Обзор методологий, принципов и концепций разных типов хранилищ данных
https://t.me/data_analysis_mlData Warehouse Design
Подход Kimball
Модель данных Kimball — это восходящий подход к проектированию архитектуры хранилища данных (DWH или DW), в котором витрины данных сначала формируются на основе бизнес-требований.
Данные из источников данных с помощью ETL извлекаются и загружаются в промежуточную область сервера реляционной базы данных.
После того, как данные загружены в промежуточную область хранилища данных, следующий этап включает загрузку данных в многомерную модель хранилища данных, денормализованную по своей природе (схема звезда).
Эта модель разделяется на таблицу фактов, которая представляет собой числовые данные транзакций, и таблицы измерений, которые являются справочной информацией, которая является контекстом для данных в таблице фактов.
Схема «звезда» — это фундаментальный элемент модели многомерного хранилища данных.
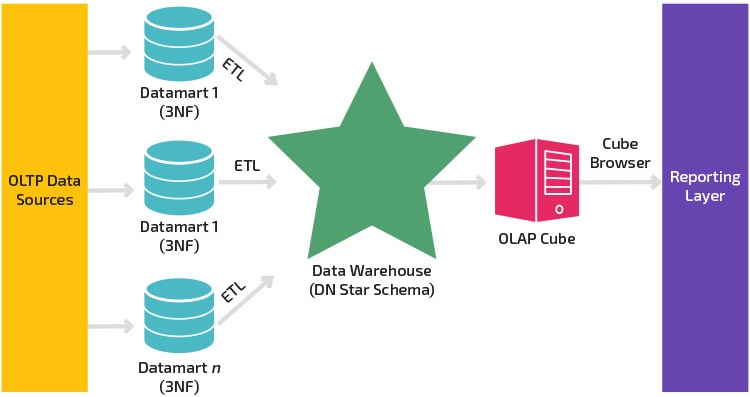
Dimensional Modeling Кимбалла позволяет пользователям создавать несколько звездообразных схем для удовлетворения различных требований к отчетности.
Преимущество звездообразной схемы заключается в том, что запросы к небольшим размерным таблицам выполняются мгновенно.
Для интеграции данных архитектура Kimball DWH предлагает идею согласованных измерений данных. Одни и те же Dimension таблицы могут совместно использоваться в разных таблицах фактов в хранилище данных, или одни и те же таблицы измерений могут использоваться в различных витринах данных Kimball. Это гарантирует, что один элемент данных используется одинаковым образом во всех отчетных формах.
Важным инструментом проектирования хранилища данных в методологии Ральфа Кимбалла является матрица шины предприятия или архитектура шины Кимбалла, которая записывает факты по вертикали и записывает согласованные измерения по горизонтали.
Преимущества подхода Кимбалла
- Kimball dimensional modeling позволяет быстро реализовывать хранилища данных поскольку не требуется нормализация данных, что позволяет быстро выполнять начальные фазы процесса проектирования хранилища данных.
- Преимущество звездообразной схемы состоит в том, что большинство операторов данных могут легко понять ее из-за ее денормализованной структуры, которая упрощает запросы и анализ.
- Площадь системы хранилища данных тривиальна, поскольку она ориентирована на отдельные области бизнеса и процессы, а не на все предприятие. Таким образом, хранилище занимает меньше места в базе данных, что упрощает управление системой.
- Это позволяет быстро извлекать данные из хранилища данных, поскольку данные разделяются на таблицы фактов и измерения. Например, таблица фактов и измерений для страховой отрасли будет включать транзакции по полисам и транзакции по претензиям.
- Для управления хранилищем данных достаточно небольшой группы проектировщиков и разработчиков, поскольку системы источников данных стабильны, а хранилище данных ориентировано на процессы. Кроме того, оптимизация запросов проста, предсказуема и управляема.
- Согласованная структура измерений для data quality framework. Подход Кимбалла также называют подходом к образу жизни, измеряющим бизнес, потому что он позволяет инструментам business intelligence глубже проникать в несколько звездообразных схем и дает надежную информацию.
