Open Source масштабирумая отказоустойчивая база данных или где бесплатно хранить данные в Yandex.Cloud
Azamat Komaev
О чем пойдет речь
Речь в этой статье пойдет об YDB, исходники которой в прошлом году Яндекс выложил в GitHub. YDB используется в сервисах Яндекса, в том числе в Yandex Cloud для хранения различных данных. Там же, в облаке, можно развернуть свой кластер YDB. Документные таблицы Managed Service for YDB совместимы с таблицами Amazon DynamoDB.
Про YDB я услышал впервые месяц назад, когда переводил облачную инфраструктуру в Terraform. Я старался сделать это по всем "бест практикам", поэтому код разделен на модули (один сервис - один модуль), а также используется Yandex Object Storage (S3 совместимое хранилище от Yandex Cloud) для удаленного хранения состояния. Единственная практика, которую я пока посчитал излишней, использование YDB для "лока" состояния Terraform, чтобы в один и тот же момент несколько человек не смогли внести изменения в файл с состоянием. Излишним, так как я один слежу за инфраструктурой и никто больше не имеет доступ к Terraform и облачной инфраструктуре.
Free tier
Managed service for YDB выделяется тем, что у него есть жирный Free tier (лимит бесплатного пользования), а именно каждый месяц не тарифицируются:
- 1 000 000 операции (в единицах Request Unit);
- 1 ГБ/месяц хранения данных.
Про Request Unit (далее RU) можно почитать тут. Если коротко, то это дохера для личного пользования!
Создание кластера
Развернем кластер YDB в Yandex Cloud и подробно рассмотрим возможные настройки
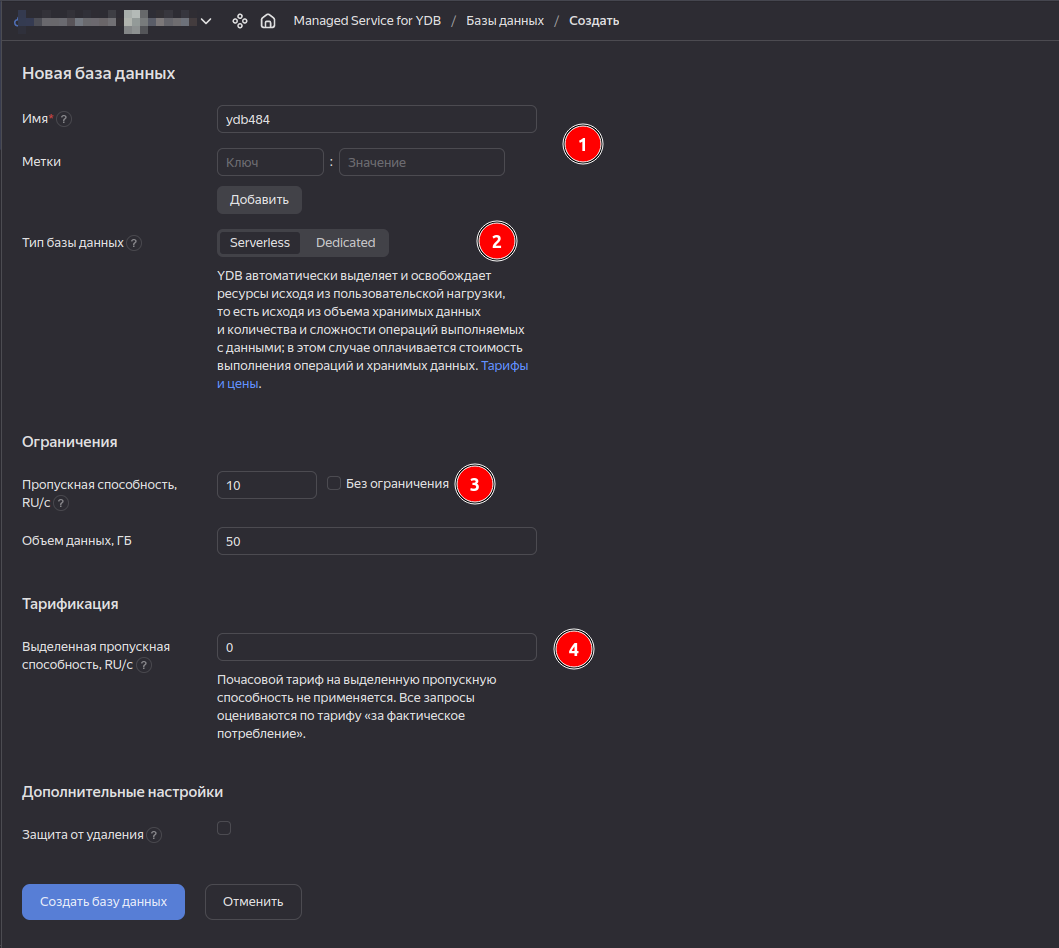
1) Назначим имя и по желанию метки. С помощью меток мы сможем отслеживать расходы на кластер в Биллинге, если кластеров будет несколько.
