Ох уж этот ROC-анализ
@statshotsROC-анализ – один из переоцененных методов прогнозной аналитики, представляет собой график (ROC-кривую), который иллюстрирует диагностическую способность системы бинарного классификатора при изменении его порогового значения.
AUC (площадь под кривой) – гипотетическая (вероятностная) точность модели. Способность модели верно классифицировать объекты на 2 класса (1/0) или вероятность того, что объект, классифицируемый моделью как класс 1, на самом деле принадлежит классу 1, а как класс 0 – классу 0. AUC – метрика, инвариантная от порога (не зависит от значения cut-off point).
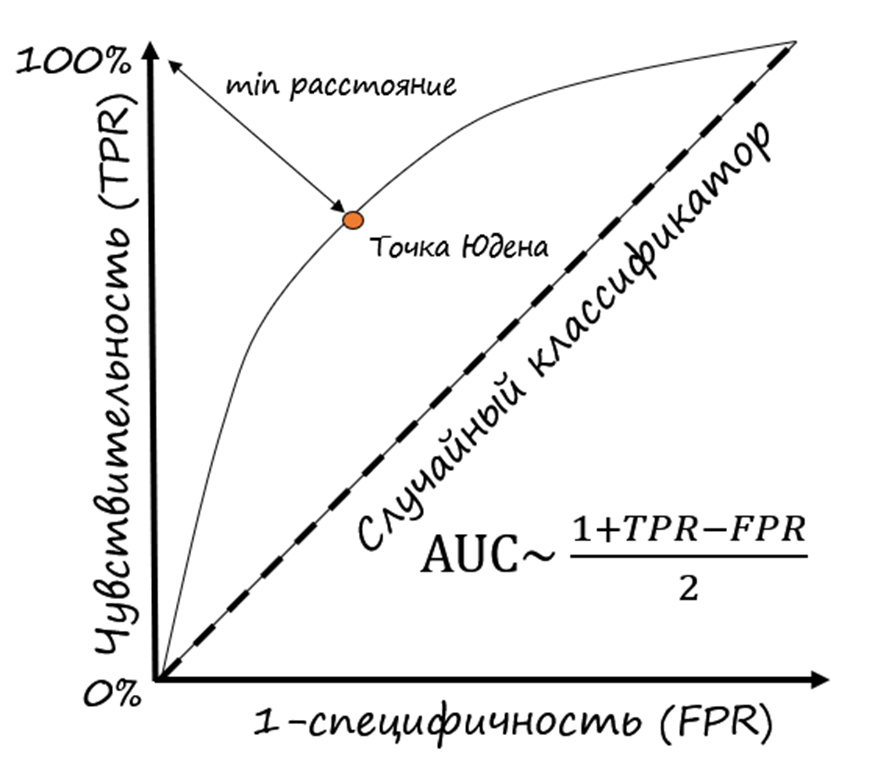
ROC-кривая строится через оси координат, представляющих собой частоту правильно предсказанного класса 1 (True Positive Rate, TPR) и частоту неправильно предсказанного класса 1 (False Positive Rate, FPR) при разных значениях оцениваемой количественной переменной. В контексте разработки прогностических моделей данной переменной является апостериорная вероятность, предсказанная моделью.
Интерпретация результатов ROC-анализа на примерах:
1. Мы построили регрессионную модель с AUC = 0.87 на валидационной выборке.
Вероятность гипотезы (likelihood или правдоподобие), что модель будет точнее предсказывать результат, чем подбрасывание честной монетки составляет 0.87. Вероятностная точность модели на основе подбрасывания монетки = 0.5, что равноценно шансам 0.5/(1–0.5) = 1. Вероятностная точность нашей модели = 0.87, что на 37% выше и это равноценно шансам верного прогноза 0.87/(1-0.87) = 6.7.
Другими словами, если до применения модели, вероятность заболевания у пациента расценивалась как 50% или шансы 1:1, то после получения результатов о наличии заболевания при применении модели шансы увеличились до 6.7, а вероятность заболевания составила = 87%. Вероятность гипотезы, что пациент болен увеличилась на 87-50=37% по сравнению с вероятностью гипотезы, что он болен с вероятностью 50%.
Подвох в том, что у нас нет критериев, по которым мы будем утверждать, что результат модели о наличии заболевания положительный или отрицательный. В этом случае предлагают искать пороги принятия решения, о чем чуть ниже.