Kimball Approach to Data Warehouse Lifecycle:
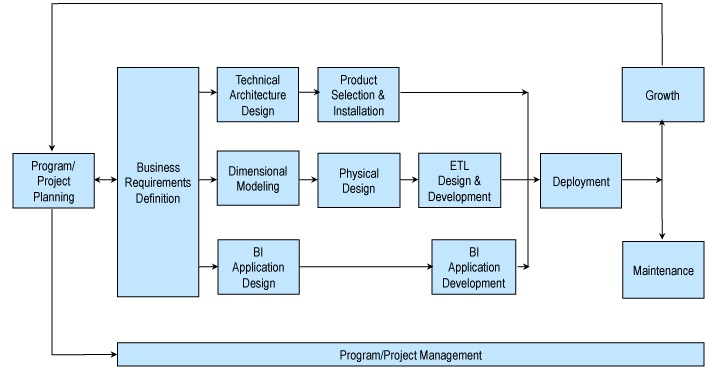
Недостатки подхода Кимбалла
- Данные не полностью интегрированы до создания отчетности, идея «единого источника правды» потеряна.
- При обновлении данных в архитектуре Kimball DWH могут возникать не точные данные. Это связано с тем, что при использовании техник денормализации хранилища данных избыточные данные добавляются в таблицы базы данных.
- В архитектуре Kimball DWH проблемы с производительностью могут возникать из-за добавления столбцов в таблицу фактов, поскольку эти таблицы содержат довольно подробные сведения. Добавление новых столбцов может расширить размерность таблицы фактов, что повлияет на ее производительность (т.е. увеличится детализация хранилища данных). Кроме того, модель многомерного хранилища данных становится трудно изменить при любых изменениях потребностей бизнеса.
- Поскольку модель Кимбалла ориентирована на бизнес-процессы, вместо того, чтобы сосредоточиться на предприятии в целом, она не может удовлетворить все требования к отчетности бизнес-аналитики.
- Процесс включения больших объемов устаревших данных в хранилище данных сложен.
Подход Inmon
Подход Bill Inmon основывается на том, что Data Warehouse является централизованным хранилищем всех корпоративных данных. При использовании этого подхода организация сначала создает нормализованную модель хранилища данных. Затем на основе единого хранилища данных создаются витрины размерных данных. Это известно как нисходящий подход к хранилищу данных.
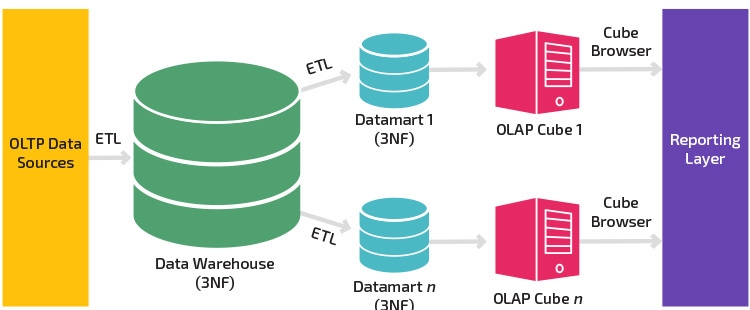
Детальная последовательность работ:
Этот метод начинается с моделирования корпоративных данных. Сначала определяются основные предметные области и сущности (клиенты, продукт/услуга, поставщики и т.д.). Затем на основе этого создается подробная логическая модель для каждой сущности. Структура сущности имеет нормализованный вид, по возможности избегается избыточность данных. Это ключевая характеристика этого метода, позволяющая определить бизнес-концепцию и избежать аномалий обновления данных.
Такая структура упрощает загрузку данных. Но использовать структуру для запросов сложно из-за большого количества таблиц и объединений.