2) У Managed YDB есть два типа работы: Serverless и Dedicated. Serverless будет выделять и освобождать ресурсы исходя из нагрузки на БД. В случае с Dedicated, назначается определенный тип хоста (vCPU + Memory). Нас интересует Serverless, так как мы не хотим платить за хранение данных!
3) Пропускная способность позволяет установить лимит RU (Request Unit) в секунду, чтобы избежать переоплаты за очень большую нагрузку.
Доступ к БД
Для начала необходимо установить утилиту ydb, позволяющую выполнять команды для YDB.
curl -sSL https://storage.yandexcloud.net/yandexcloud-ydb/install.sh | bash
Далее необходимо подключиться к нашей БД. Для этого нужно выбрать один из режимов аутентификации. Я буду использовать аутентификацию с Service Account Key и подключаться к YDB от "лица" сервисного аккаунта. Для этого создадим сервисный аккаунт и назначим роль ydb.editor на весь каталог (можно на конкретный кластер):
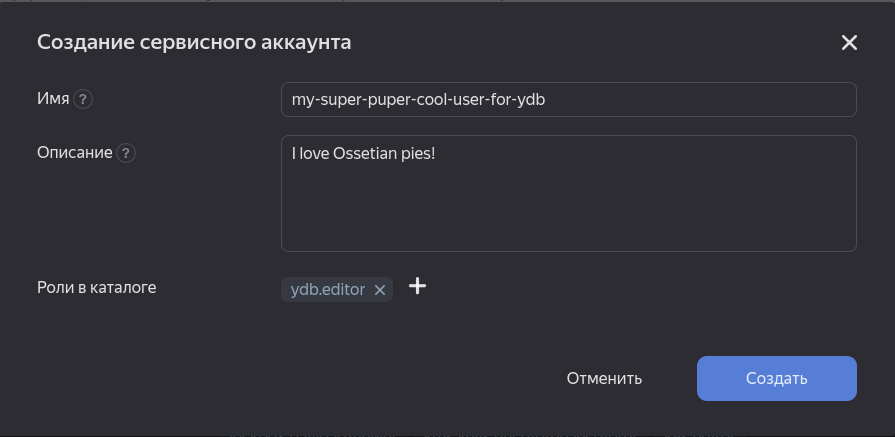
Далее создадим и скачаем service account key:
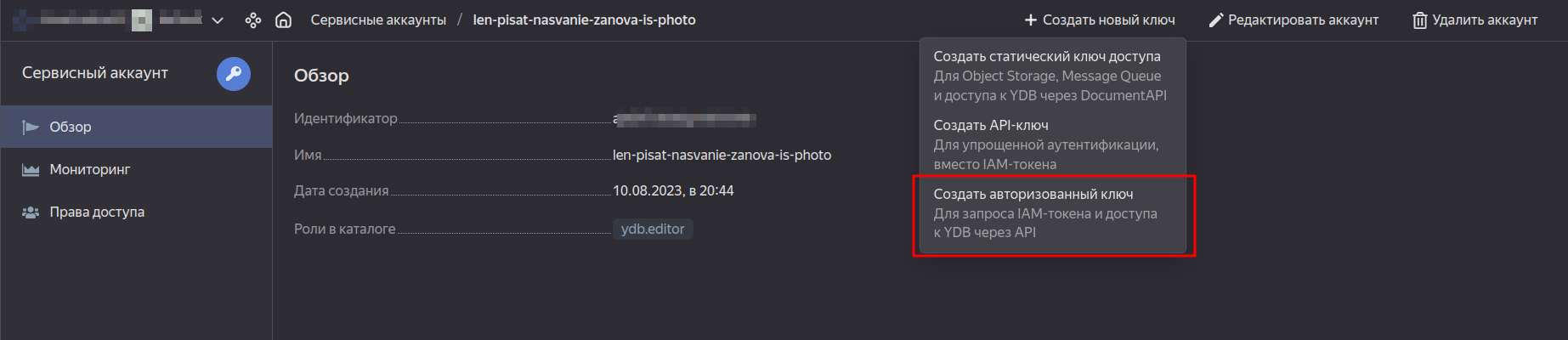
Теперь создадим профиль в утилите ydb. Профили в ydb идентичны профилям в уc. Они используются для того, чтобы каждый раз не вводить параметры для подключения к конкретному кластеру и иметь возможность для каждого подключения свои параметры.
