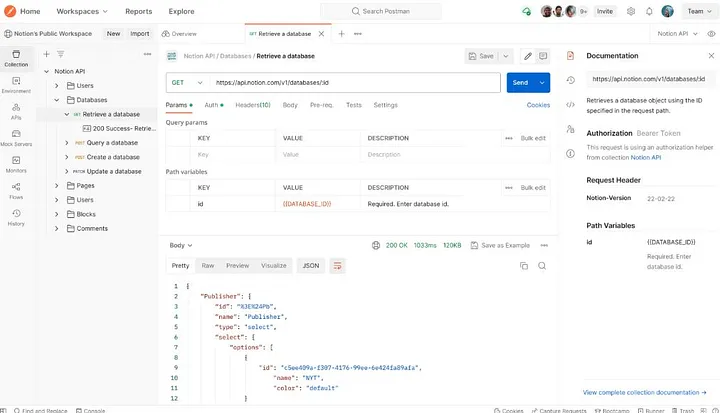
Postman доступен в виде SaaS-приложения на сайте postman.com и позволяет разработчикам обмениваться проектами, чтобы облегчить работу команд. Проект Postman, также известный как "коллекция Postman", обычно считается закрытым. Но во многих случаях вы увидите, что коллекции публично открыты. В коллекциях есть множество деталей, таких как параметры, заголовки, тело данных, переменные окружения и токены авторизации.
Если нам посчастливилось получить в руки "коллекцию postman" нашей цели, то это может быть даже лучше, чем найти официальную страницу документации по API. Это не просто примеры без реального содержания, которые мы там видим, это реальные запросы, отправленные разработчиками приложения, и реальные ответы от бэкенда. Мы можем многое узнать о внутренней среде приложения и базовом ядре цели. И одна из самых приятных деталей - учетные данные, которые обычно имеют высокие права на запросы к бэкенду!
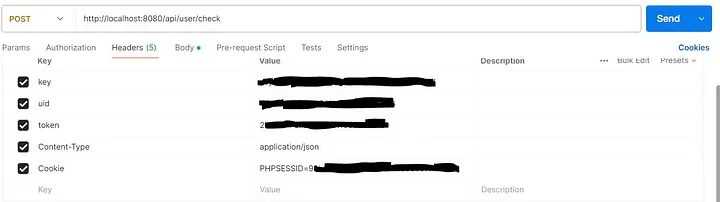
На изображении выше мы видим коллекцию postman, принадлежащую одному из моих клиентов. Как вы можете видеть, это пример POST-запроса, отправленного на localhost:8080, поскольку он был отправлен в среду staging. Однако токен и cookie все еще действительны для использования в пентесте на продакшене.
GitHub
Это не всегда так, но если у вашей цели есть репозиторий GitHub, доступный вам, то потратить немного времени на изучение кода приложения - всегда хорошая идея. С помощью нескольких ключевых слов мы максимально увеличим наши шансы найти конечные точки API и подробное объяснение того, как они работают.
Некоторые общие ключевые слова для API:
- /v1
- /api
- apikey
- api_key
- apidocs
- api_secret
- x-api-key
- /graphql
Как и в случае с Postman и WaybackMachine, в GitHub у нас есть все шансы найти секреты и учетные данные, которые могут пригодиться на следующих этапах работы.
#3 - HTML и Javascript приложения
Для того чтобы отправить API-запрос с фронтенда на бэкенд, приложение фронтенда использует Javascript для вызовов XHR/AJAX. Это означает, что сами конечные точки API должны быть указаны в исходном коде клиентской части. В FireFox, если мы откроем DevTools (F12) и откроем вкладку Debugger (или вкладку Sources в Chrome), мы увидим адрес нашей цели и маленькую стрелку, указывающую вниз. Нажав на стрелку, мы получим ресурсы фронтенда, включая Javascript-файл.
Найдя файлы Javascript, мы обычно получаем кусок минифицированного кода, без новых строк и пробелов. Это происходит для повышения производительности и удобства работы пользователей. В этом случае мы можем использовать JS-пректификатор, как этот. После этого просто скопируйте код в редактор кода, например VSCode или Sublime, и начните поиск API-запросов.
Чтобы искать вызовы API в коде, нам сначала нужно понять структуру вызовов API в приложении. Не поленитесь потратить некоторое время на чтение различных функций и переменных, которые вы видите. Ищите такие ключевые слова, как API, v1, v2, user и другие распространенные слова, связанные с API. Еще один момент - поиск HTTP-методов, которые указывают на отправку запроса на бэкэнд.
Также, если нам нужен автоматизированный инструмент, мы можем использовать Katana. Это хороший краулер с множеством различных флагов, которые можно добавить, чтобы настроить его под нашу цель. Одна из самых важных функций Katana - парсинг Javascript. С ее помощью мы можем запустить множество JS-файлов и за несколько мгновений получить первое представление об API на цели. Хорошей рекомендацией будет использовать Katana, просмотреть результат, а затем запустить ее снова, сделав несколько дополнительных настроек для конкретного веб-приложения.