Bill Inmon предлагает строить витрины данных для каждого конкретного отдела (финансов, продаж, развития бизнеса, маркетинга и т.д.). Все данные интегрированы, а хранилище данных — это единый источник данных из разных витрин. Такая концепция гарантирует полноту и согласованность данных во всей организации.
Преимущества подхода Инмона
- Хранилище данных действует как единый источник истины для всего бизнеса, где все данные интегрированы.
- Этот подход имеет очень низкую избыточность данных. Таким образом, уменьшается вероятность сбоев в обновлении данных, что делает процесс хранилища данных ETL более простым и менее подверженным сбоям.
- Это упрощает бизнес-процессы, поскольку логическая модель представляет подробные бизнес-объекты.
- Этот подход обеспечивает большую гибкость, поскольку проще обновлять хранилище данных в случае каких-либо изменений в бизнес-требованиях или исходных данных.
- Он может обрабатывать разнообразные требования к отчетности в масштабе всего предприятия.
Недостатки подхода Инмона
- Сложность увеличивается со временем по мере добавления нескольких таблиц в модель данных.
- Требуются разработчики, обладающие навыками моделирования и проектирования хранилищ данных, которые могут быть дорогими и недоступными на рынке труда.
- Первичная разработка и ввод в эксплуатацию занимают много времени.
- Требуется дополнительная операция ETL, поскольку витрины данных создаются после создания хранилища данных.
- Этот подход требует от экспертов эффективного управления хранилищем данных.
Kimball vs Inmod Data Warehouse Architectures
Архитектуры Кимбалла и Инмон имеют одну и ту же общую черту: каждая имеет единый интегрированный репозиторий атомарных данных. В архитектуре Inmon это называется корпоративным хранилищем данных. А в архитектуре Кимбалла это известно как пространственное хранилище данных. Обе архитектуры ориентированы на предприятие, которое поддерживает анализ информации в масштабах всей организации. Такой подход позволяет реализовывать бизнес-требования не только в рамках предметной области, но и между предметными областями.
Однако есть некоторые различия в этих подходах:
- Kimball использует размерную модель, такую как схема «Звездочка» или «Снежинка», для организации данных в пространственном хранилище данных, в то время как Inmon использует ER-модель в корпоративном хранилище данных. Inmon использует размерную модель только для витрин данных, в то время как Kimball использует ее для всех данных.
- Inmon использует витрины данных как физическое отделение от корпоративного хранилища данных, и они предназначены для использования в отделах. В архитектуре Кимбалла нет необходимости отделять витрины данных от пространственного хранилища данных.
- В многомерном хранилище данных Кимбалла аналитические системы могут получать доступ к данным напрямую. В архитектуре Inmon аналитические системы могут получать доступ к данным в корпоративном хранилище данных только через витрины данных.
Согласно философии Кимбалла, сначала все начинается с критически важных витрин данных, которые обслуживают аналитические потребности отделов. Затем он интегрирует эти витрины данных для обеспечения согласованности данных через так называемую информационную шину. Kimball использует размерную модель для удовлетворения потребностей отделов в различных областях внутри предприятия.
Билл Инмон рекомендует строить хранилище данных по принципу «сверху вниз». Согласно философии Inmon, это начинается с создания большого централизованного корпоративного хранилища данных, в котором все доступные данные из систем транзакций консолидируются в предметно-ориентированный, интегрированный, изменчивый по времени и энергонезависимый набор данных, который поддерживает принятие решений, а затем строятся витрины данных для аналитических нужд отделов.
Подход DW 2.0 — Bill Inmon
В DW 2.0 было признано несколько важных аспектов среды хранилища данных.
Одним из них был жизненный цикл данных в среде хранилища данных. Со временем данные начали доживать свой собственный жизненный цикл после того, как были введены в хранилище данных.
Еще одним важным моментом DW 2.0 было то, что неструктурированные данные стали важным аспектом мира хранилищ данных.
До DW 2.0 единственными данными, которые можно было найти в хранилищах данных, была оперативная структурированная информация. Но с DW 2.0 было признано, что неструктурированные данные также могут загружаться в хранилище данных.
