Очистка raw data в SQL
March 02, 2022В этом руководстве вы узнаете, как очистить raw data (необработанные данные) в SQL. Такой навык является обязательным для любого специалиста по анализу данных.
Реальные данные почти всегда беспорядочны. Если вы занимаетесь исследованием данных, анализом данных или разработкой, если вам нужно обнаружить какие-либо факты на основе данных, крайне важно убедиться в том, что данные достаточно чистые.
В этом руководстве мы рассмотрим набор фиктивных данных. Но вы также можете применить эти техники и к реальным данным (табличной формы).
Содержание руководства следующее:
- Различные типы данных и их необработанные значения
- Проблемы, которые могут возникнуть из-за необработанных чисел
- Очистка числовых данных
- Необработанные строки
- Очистка строковых значений
- Необработанные даты и их очистка
- Дубликаты и их удаление
Многое нужно рассказать. Давайте начнем!
Различные типы данных, их необработанные значения и методы исправления
В табличных данных наиболее распространенными типами данных являются строки, числа и дата-время. Вы можете столкнуться с необработанными значениями во всех этих типах. Давайте возьмем каждый из этих типов и рассмотрим несколько примеров. Начнем с чисел.
Числа
Числа могут быть представлены в различных неупорядоченных формах. Здесь вы познакомитесь с наиболее распространенными из них:
- Несоответствие типа: Предположим, что в наборе данных, с которым вы работаете, есть столбец
age. Вы видите, что значения, которые присутствуют в этом столбце, имеют типfloat- к примеру значения равны 23.0, 45.0, 34.0 и так далее. В этом случае вам не нужно, чтобы столбецageимел типfloat. Не так ли? - Нулевые значения: Хотя это характерно для всех вышеупомянутых типов данных, здесь нулевые значения означают лишь то, что значения недоступны/пусты. Однако нулевые значения могут отображаться и в другой форме. Возьмем, к примеру, набор данных по Диабету Индейцев племени Пима. Набор данных содержит нулевые значения для таких столбцов, как
Plasma glucose concentration,Diastolic blood pressure, что на практике невозможно. Если вы проведете статистический анализ набора данных без обработки этих недействительных записей, ваш анализ будет неточным.
Давайте теперь изучим проблемы, которые могут возникнуть в таких ситуациях, и как с ними справиться.
Проблемы с необработанными числами и способы их решения
Давайте теперь рассмотрим наиболее распространенные проблемы, с которыми вы можете столкнуться, если не очистите начальные данные.
1. Агрегирование данных
Предположим, у вас есть записи NULL для числового столбца, и вы вычисляете статистику (например, среднее, максимальное, минимальное значения) по этому столбцу. В этом случае результаты будут неточными.
Снова рассмотрим набор данных по диабету индейцев племени пима с пустыми значениями. Если бы вы рассчитали статистику по столбцам, как упоминалось ранее, получили бы вы правильные результаты? Не будут ли результаты ошибочными? Как же решить эту проблему? Есть несколько способов:
- Удаление записей, содержащие отсутствующие значения/NULL (не рекомендуется)
- Подстановка в записи с NULL числового значения (обычно среднего или медианы соответствующего столбца)
Давайте теперь разберем эти проблемы и второй вариант борьбы с NULL.
Рассмотрим следующую PostgreSQL таблицу entries:
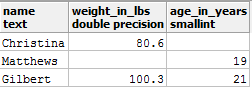
В приведенной выше таблице вы можете увидеть две записи с NULL. Предположим, вы хотите получить значение среднего веса из этой таблицы и выполнили следующий запрос:
SELECT AVG(weight_in_lbs) AS average_weight_in_lbs FROM entries;
На выходе вы получили 90.45. Это правильный результат?