2. У нас две модели: Модель 1 – AUC = 0.82, Модель 2 – AUC = 0.87. При положительном результате (критериев положительности результата у нас все еще нет) модели №1 шансы заболевания = 0.82/(1–0.82) = 4.5. У модели №2–6.7. Таким образом, если обе модели дали положительный результат, то путем перемножения отношения правдоподобий 4.5:1 и 6.7:1 мы получаем шансы 30:1, что у пациента есть заболевание. Отношение шансов между моделями = 6.7/4.5 = 1.49. Шансы диагностировать заболевание по модели №2 в ~1.5 раза (или на 20%) выше (x+1.5x=1, x = 0.4).
3. Нам хочется большей определенности и четкие критерии принятия решений. Мы вводим понятие порога и переходим на темную сторону. Дело в том, что порог – нестабильная величина, которая высчитывается на выборочной совокупности. Простое моделирование показывает, что величина порога варьирует. Интервал неопределенности (доверия) тем больше, чем меньше изначальная выборка. Оптимальный порог выбирается на основании каких-либо метрик, например, максимальной чувствительности и специфичности (точка Юдена). Но на разных выборках порог будет разным! Кроме того, один и тот же порог на разных выборках будет давать разные результаты точности, чувствительности, специфичности и других метрик. Таким образом, порог – отражение выборочной совокупности, а при описании генеральной совокупности он превращается в распределение, что сводит на нет его первоначальное предназначение как критерия категоризации пациентов на 2 класса по одному значению.
Так как любой порог имеет свои показатели TPR и FPR, отношение правдоподобия (LR) также будет меняться. Например, при некоем пороге j, чувствительность модели (на валидационной выборке) = 0.9, специфичность = 0.85. Следует повторить, что при взятии другой случайной выборки и при этом же пороге j метрики изменятся.
Модель будет прогнозировать заболевание у пациента, имеющего данное заболевание, в 0.9/(1–0.85) = 6 раз чаще. Это и есть LR+ для положительного результата модели. Шансы, что пациент болен, при значении вероятности, посчитанной моделью, выше порога j составят 6 к 1 или ~86%. Хотя показатель AUC не зависит от порога, его можно посчитать приблизительно. AUC такой модели = (1+0.9-(1–0.85))/2 = 0.875.
4. Представим, что частота встречаемости заболевания в выборке (априорная вероятность) = 1/3, тогда шансы = 0.5. Если AUC нашей модели = 0.87 (из примера 1), то по отношению к исходным шансам до применения модели шансы заболевания после получения положительных результатов о его наличии составили 0.5*6.7=3.3 (а не 6.7 как было в примере 1). Диагностическая ценность моделей с одним и тем же значением AUC будет отличаться в зависимости от априорной вероятности прогнозируемого исхода (заболевания).
5. Модель из примера 3: при пороге j, чувствительность модели (на валидационной выборке) = 0.9, специфичность = 0.85, но априорная вероятность болезни = 0.3. Тогда шансы, что пациент болен, при значении вероятности, посчитанной моделью выше порога j составят 0.5 * 6 = 3 или ~75% (апостериорная вероятность).
Ее можно также посчитать по формуле Байеса:
TPR*P(x)/(TPR*P(x)+FPR*(1-P(x)))= 0.9*0.3/(0.9*0.3+0.15*0.7)~75%
Так почему ROC-анализ переоценен? Во-первых он дает нам значение AUC, которое является лишь гипотетической (а не истинной) точностью прогноза при неизвестных условиях принятия решения о положительном результате. А у AUC к тому же есть еще и доверительный интервал. Другими словами данное значение мы можем лишь "принять к сведению", но не "принять к действию". Во-вторых, попытка исправить это с помощью порога (cut-off point) обречена на неудачу, по причине нестабильности значения самого порога, отражающего оптимальное решение только на вашей выборочной совокупности и превращающегося в распределение (набор из множества значений) при экстраполяции на генеральную совокупность (популяцию). Единственная польза от ROC-анализа – сравнение нескольких моделей между собой в рамках сравнения вероятностей гипотез (правдоподобия) об их точности.
Выводы:
1. Не делайте ROC-анализ, если у вас только одна модель и ее не с чем сравнивать.
2. Просто используйте апостериорные вероятности, рассчитанные моделью, как есть, в качестве истинных апостериорных вероятностей прогнозируемого исхода.
3. Чтобы быть уверенным, что вероятности модели соответствует истиным вероятностям прогнозируемого исхода, стройте калибровочную кривую на валидационной выборке.