Еще одним открытием DW 2.0 стало признание того, что метаданные являются неотъемлемой частью инфраструктуры. DW 2.0 признал, что корпоративные метаданные так же важны, как и локальные. И, наконец, примерно в то время, когда обсуждался DW 2.0, было признано, что дизайн хранилищ данных был значительно улучшен за счет достижений Data Vault.
Но, пожалуй, самым большим достижением DW 2.0 стало осознание необходимости другой формы массового хранения. Фактически, оперативное хранилище было предшественником больших данных.
Эволюция информационной архитектуры
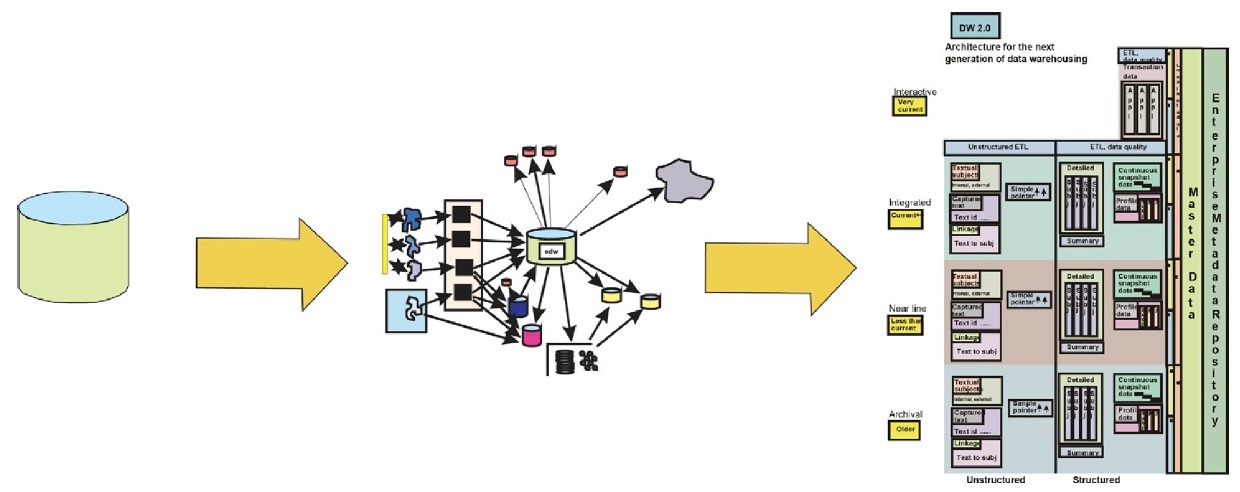
DW 2.0 — это определение архитектуры хранилища данных для следующего поколения хранилищ данных.
Чтобы понять, как появился DW 2.0, рассмотрим следующие факторы:
- В хранилищах данных первого поколения упор делался на создание хранилища данных и на adding business value. Во времена хранилищ данных первого поколения получение ценности означало получение преимущественно числовых транзакционных данных и их интеграцию. Сегодня получение максимальной выгоды от корпоративных данных означает использование ВСЕХ корпоративных данных и извлечение из них ценности. Это означает включение текстовых неструктурированных данных, а также числовых данных транзакций.
- В хранилищах данных первого поколения не уделялось особого внимания носителю, на котором хранятся данные, или их объему. Но время показало, что носитель, на котором хранятся данные, и их объем — действительно очень большие проблемы.
- В хранилищах данных первого поколения было признано, что интеграция данных является проблемой. В современном мире признано, что интеграция старых данных — еще более серьезная проблема, чем то, что когда-то считалось.
- В хранилищах данных первого поколения затраты практически не возникали. В современном мире стоимость хранилищ данных является главной проблемой.
- В хранилищах данных первого поколения метаданными не уделялось должного внимания. В сегодняшнем мире управление метаданными и основными данными является серьезной проблемой.
