Обзор статьи Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
Tatiana GaintsevaЭтот текст — обзор очень классной статьи, авторы которой представили механизм редактирования отдельных частей изображения, сгенерированного диффузией.
Ссылка на статью: https://prompt-to-prompt.github.io/ptp_files/Prompt-to-Prompt_preprint.pdf
Код на GitHub: https://github.com/google/prompt-to-prompt

О чем статья
Мы все видим, как классно диффузии (DALL-E 2, Imagen, Stable Diffusion, etc) генерируют картинки. Но управлять семантикой этих картинок мы не очень умеем: малейшее изменение во входном тексте может поменять картинку целиком. Контроль семантики изображения (форм, цветов, частей картинки) — важная и пока еще нерешенная задача. И до сих пор решить ее пытались в основном с помощью моздания сегментационных масок, которые подавались на вход диффузии вместе с текстом. Пример такого подхода — модель Make-A-Scene, о ней я писала тут.
Авторы из Стенфорда и университета Тель-Авива пошли глубже: они исследовали, где в модели диффузии кроется связь между словами текста и пикселями сгенерированной картинки, и придумали, как сохранять семантику картинки при изменении слов входного текста.
Примеры работы модели — на картинке выше. При изменении/добавлении отдельных слов на картинке меняется лишь то, что соответствует этим словам. Остальные объекты остаются нетронутыми.
Далее мы обсудим, как такая модель работает
Как это работает
Вспомним идею работы text-to-image диффузии на примере Imagen. Модель — это нейросеть по типу U-Net, которая на каждом шаге диффузии получает на вход текущую сгенерированную картинку и эмбеддинг входящего текста, а на выходе выдает новую сгенерированную картинку с меньшим шумом. Внутри в устройстве модели к эмбеддингам входящей картинки и текста применяется cross-attention. Это нужно, чтобы генерируемая картинка содержала смысл входного текста. Так вот, исследователи обнаружили, что то, как будут выглядеть и где будут находиться отдельные объекты на картинке, определяется значениями одной из матриц слоя cross-attention.
Подробнее:
В слое cross-attention диффузии query (Q) получается линейным преобразованием эмбеддинга входной картинки, а K (key) и V (value) получаются линейными преобразованиеми эмбеддинга текста. Далее из Q и K с помощью формулы ниже получается матрица M (attention Map):
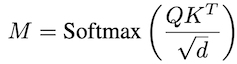
, и далее из M и V получается выход слоя cross-attention:
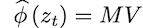
Так вот, оказывается, элемент матрицы M m_ij определяет, насколько i-ый токен промта влияет на вид j-го пикселя сгенерированной картинки.
На картинке ниже показано изображение и визуализация значений матрицы M слоев cross-attention для разных слов промта. Видно, что на них “подсвечены” те области картинок, которые семантически соответствуют словам промта:

Теперь становится понятна идея алгоритма. Она такая:
Пусть мы сгенерили картинку по запросу “Photo of a cat riding on a bicycle” — это старый промт. Запомним все матрицы M всех слоев cross-attention, который мы получали в течение этой генерации. Теперь чуть изменим текст: пусть станет “Photo of a cat riding on a car” — это новый промт. Начнем генерировать новую картинку на основе измененного текста все той же самой моделью диффузии с тем же самым начальным шумом. Но теперь на каждом шаге генерации мы будем изменять получаемые матрицы M: будем вместо них подставлять соответствующие матрицы из прошлой генерации. Значения V при этом менять не будем: будем оставлять тем, что получаются на основе нового промта. Таким образом, значения cross-attention будут вычисляться по старому M и новому V.
Ожидается, что при такой генерации структура изображения останется ровно той же, что была на картинке, сгенеренной по старому промту (так как матрицы M те же), но семантическая информация на картинке изменится согласно изменению текста (так как значения V стали новые, полученные из нового текста).
Алгоритм в итоге можно записать так:

В этом алгоритме на шаге 9 и происходит подмена матрицы M.
Однако заметим вот что: тут на шаге 9 не написано явно "вместо M* подставим M", а написано, что применяется операция Edit и получается вообще еще одна новая матрица. Почему так? Дело в том, что в таком виде, как мы только что описали, алгоритм будет работать не во всех случаях.
Смотрите, матрица M определяет структуру изображения, но не все семантические особенности объектов на нем. То есть, матрица М может задать, в какой части изображения обязательно должен находиться медведь, но не то, какого он будет вида. Из-за этого при локальном изменении текста типа "медведь на велосипеде" -> "медведь на мотоцикле" мы можем не только получить мотоцикл на картинке вместо медведя, но и небольшие изменения в самом медведе. Чтобы этого избежать, в алгоритм нужно внести пару изменений. О них и о других тонкостях работы алгоритма мы поговорим ниже.
А пока заметим, что в случае "глобальных изменений" (global editing, когда изменения касаются всех объектов картинки) описанный выше алгоритм без всяких дополнений уже работает отлично. Вот пример:

А теперь давайте поговорим о том, что делать, когда изменения "локальные" (когда некоторые объекты хочется оставить точно такими, как они были).
Алгоритм для локальных изменений
Как мы уже сказали, чтобы добиться "точечных", "локальных" изменений картинки, нам нужно чуть изменить алгоритм, который мы описали выше. Давайте поймем, как это сделать.
Начнем с того, что приведем пример такого "локального" изменения:
"A mat black car on the side street" -> "A sport car on the side street".
В данном случае мы хотим, чтобы изменился только цвет машины на картинке, а весь фон остался ровно таким, какой он был, без малейших изменений.
Авторы предлагают такую простую идею изменения алгоритма под этот случай:
Мы помним, что у матрицы M элемент m_ij определяет, насколько i-ый токен промта влияет на вид j-го пикселя сгенерированной картинки. Давайте тогда у матриц M и M* (матрицы моделей, генерирующих на основе старого и нового промтов, соответственно) выделим те элементы, которые соответствуют измененным словам. То есть, найдем элементы матрицы М, которые соответствуют словам "mat black", и элементы матрицы М*, которые соответствуют слову "sport". Этим элементам матриц M и M* соответствуют определенные пиксели картинок. Так давайте разрешим менять только эти пиксели, остальные пиксели "заморозим" и оставим такими, что были при генерации с начальным промтом "A mat black car on the side street".
Тогда обновленный алгоритм будет выглядеть так:

Такое решение хорошо работает в случае, когда при изменении текста промта изменяемый объект не меняется в размерах и форме (или меняется, но не сильно). Но часто бывает так, что изначально объект занимал одни определенные пиксели картинки, а затем должен занимать уже чуть другие пиксели.
Пример, когда возникает такая проблема: на картинке ниже вы видите две обычные генерации картинок по описаниям "Photo of a cat riding on a bicycle" и "Photo of a cat riding on a car". Видно, что на первой генерации bicycle занимает малую часть картинки, мало пикселей. А на второй генерации car — это больше половины пикселей изображения.

Если тут при замене "bicycle -> car" "заморозить" все пиксели, кроме тех, что в левой картинке соответствовали велосипеду, то диффузии придется впихнуть идею "машины" в пиксели велосипеда. И получится примерно вот такое:

А мы бы хотели что-то такое:

Получается, нужно как-то разрешить модели все же немного менять структуру объектов.
Решение, которое предлагают авторы, такое: в пункте 9 алгоритма первые 𝜏 шагов вообще не заменять матрицу M на матрицу из старой версии алгоритма. То есть, первые 𝜏 шагов диффузия будет работать в обычном режиме, генерировать картинку из нового текста "Photo of a cat riding on a car" обычным способом. И только после шага 𝜏 начать полностью заменять матрицу M на ту, что была в старой версии модели при генерации со старым промтом.
То есть, формула шага 9 получается такой:
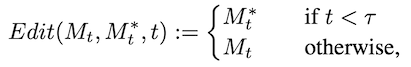
И вот какие результаты генерации получаются для разных значений 𝜏:

Ну и последний нюанс. Бывают случаи, когда мы изменяем входной текст, только добавляя туда новые слова или только выкидывая слоя, не изменяя старые. Пример:
"a castle" -> "children drawing of a castle"
Тогда, разумеется, на шаге 9 алгоритма мы заменяем не всю матрицу M* на M, а только те элементы матрицы M*, которые соответствуют общим словам "a castle".
Ну вот и все. О том, как модифицировать алгоритм под локальные изменения, мы обсудили. Напоследок давайте скажем еще вот что:
Другие применения модели
У описанной идеи есть еще пара интересных применений (связанных, однако, с идеей изменения семантики изображения). А именно:
Применение #1:
Мы можем изменять выраженность того или иного токена в сгенерированном изображении. Делается это просто: берем те значения матрицы M, которые соответствуют нужному слову, и увеличиваем/уменьшаем эти значения. (например, умножаем их все на 2 или делим их все на 2). Формула шага 9 будет выглядеть так:
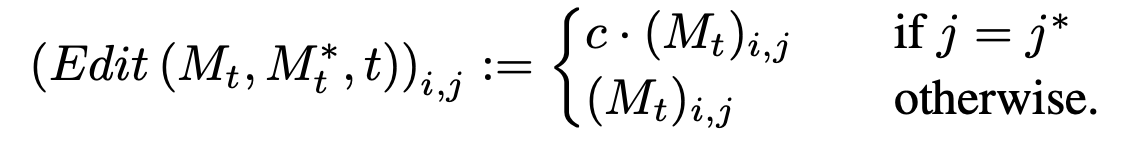
Здесь j* — номер токена, выраженность которого мы хотим менять, с — константа (-2, 0.5 или 2, к примеру)
И это правда работает, ниже на картинке вы видите пример манипулирования выраженности токена "blossom" в генерации по тексту "The picnic is ready under a blossom tree".

Видно, что при уменьшении значений матрицы M, соответствующих слову "blossom", дерево начинает "цвести" все менее выраженно.
Применение #2:
Наверное, это очевидно, но все же напишу: этим алгоритмом можно делать Style Transfer. Вот примеры:

Заключение
В целом, мне статья и идея очень понравилась. Во-первых, потому что идея нетривиальна: чтобы до такой додуматься, нужно было изучить, как модель работает внутри. Во-вторых, потому что идея все же довольно проста в реализации, и результаты при этом впечатляют.
В статье вы найдете больше деталей устройства алгоритма, сравнений с предыдущими SOTA (спойлер: если сравнения честные, то этот алгоритм просто на лее головы превосходит все предыдущие!) и больше офигенных примеров генерации.
В заключение скажу, что общая задача контроля семантической и структурной информации в генеративных моделях все еще не решена. Эта работа может контролируемой изменять уже сгенеренную диффузией картинку. Но как сгенерить картинку с объектами, вид и семантика которых полностью задана, пока непонятно.
Еще раз продублирую ссылки:
Статья: https://prompt-to-prompt.github.io/ptp_files/Prompt-to-Prompt_preprint.pdf
Код на GitHub: https://github.com/google/prompt-to-prompt