Просматривая HTML и Javascript приложения, мы можем отобразить большинство вызовов API и даже раскрыть теневые API. В одном из моих последних проектов пользовательский интерфейс приложения показывал около 30 вызовов API, в то время как после извлечения кода Javascript я смог раскрыть более 140 конечных точек API, которые не могли быть раскрыты просто при использовании приложения.
Из-за того, что теневые API имеют небольшую уязвимость, они, как правило, имеют более высокий потенциал уязвимостей, поскольку их также очень редко тестируют.
#4 - Активное сканирование - фаззинг
Ранее мы говорили только о пассивных способах обогащения поверхности API, с минимальным контактом с самой целью. Пассивные действия все еще позволяют нам обнаружить многие, даже большинство конечных точек API, которые существуют на бэкенде. Но что происходит, когда есть конечные точки API, которые не должны быть открыты приложению, с которым мы возимся? Я не говорю о теневых API, я говорю о других конечных точках, которые существуют на бэкенде и должны обслуживать другое приложение, например, внутреннее приложение или приложение для сотрудников.
Например, этот случай актуален, когда компания разрабатывает несколько фронтенд-приложений (web&mobile), которые получают данные из одного бэкенда (api.target.com), например, одна панель для клиентов, другая - для менеджеров.
Если второе приложение недоступно для нас или мы даже не знаем о его существовании, с помощью фаззинга мы можем найти больше конечных точек для взлома!
Когда речь заходит о фаззинге API, необходимо учитывать две важные вещи:
- Фаззеры/сканеры: по сути, это инструмент, который посылает HTTP-запросы и фильтрует ответы, которые мы должны предварительно определить, что будет нам интересно.
- Словари: содержимое, которое мы проверяем. Хорошие словари - это разница между поиском уязвимости по общим словам и пустой тратой времени.
Давайте поговорим о них.
Фаззеры
В наши дни существует множество инструментов, которые отлично справляются с обнаружением API с помощью фаззинга. Для простых GET-запросов со списком конечных точек мы всегда можем использовать такие инструменты, как Burp Intruder, ffuf, GoBuster, Kiterunner и даже создать свой собственный фаззер. В большинстве случаев я считаю ffuf и Kiterunner отличными инструментами, не только с точки зрения скорости, но и полезных функций, таких как фильтрация по размеру, коду статуса, словам и прочему. Если говорить конкретно о Kiterunner, то, объединив соответствующие списки из Assetnote, этот инструмент отлично подходит для современных веб-приложений (NodeJS, Flask, Rails и т. д.).
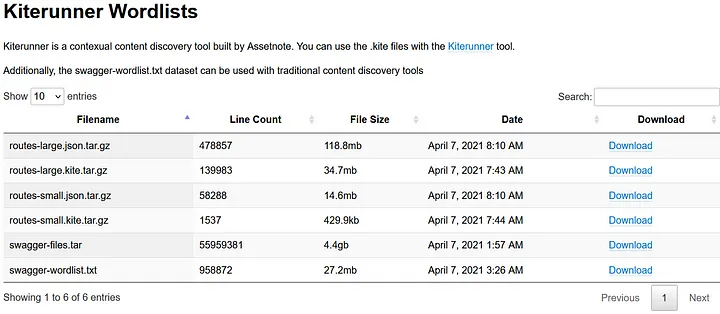
С помощью одной команды вы можете получить очень хорошее представление о картине API:
./kr scan https://target.com -w ~/wordlists/routes-large.json
Кроме того, кроме конечных точек API нам также необходимо выяснить, какие параметры принимаются бэкендом. Конечно, есть параметры "по умолчанию" для легитимных запросов, но что если есть и "теневые параметры"? Возможно, нам удастся найти уязвимость массового присвоения, которую мы никак не можем обнаружить, кроме как с помощью фаззинга. Для решения этой задачи я считаю Arjun одним из лучших инструментов.
Arjun - это python-инструмент, который просто отправляет GET-запросы к заданному URL с большим количеством различных параметров. В конце он предоставит нам список валидных параметров для дальнейшего тестирования.
Словари
Использование правильного словаря - это ключ к успешному тестированию API. Есть несколько отличных ресурсов для выполнения этой задачи: SecLists, Assetnote, FuzzDB и другие.