- На заре создания хранилищ данных первого поколения хранилища данных считались новинкой. В современном мире хранилища данных считаются фундаментом, на котором основано конкурентное использование информации. Хранилища данных стали незаменимыми.
- На заре создания хранилищ данных упор делался на простое создание хранилища данных. В современном мире признано, что хранилище данных должно быть гибким с течением времени, чтобы соответствовать меняющимся требованиям бизнеса.
- На заре создания хранилищ данных было признано, что хранилище данных может быть полезно для статистического анализа. Сегодня признано, что наиболее эффективное использование хранилища данных для статистического анализа — это связанная структура хранилища данных, называемая исследовательским хранилищем.
Структура данных в DW 2.0
DW 2.0 — это новая парадигма хранилищ данных. Это парадигма, которая фокусируется на основных типах данных, их структуре и том, как они связаны, чтобы сформировать мощное хранилище данных, которое удовлетворяет потребности корпорации в информации.
На рисунке изображена новая архитектура DW 2.0. Здесь показаны различные типы данных, их базовая структура и их взаимосвязь.
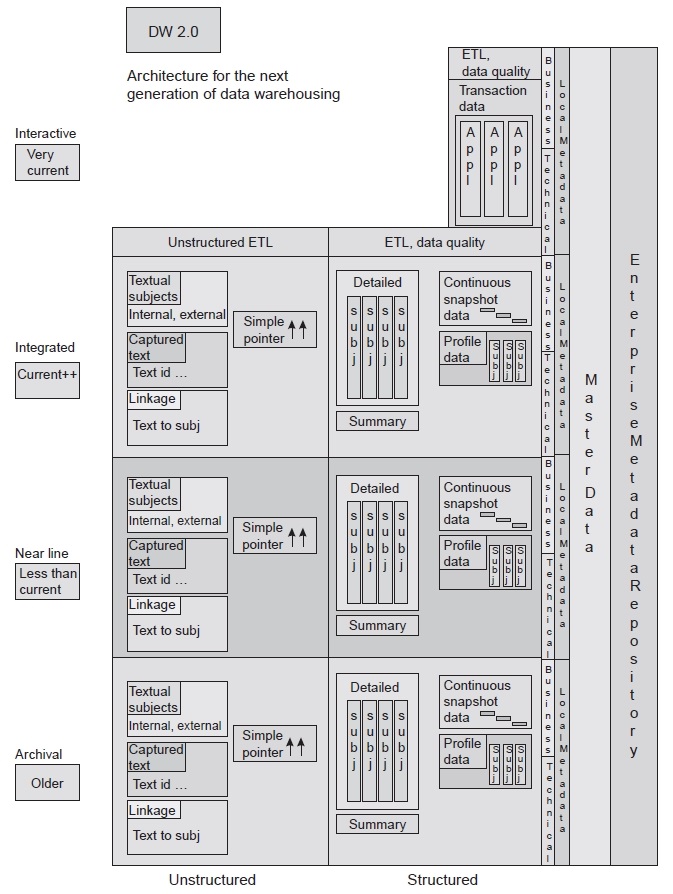
Подход Data Vault v2.0
Data Vault — это инновационная методология моделирования данных для крупномасштабных платформ хранилищ данных. Подход Data Vault, который был изобретен Дэном Линстедтом. В 2013 году Дэн Линстедт представил новую версию Data Vault 2.0.
Модель Data Vault — это детально ориентированный, исторически отслеживаемый и однозначно связанный набор нормализованных таблиц, которые поддерживают одну или несколько функциональных областей бизнеса. В Data Vault 2.0 сущности модели имеют hash-ключи, тогда как в Data Vault 1.0 сущности модели имеют ключи последовательностей.
Стиль моделирования представляет собой гибрид методов третьей нормальной формы и методов размерного моделирования, уникально объединенный для удовлетворения потребностей предприятия. Модель Data Vault также основана на шаблонах, обнаруженных в схемах типа «hub-and-spoke», также известных как «scale-free network».