Команда для создания профиля с подключением к кластеру при помощи Service Account Key:
ydb config profile create my_cool_profile \ -e <ydb_endpoint> \ -d <ydb_path_to_database> \ --sa-key-file <path_to_service_account_key_file>
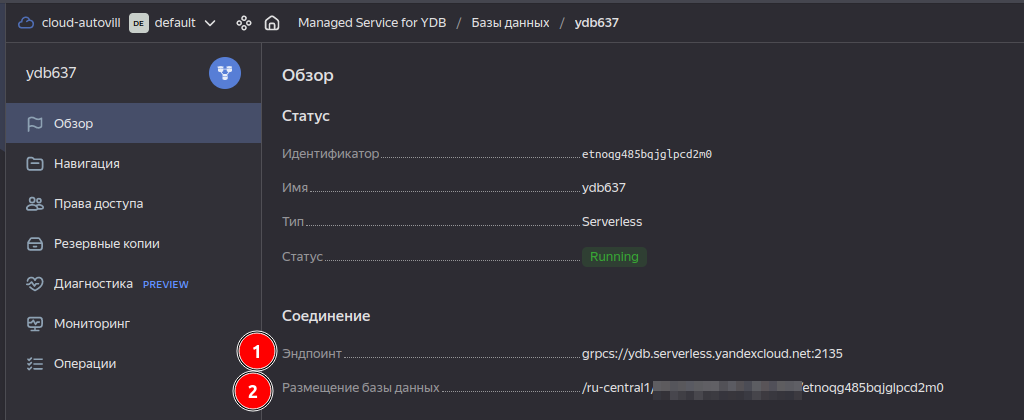
Чтобы получить ydb_endpoint и ydb_path_to_database зайдите в ваш кластер в Yandex Cloud и скопируйте эти значения (1 - ydb_endpoint, 2 - ydb_path_to_database):
Теперь попробуем получить список всех баз данных:
ydb -p <profile_name> scheme ls -l

Все работает!
Как выполнять SQL (YQL) команды
Не будем заострять внимание на типы данных, синтаксис YQL и функции из коробки: все это можно найти в документации.
Создадим обычную таблицу с несколькими полями. Для этого изначально необходимо создать файл с расширением yql. Вставим туда следующее содержимое:
CREATE TABLE posts ( id Uint64 NOT NULL, title Utf8, description Utf8, author_name Utf8, PRIMARY KEY (id) );
Сохраним в файл с названием tables.yql. Далее выполним команды из данного файла в YDB:
ydb -p <profile_name> yql -f ./tables.yql
Параметр -f позволяет указать из какого файла брать команды.