Ленивые хакеры будут использовать общие словари, которые просто содержат огромное количество слов, но без какой-либо конкретной цели. Профессионалы всегда будут стараться получить более конкретные словари в зависимости от цели. Например, если мы знаем, что наша цель - веб-приложение для аренды автомобилей, основанное на Django в качестве бэкенда, мы можем объединить общие словари для Django с пользовательскими словарями для аренды автомобилей. Для первого словаря мы можем использовать assetnote:
А для второго мы можем попросить ChatGPT сгенерировать список общих конечных точек API для аренды автомобилей:
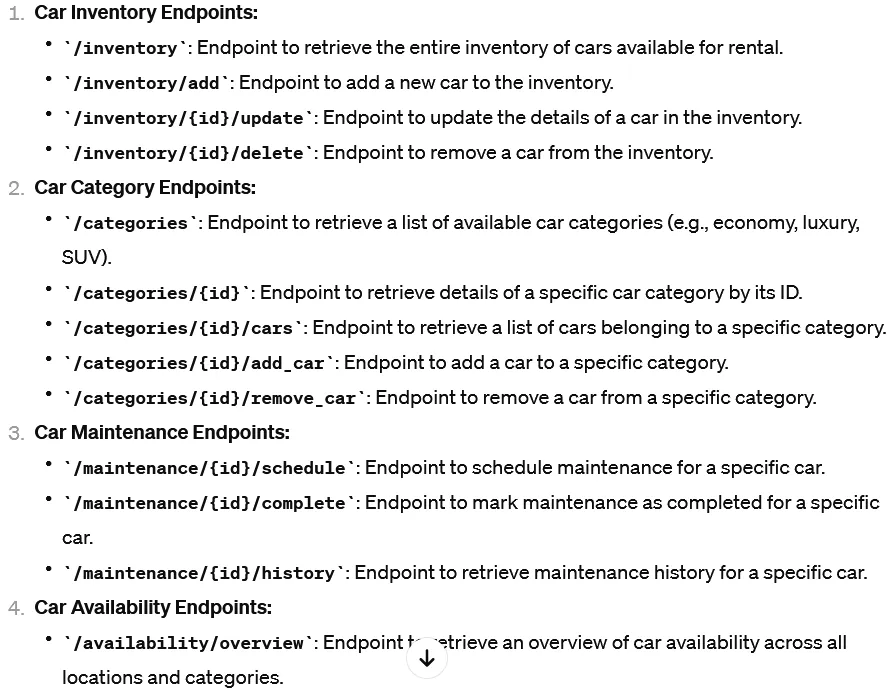
#5 - Мобильный
Допустим, наша цель - компания по доставке. У нее есть веб-приложение, где мы можем сделать заказ, оплатить его и, возможно, воспользоваться некоторыми другими функциями. Но если у компании есть мобильное приложение, есть вероятность, что в нем есть некоторые функции, которые могут быть доступны специально для мобильных телефонов, например, определение точного местоположения по GPS.
В этом случае это может означать, что API, существующие в Javascript веб-приложения, не будут совпадать с конечными точками API в APK-файле.
Тестирование мобильных приложений - это отдельная тема, поэтому мы не будем вдаваться в подробности в этой статье, но мы можем использовать инструменты статического анализа, такие как JADX и MobSF, для обнаружения некоторых жестко закодированных конечных точек API, которые находятся в APK.
Есть несколько зеркальных сайтов, таких как APKPure, с которых мы можем скачать APK на нашу машину, чтобы открыть его с помощью инструментов анализа. Всегда рекомендуется использовать статический и динамический анализ, чтобы выявить каждый вызов, который посылает приложение, но для начала очень эффективно использовать такие инструменты, как MobSF.
MobSF - это автоматизированный инструмент анализа, который берет APK-файл и строит отчет о внутреннем устройстве файла:
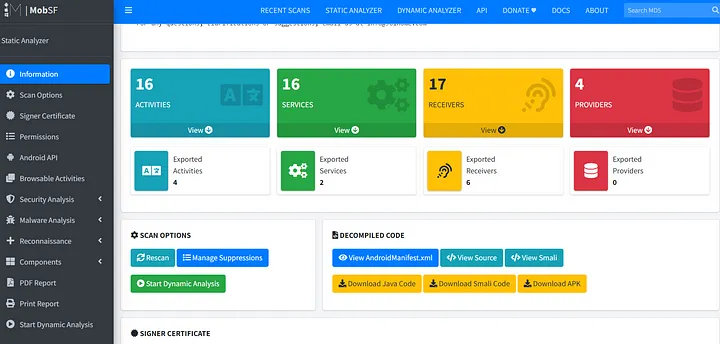
Из отчета мы можем получить некоторые жестко закодированные URL и домены, которые помогут нам составить более полную картину об API.
Резюме
Когда мы тестируем API, мы должны хорошо понимать, как работает приложение, какие функции оно предлагает и какова вся доступная нам поверхность. Используя вышеописанные методы, мы тщательно построим картину приложения и получим отличную основу для тестирования API различных приложений.
Взлом API иногда больше похож на исследование, в ходе которого нам приходится использовать различные инструменты, ресурсы и даже ручные методы, чтобы обнаружить каждый его кусочек. Если мы концентрируемся на цели в течение длительного времени (недели или месяцы), мы, вероятно, увидим, что ее API меняются и развиваются с каждым разом, и лучшее время для их взлома - это время, когда они совсем новые или все еще находятся в тени.
Оригинал статьи - здесь.
Поддержите автора хлопками на Medium.
Перевод статьи был выполнен проектом перевод энтузиаста:
- 📚 @Ent_TranslateIB - Телеграмм канал с тематикой информационной безопасности