Пример модели Data Vault
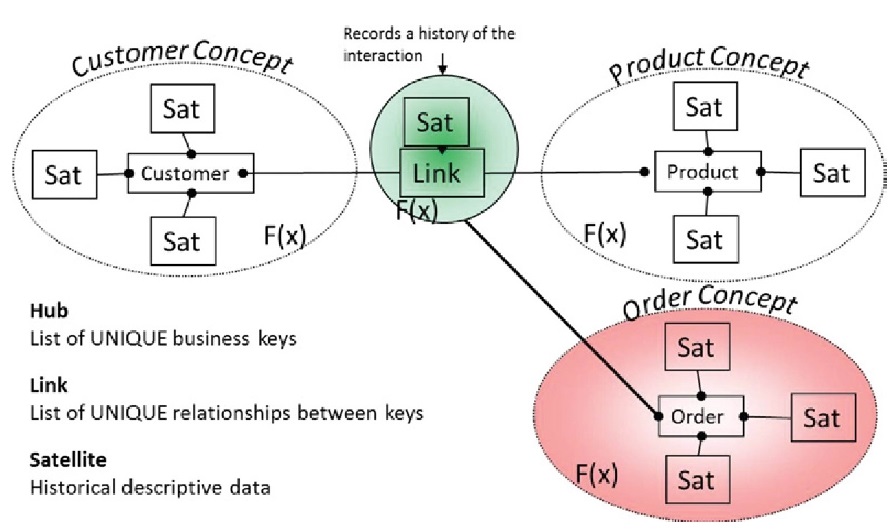
Эти шаблоны проектирования позволяют модели Data Vault наследовать немасштабируемые атрибуты, что означает, что нет никаких известных внутренних ограничений на размер модели или размер данных, которые модель может представлять, кроме ограничений, налагаемых инфраструктурой.
Архитектура Data Vault состоит из трех основных структур:
- Hub (Хаб) — естественный бизнес-ключ
- Link (Ссылка) — естественные деловые отношения
- Satellite (Сателлит или Спутник) — весь контекст, описательные данные и история

или

Hub (Хаб)
Хаб — основной бизнес-объект внутри компании (покупатель, товар, склад, магазин).
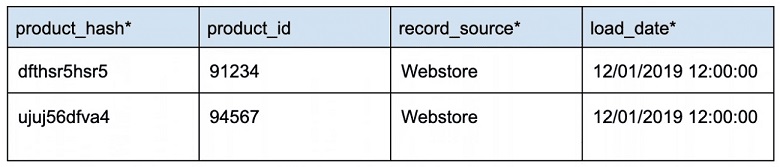
Hub не содержат никаких контекстных данных или сведений о сущности. Они содержат только определенный бизнес-ключ и несколько обязательных полей Data Vault. Важным атрибутом Hub является то, что они содержат только одну строку на ключ.