Теперь создадим файл data.yql и заполним таблицу posts данными:
UPSERT INTO posts (id, title, description, author_name) VALUES ( 1, "My first post", "Hello, it is my first post! How are you doing? Do you like SLOT or Skillet?? Ossetian pies maybe??", "Azamat Komaev" ), ( 2, "It is second one!", "I am lazy to write smth here. Just imagine and put your text here :))", "Doctor Who" );
Выполним команды из data.yql:
ydb -p <profile_name> yql -f ./data.yql
Теперь попробуем получить все записи таблицы posts. Черт, опять создавать файл с расширением yql (на самом деле расширение может быть любым), писать команду для получения данных и выполнять ее? Не обязательно: можно выполнить запрос сразу, без файла:
ydb -p <profile_name> table query execute -q "SELECT * FROM posts;"

Данные были добавлены.
НАГРУЗКА, НУЖНО БОЛЬШЕ НАГРУЗКИ!!11!11
Заголовок говорит сам за себя - попробуем сымитировать нарастающую нагрузку на YDB и проследим что будет происходить с базой данных. Для имитации нагрузки напишем простой скрипт на Python, создающий кучу потоков с добавлением данных. Запись данных обходится в два раза дороже по RU, чем чтение. Для мониторинга кластера будем использовать средства Yandex Cloud. Зайдем во вкладку Monitoring и обратим внимание на самый первый график, показывающий кол-во Request Unit-ов. Напомню, что бесплатно можно использовать до 1 миллиона RU и хранить до 1Гб данных (попробуем не перегнуть).
Начнем! Для начала установим YDB python SDK:
pip install ydb
Для начала напишем скрипт для добавления записи. Прежде всего, добавьте следующие переменные окружения:
export YDB_ENDPOINT=<ydb_endpoint>
export YDB_DATABASE=<ydb_database>
export SA_KEY_FILE=<path_to_sa_key>
main.py:
---
import os
import ydb
UPSERT_DATA_QUERY = """
UPSERT INTO posts (id, title, description, author_name) VALUES (
{id}, "{title}", "{description}", "{author_name}"
);
"""
def insert_data(pool: ydb.SessionPool, row: dict[str, str]):
def callee(session):
session.transaction().execute(
UPSERT_DATA_QUERY.format(
id = row.get("id"),
title = row.get("title"),
description = row.get("description"),
author_name = row.get("author_name")
),
commit_tx=True
)
return pool.retry_operation_sync(callee)
def main():
example_row = {
"id": "3",
"title": "Hello it is from python",
"description": "Fefefefefefefef",
"author_name": "Azamat Komaev"
}
with ydb.Driver(endpoint=os.getenv("YDB_ENDPOINT"),
database=os.getenv("YDB_DATABASE"),
credentials=ydb.iam.ServiceAccountCredentials.from_file(
os.getenv("SA_KEY_FILE"),
),
) as driver:
driver.wait(timeout=5, fail_fast=True)
with ydb.SessionPool(driver) as pool:
insert_data(pool, example_row)
if __name__ == "__main__":
main()
Запустим скрипт и проверим, что данные добавились:

Фунция для добавления данных работает!