Итак, что можно сделать? Давайте заполним нулевую запись этим средним значением с помощью функции COALESCE(). Помните, что COALESCE() не изменяет значения в исходной таблице, а просто возвращает временное представление таблицы с измененными значениями:
SELECT *, COALESCE(weight_in_lbs, 90.45) AS corrected_weights FROM entries;
Вы должны получить следующий результат:
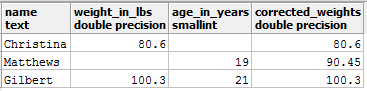
Теперь вы можете снова применить AVG() или другие функции:
SELECT AVG (corrected_weights) FROM ( SELECT *, COALESCE(weight_in_lbs, 90.45) AS corrected_weights FROM entries) AS subquery;
Это уже будет более точный результат, чем предыдущий. Теперь рассмотрим другую проблему, которая может возникнуть при несовпадении типов данных в столбцах.
2. JOINы
Предположим, что вы работаете с таблицами student_metadata и department_details:

Вы можете заметить, что в таблице student_mtadata, dept_id имеет тип integer, а в таблице department_details этот столбец текстовый. Теперь, предположим, вы хотите объединить эти две таблицы и создать отчет, который будет содержать следующие столбцы:
- id
- name
- dept_name
Для этого можно выполнить следующий запрос:
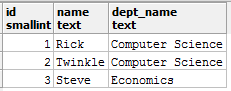
SELECT id, name, dept_name FROM student_metadata s JOIN department_details d ON s.dept_id = d.dept_id;
Но тогда вы получите ошибку:
ERROR: operator does not exist: smallint = text
Так происходит потому, что типы данных не совпадают при объединении двух таблиц. Здесь вы можете преобразовать (CAST) столбец dept_id в таблице department_details в целое число при соединении таблиц. Вот как это сделать:
SELECT id, name, dept_name FROM student_metadata s JOIN department_details d ON s.dept_id = CAST(d.dept_id AS smallint);
И вы получаете желаемый отчет:
Давайте теперь обсудим, как могут выглядеть необработанные строки, проблемы с ними и способы борьбы.
Строки
Строковые значения также встречаются очень часто. Начнем этот раздел с рассмотрения значений столбца dept_name (обозначающего названия факультетов), взятых из таблицы student_details:
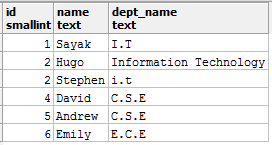
Строковые значения как на картинке выше могут вызвать множество неожиданных проблем. И I.T, и Information Technology, и i.t все означают один и тот же факультет, т.е. информационные технологии, и предположим, что спецификация требует, чтобы значения были только как I.T. Теперь, скажем, вы хотите подсчитать количество студентов, принадлежащих к факультету I.T., и выполняете такой запрос:
SELECT dept_name, COUNT (dept_name) AS student_count FROM student_details GROUP BY dept_name;
И вы получите:
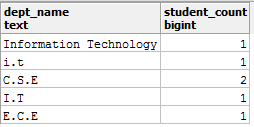
Разве это достоверный отчет? - Нет! Итак, как вы можете решить эту проблему?
Давайте сначала подробно обозначим проблему:
- У вас есть значение
Information Technology, которое следует преобразовать вI.Tи - Еще у вас есть значение
i.t, которое также должно быть преобразовано вI.T.
В первом случае вы можете заменить (с помощью REPLACE)значение Information Technology на I.T, а во втором - преобразовать символ в верхний (UPPER) регистр. Это можно сделать в одном запросе, хотя рекомендуется решать подобные проблемы пошагово. Вот запрос для решения этой проблемы:
SELECT UPPER(REPLACE(dept_name, 'Information Technology', 'I.T')) AS dept_cleaned, COUNT(dept_name) AS student_count FROM student_details GROUP BY dept_cleaned;
И результат:
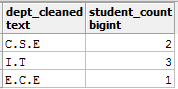
Теперь давайте рассмотрим несколько примеров, когда даты необработаны и что можно сделать для их очистки.