Пример Data Vault Hub:
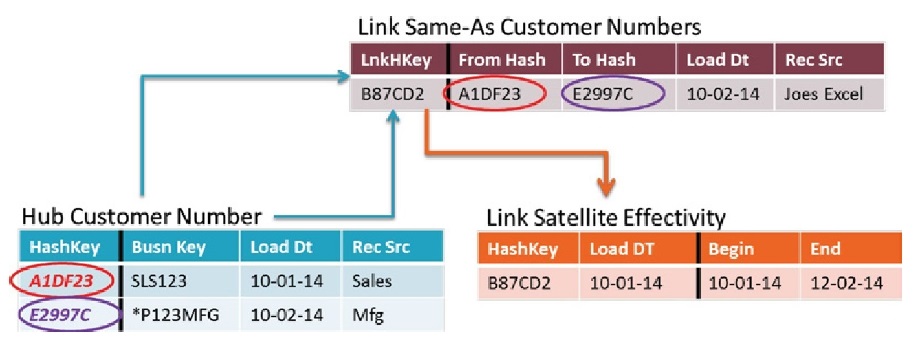
Link (Ссылка)
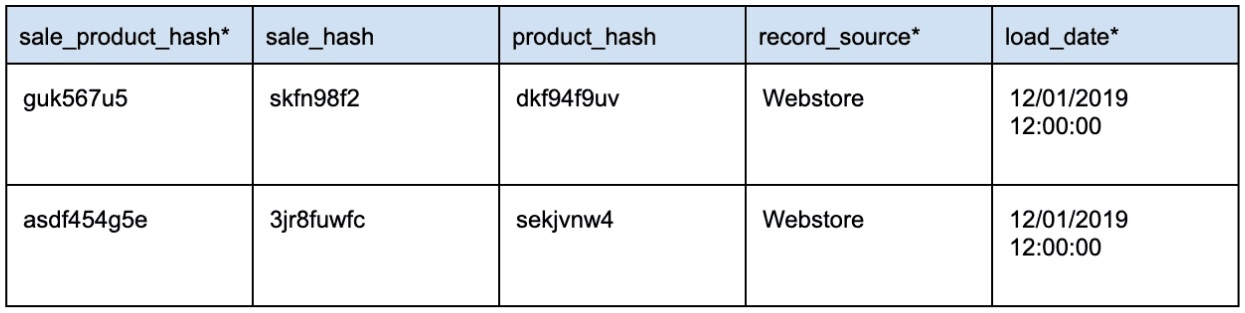
Link определяет отношения между бизнес-ключами от двух или более Hub. Link — это таблица, в которой хранятся пересечения бизнес-ключей нескольких HUB, эта таблица обеспечивает связь типа многие-ко-многим.

Пример таблицы Link:
Satellite (Сателлит или Спутник)
В архитектуре Data Vault сателлит (satellite) содержит все контекстные детали (все описательные атрибуты), относящиеся к сущности (hub).
Важной функцией Satellite является хранение истории изменения данных.
При изменении данных в системе-источнике необходимо вставить новую строку с измененными данными. Эти записи отличаются друг от друга с помощью хеш-ключа и одного из обязательных полей Data Vault: load_date. Для данной записи load_date позволяет нам определить, какая запись самая последняя.
Пример:
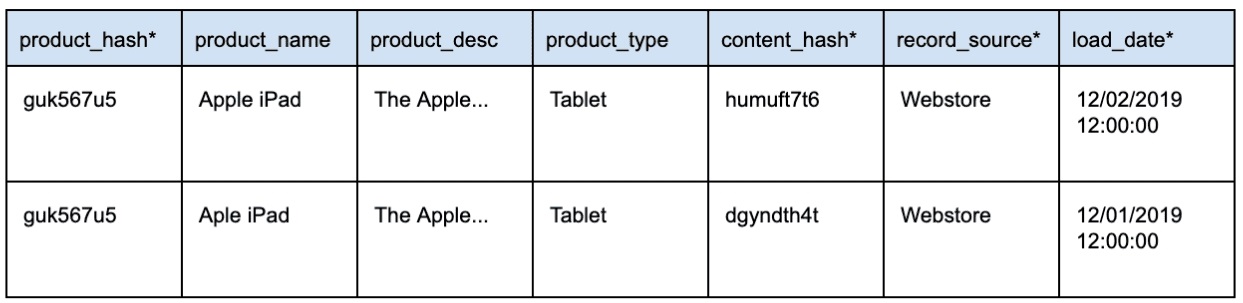
Возникает закономерный вопрос: «Но разве не потребуется вечность, чтобы определить, что изменилось между источником и хранилищем данных?»
Нет — это очень эффективно с использованием content_hash.
Content_hash вычисляется при заполнении промежуточной области Data Vault. Content_hash будет использовать все соответствующие контекстные поля данных. Когда любое из этих полей контекстных данных обновляется, будет вычисляться другой content_hash. Это позволяет очень быстро обнаруживать изменения.