Зайдем во вкладку Monitonig и изучим первый график, показывающий кол-во RU:
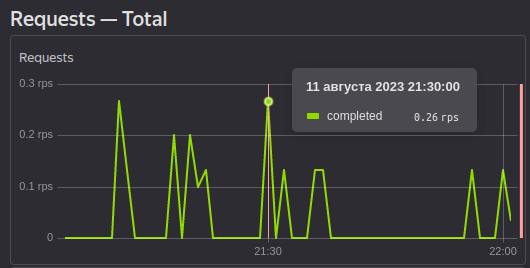
Один запрос на вставку стоит 15 RU (зависит от размера данных), значит один запрос на получение будет стоить в два раза меньше (8 RU):
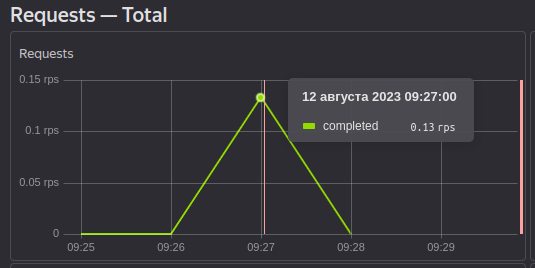
Но мы пришли сюда не для того, чтобы делать по одному запросу и считать копейки!
Установим библиотеку для генерации фейковых данных:
pip install Faker
Внесем 500 записей через цикл for:
...
import time
from faker import Fake
fake = Fake
...
with ydb.SessionPool(driver) as pool:
time_before = time.time()
for i in range(4, 504):
fake_description = fake.text()
fake_title = fake_description.split(".")[0]
insert_data(pool, {
"id": i,
"title": fake_title,
"description": fake_description,
"author_name": fake.name()
})
time_after = time.time()
print(f"Execution time: {time_after - time_before}s")
...
Вывод в консоль:
Execution time: 61.02964115142822s
Кол-во потраченных RU:
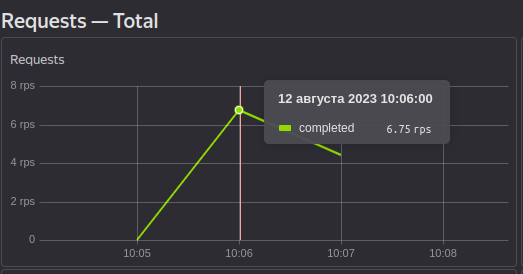
Уже нагрузка больше (за две минуты 600 RU), но нужно еще больше!
Сделаем так, чтобы запросы выполнялись параллельно: используем потоки... Думал я, приступил к написанию кода и столкнулся с проблемой, что теряется коннект. Попробывав различные способы, в том числе использовать asyncio, решил сделать дедовским способом: несколько раз запустить скрипт. Для этого вынесем диапозон из for цикла в параметры запуска:
...
import sys
...
FROM_ID = int(sys.argv[1])
TO_ID = int(sys.argv[2])
...
for i in range(FROM_ID, TO_ID):
fake_description = fake.text()
fake_title = fake_description.split(".")[0]
insert_data(pool, {
"id": i,
"title": fake_title,
"description": fake_description,
"author_name": fake.name()
})
...
Создадим start.sh скрипт с данным содержимым:
python3 main.py 1 500 & \ python3 main.py 500 1000 & \ python3 main.py 1000 1500 & \ python3 main.py 1500 2000
Далее запустим скрипт с командой time, чтобы узнать кол-во затраченного времени
time ./start.sh ./start.sh 17,57s user 1,41s system 15% cpu 1:04,19 total
Добавилось 1587 строк. При добавлении 500 данных время составило 61 секунду. В случае с добавлением через & в bash время составило 64 секунд, что весьма не плохо. На моем процессоре 2 ядра 4 потока.