Даты
Предположим, что вы работаете с таблицей с именем employees, которая содержит столбец birthdate, но не в соответствующем типе даты. Теперь вы хотите выполнять запросы с использованием date функций, таких как DATE_PART(). Вы не сможете этого сделать, пока не приведете (CAST) столбец birthdate к типу date. Давайте рассмотрим это на примере.
Будем считать, что значения birthdate должны быть в формате YYYY-MM-DD.
Вот как выглядит таблица employees:
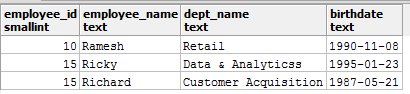
Теперь вы выполняете следующий запрос, чтобы извлечь месяцы из birthdate:
SELECT DATE_PART('month', birthdate) FROM employees;
И вы мгновенно получите эту ошибку:
ERROR: function date_part(unknown, text) does not exist
Вместе с ошибкой вы также получите очень хорошую подсказку:
HINT: No function matches the given name and argument types. You might need to add explicit type casts.
Давайте последуем подсказке и приведем (CAST) birthdate к соответствующему типу date, а затем применим DATE_PART():
SELECT DATE_PART('month', CAST(birthdate AS date)) AS birthday_months FROM employees;
Вы должны получить следующий результат:

Теперь перейдем к заключительному разделу этого руководства, в котором вы изучите последствия дублирования данных и способы борьбы с ними.
Дублирование данных: Причины, следствия и решения
В этом разделе вы изучите некоторые из наиболее распространенных причин, которые приводят к дублированию данных. Вы также увидите их последствия и некоторые способы их предотвращения. Рассмотрим следующие две таблицы band_details:
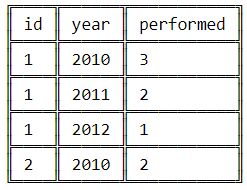
и some_festival_record:
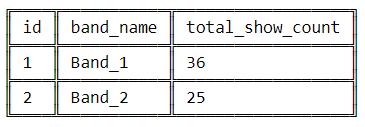
Таблица band_details содержит информацию о музыкальных группах, в ней указаны их идентификаторы, год выступлений и общее количество их выступлений. С другой стороны, таблица some_festival_record представляет гипотетический музыкальный фестиваль и содержит записи о выступавших на нем группах.
Теперь предположим, что вы хотите создать отчет, который должен содержать названия групп, количество их выступлений и общее число раз, когда они выступали на фестивале. Здесь необходим INNER JOIN. Вы выполняете следующий запрос:
SELECT band_name, SUM(total_show_count) AS total_shows, SUM(performed) AS total_times_performed FROM band_details b JOIN some_festival_record s ON b.id = s.band_id GROUP BY band_name;
И запрос возвращает:
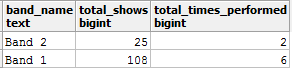
Не кажется ли вам, что значения total_shows здесь ошибочны? Ведь из таблицы band_details вы знаете, что Band_1 дала в общей сложности 36 концертов. Тогда что здесь пошло не так? Дубликаты!
При объединении двух таблиц вы ошибочно агрегировали столбец total_show_count, что привело к дублированию данных в промежуточных результатах объединения. Если вы удалите агрегацию и соответствующим образом измените запрос, вы получите желаемые результаты:
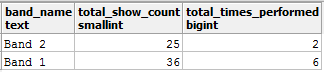
SELECT band_name, total_show_count, SUM(performed) AS total_times_performed FROM band_details b JOIN some_festival_record s ON b.id = s.band_id GROUP BY band_name, total_show_count;
Теперь вы получите ожидаемые результаты:
Существует другой способ предотвратить дублирование данных, а именно добавить еще одно поле в оператор JOIN , чтобы таблицы объединялись на более строгих условиях.
Заключение
Спасибо, что прочитали это руководство. Вы ознакомились с одним из самых важных этапов в процессе анализа данных - очисткой данных. А также увидели различные формы необработанных данных.
Оригинал статьи: https://www.datacamp.com/community/tutorials/cleaning-data-sql