Оптимизируем и ускоряем Automatic1111, полный гайд
Neurogen News - новости и релизы из мира нейросетей
В данном гайде мы разберем все наиболее доступные способы ускорения и оптимизации работы Automatic1111. Указанные здесь способы пригодятся для абсолютно всех видеокарт Nvidia вплоть до RTX 4090.
Инструкции будут указаны для актуальной версии автоматика, если у вас старая - обновитесь.
В данной статье рассматриваются рекомендации для видеокарт от 8 Гб видеопамяти. Если у вас видеокарта слабее, то прочтите дополнение:
Оптимизируем использование видеопамяти Automatic1111
Информацию для видеокарт от AMD и Intel, к сожалению, привести не могу, в виду отсутствия данных. Кроме этого, информация в сети очень сильно разнится и у меня не получилось составить единой картины по данному вопросу.
Материал подготовлен телеграм каналом Neurogen News.
Обновляем драйвера видеокарты
Самый базовый, но и самый основной шаг. Время от времени работа драйверов со Stable Diffusion улучшается, что позволяет получить увеличенную скорость генераций.
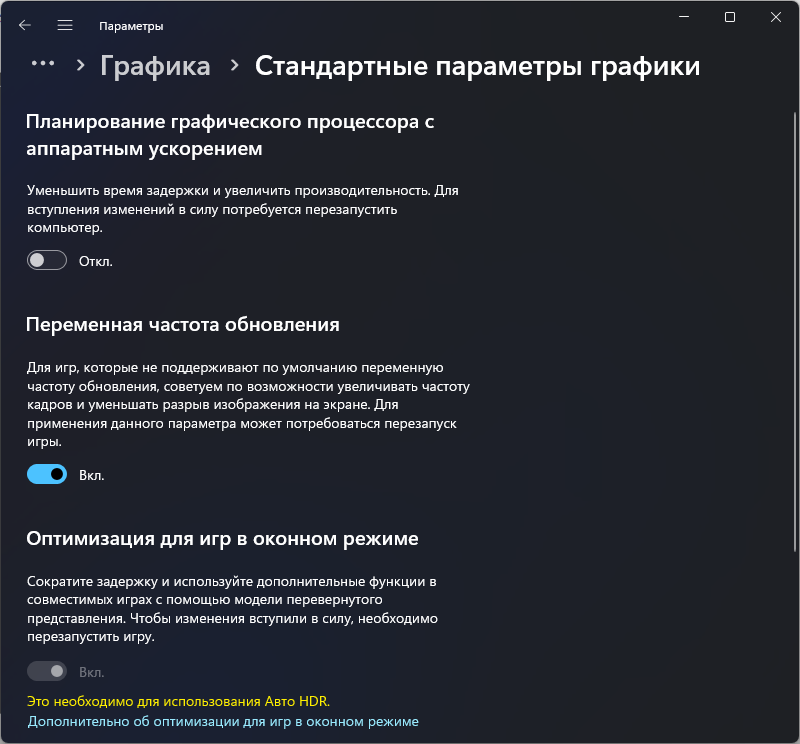
Отключаем планирование графического процессора
По неизвестной на данный момент причине, планирование графического процессора с аппаратным ускорением в Windows 10 и 11 вызывает серьёзную просадку производительности на видеокартах Nvidia (возможно и на других тоже, к сожалению, нет информации подтверждающей или отрицающей это).
Отключить ее можно следующим образом:
Откройте Параметры экрана. В Windows 11 в настройках нажмите «Графика» в разделе «Сопутствующие параметры», а в Windows 10 — «Настройки графики» ниже раздела «Несколько дисплеев». В Windows 11 дополнительно перейдите в раздел «Изменение стандартных параметров». Отключите, если у вас включена эта функция и перезагрузите ПК.
Настраиваем переменные в bat файле webui-user.bat
Если у вас видеокарта с 8 Gb видеопамяти и более:
Открываем webui-user.bat в блокноте или любом другом текстовом редакторе.
В строке
set COMMANDLINE_ARGS=
указываем следующие значения:
- Если у вас видеокарта поколения RTX:
set COMMANDLINE_ARGS= --opt-sdp-attention --opt-channelslast
opt-sdp-attention - включает метод перекрестного внимания SDP, встроенный в Torch 2.0 и 2.1. Он позволяет эффективнее работать с видеопамятью и увеличивает скорость генерации.
--opt-channelslast - Неоднозначный пункт. Активирует альтернативный режим работы с видеопамятью в torch, должно ускорить генерацию, но на слабых системах или системах с процессорами с низкой частотой или старой архитектурой - может вызывать замедление. Поэтому индивидуально.
- Если у вас видеокарта поколения GTX:
set COMMANDLINE_ARGS= --xformers
xformers - метод перекрестного внимания от Meta (Facebook). Также улучшает работу с видеопамятью и ускоряет генерацию, как и SDP. По заявлениям пользователей, лучше работает на слабых картах чем SDP.
Также, для всех карт Nvidia, стоит добавить следующие строки:
set CUDA_MODULE_LOADING=LAZY
Данная переменная активирует режим отложенной загрузки ненужных модулей CUDA. Направлено на экономию видеопамяти.
set NUMEXPR_MAX_THREADS=16
где 16 - кол-во потоков вашего процессора.
set PYTORCH_CUDA_ALLOC_CONF=garbage_collection_threshold:0.9,max_split_size_mb:512
Запрещает torch разбивать блоки, превышающие этот размер (в МБ). Это может помочь предотвратить фрагментацию и может позволить выполнять некоторые пограничные рабочие нагрузки без нехватки памяти.