Начнем анализировать. Сначала обратим внимание на RU/s:
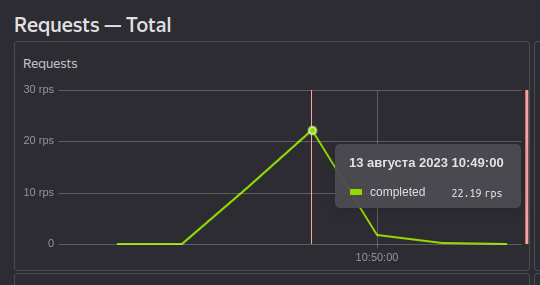
Суммарно за время добавления данных за 2 минуты в секунду добавлялось 35 RU, всего же было использовано 4200 Ru (пысы: насколько я понял, RU/s нужно умножать на кол-во секунд в минуту, чтобы узнать фактическое использование RU). Но.....Как же лимит по пропускной способности в 10 RU/s, если даже в системе мониторинга по графику можно увидеть 22RU/s? Вопрос интересный и поэтому я написал в поддержку и жду ответа. Примеры данных в БД:
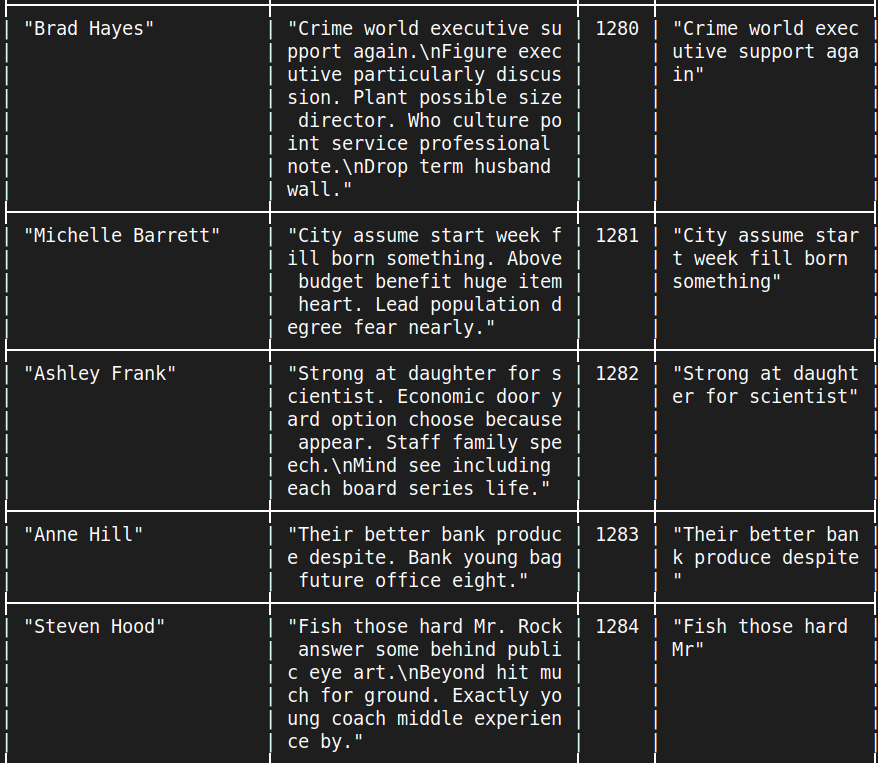
А теперь вспомните, что таких строк у вас 1587, при этом по Free tier у вас 1.000.000 бесплатных RU, а мы израсходовали всего лишь 4200 RU.
При получении данных RU не тратится. Скорее всего это связано с тем, что YDB получает все данные после вставки и в дальнейшем кэширует их, чтобы не тратить RU:
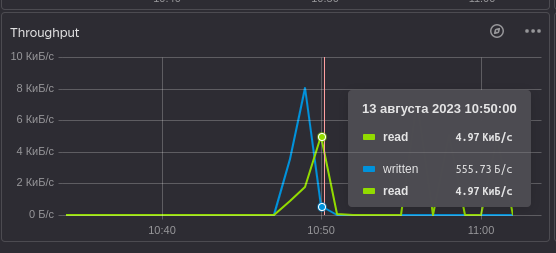
Изначально данные добавлялись (синия линия), после вставки данные сразу же прочитались.
Но RU зависит не только от размера данных, а также от использования CPU, которое, к сожалению, я не знаю как отследить.
Итог
YDB можно или даже нужно использовать в своих проектах. Помимо этого, он также подойдет для больших проектов и позволит экономить на хранении данных. SDK позволят взаимодействовать с YDB почти из каждого популярного ЯП, если же вы пишите на языке, куда разработчики не завезли SDK, вы можете использовать API.