Таким образом, ваш webui-user.bat должен иметь примерно следующее параметры:
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set CUDA_MODULE_LOADING=LAZY
set NUMEXPR_MAX_THREADS=16
set PYTORCH_CUDA_ALLOC_CONF=garbage_collection_threshold:0.9,max_split_size_mb:512
set COMMANDLINE_ARGS= --opt-sdp-attention
call webui.bat
Настройки в Automatic1111
Заходим в Settings, переходим в Sampler Parameters, и для ползунка Negative Guidance minimum sigma выставляем значение 3. Сохраняем.
Данный твик ускоряет генерацию за счет снижения значения cfg для негативного промта под конец генерации.
Устанавливаем Token Merging (ToMe)
ToMe позволяет ускорить генерацию с небольшим падением детализации изображения, за счет объединения некоторых избыточных токенов.
Заходим в Extentions, переходим в Install from url и вставляем следующую ссылку:
https://github.com/SLAPaper/a1111-sd-webui-tome
и нажимаем Install. После установки появится сообщение, что установка закончена. Перезапускаем автоматик. По умолчанию, ToMe будет активирован.
Примечание: Чем выше коэффициент, тем сильнее будут отличаться генерации на одном и том же сиде. Я рекомендую установить значение 0.4 как золотую середину, но вы можете выбрать в диапазоне 0.3-0.5. При значениях 0.6-0.9 вы получите бОльшую прибавку к скорости, но сильно начнете терять в детализации и сид станет вообще не воспроизводимым.
Подробнее об установке и работе ToMe я рассказывал в следующем видео:
(Опционально) Отключаем Live Preview
Предпросмотр замедляет основной процесс генерации, и если вы хотите выжать еще немного скорости - отключите его. Зайдите в Settings, перейдите в Live previews и уберите галки на Show live previews of the created image и Show previews of all images generated in a batch as a grid. Примените настройки.
(Опционально) Используем модели, основанные на SD 2.1
По моим личным наблюдениям и тестам на RTX 3060 Ti и RTX 4090, а также по наблюдениям админов других тематических телеграм каналов, после майского обновления Automatic1111 генерация на моделях, основанных на версии SD 2.1 идет быстрее чем на моделях 1.5 при полностью одинаковых параметрах.
При тестировании на 3060 ti, включив все улучшения и оптимизации, я смог дополнительно получить ускорение на 20%.
(Опционально) Используйте Batch size 2 или 4.
Главное не перепутать с Batch count, которое отвечает за последовательную генерацию изображений друг за другом. Batch size же запустит генерацию изображений паралельно в многопотоке. Особенно актуально это для мощных видеокарт, т.к. однопотоковая генерация на данный момент не может полностью раскрыть их производительность.
На моей RTX 4090 при генерации с batch size 1, скорость составляет максимум 30 it/s. При выставлении 4 изображений, скорость составляет 12 it/t, что в пересчете на одно будет равняться уже 48 it/s.
Обновляем CUDNN
CUDNN - библиотеки от Nvidia для работы с нейронными сетями. Свежие версии этих библиотек, как правило, привносят улучшение производительности, особенно для карт поколения RTX30xx и выше.
Идем сюда: https://developer.nvidia.com/rdp/cudnn-download (или можете скачать с моего Яндекс.Диска: https://disk.yandex.ru/d/sFgV-xlyLXPnMA) выбираем самую актуальную версию для Cuda 11.x и скачиваем архив Local Installer for Windows (Zip)
Открываем архив, переходим в папку bin внутри архива.
Теперь открываем папку, где лежат файлы нашего Automatic1111, переходим в venv\Lib\site-packages\torch\lib

И теперь из нашего архива, где мы открыли папку bin, перекидываем все файлы с заменой в открытую нами папку lib.
Теперь мы обновили библиотеки Cudnn на самую актуальную версию.
Для владельцев видеокарт на 4 и 6 гигабайт видеопамяти
Если вы выполнили всё, что указано в этой части статьи, переходите во вторую часть по ссылке:
https://telegra.ph/Optimiziruem-potreblenie-videopamyati-Automatic1111-05-03
На данный момент это все основные способы ускорения и оптимизации работы Automatic1111. Есть еще дополнительные способы, например, использовать linux вместо windows, или использовать wsl2, но они слишком сложные для обычного пользователя Stable Diffusion. При появлении новых статья будет дополняться.
Neurogen News - Новости и релизы из мира нейросетей
Дополнение
Вопрос: Я включил оптимизации и теперь я не могу воспроизвести старые генерации! Все сломалось?
Ответ: Нет, это нормальное поведение. Каждый способ вмешивается в процесс генерации и старые сиды становятся не воспроизводимыми. Если вам надо их воспроизвести - отключите все изменения.
Вопрос: У меня вместо генераций черные квадраты. Как быть?
Судя по всему, у вашей видеокарты проблемы с генерацией в режиме fp16. Добавьте к аргументам для запуска:
--upcast-sampling
upcast-sampling - выборка по восходящему потоку. Не имеет эффекта при использовании --no-half. Обычно дает результаты, аналогичные --no-half, с лучшей эффективностью при использовании меньшего объема памяти. Обычно дает небольшое ускорение.
Если этот аргумент не помог то замените его на:
--precision full --no-half
Это увеличит потребление видеопамяти, но исправит проблему черных квадратов.