Чтобы помочь с дифференциацией, спутники создаются на основе источника данных и скорости его изменения (точнее частоты изменения данных). Как правило, вы разрабатываете новую таблицу Satellite для каждого источника данных, а затем дополнительно отделяете данные из тех источников, которые могут изменяться с высокой частотой. Разделение высокочастотных и низкочастотных атрибутов данных может повысить пропускную способность приема и значительно сократить пространство, которое занимают исторические данные. Разделение атрибутов по частоте не является обязательным, но это может дать некоторые преимущества.
Как выглядит хранилище данных Data Vault?

Data Vault 2.0 Data model
Методология Data Vault позволяет командам очень быстро получать новые источники данных.
Данные из нового источника могут быть вставлены сразу в новую таблицу Satellite (без перепроектирования справочника, оценки изменений и т.д. как это требуется например в Kimball). Это позволяет инженерам по обработке данных быстро взаимодействовать с бизнес-пользователями при создании новых информационных витрин.
Вам нужно интегрировать в Data Vault совершенно новые бизнес-объекты? Вы можете добавить новые Hub в любое время, и вы можете определить новые отношения, создав новые таблицы link между hub. Этот процесс не оказывает никакого влияния на существующую модель.
Архитектура Data Vault
Data Vault предоставляет многоуровневую архитектуру, которая является масштабируемой и гибкой.
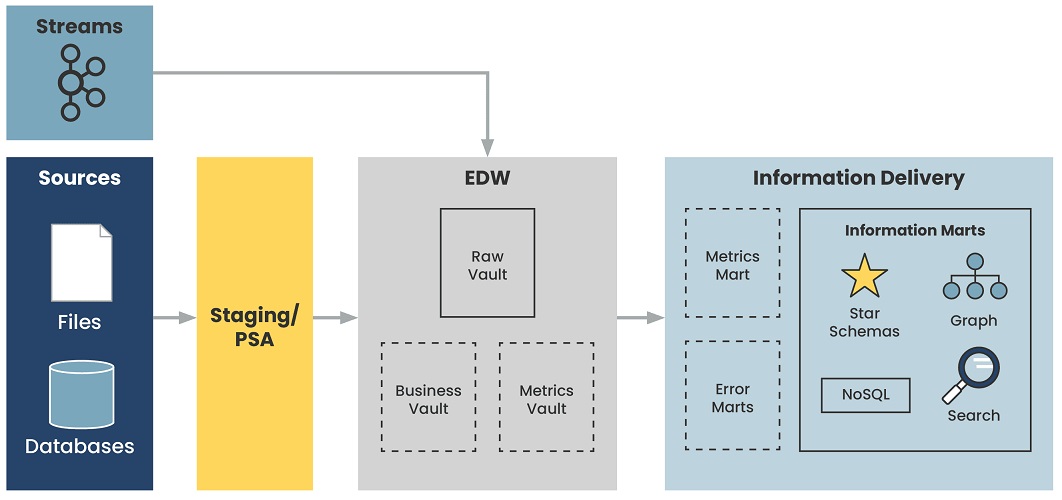
Staging
Сначала данные из операционных систем поступают в Staging зону. Staging используется как промежуточное звено в процессе загрузки данных. Одна из основных функций этой промежуточной зоны — это снижение нагрузки на реляционные DB при выполнении запросов. Таблицы здесь полностью повторяют исходную структуру, при этом любые ограничения на вставку данных, например not null или проверки целостности внешних ключей, следует выключить, чтобы была возможность вставить даже поврежденные или неполные данные. Это очень актуально для excel-таблиц, Google Sheets, самописных решений без надлежащего контроля качества данных. Дополнительно в stage таблицах содержатся хеши бизнес-ключей и информация о времени загрузки и источнике данных.
Enterprise Data Warehouse
Raw
Raw — это то место, где живет наша основная модель Data Vault (hub, links, satellites). Данные загружаются в необработанный слой непосредственно из промежуточного уровня или, возможно, непосредственно в необработанный уровень при обработке источников данных в реальном времени. При загрузке на уровень Raw к данным также не должны применяться бизнес-правила.
Data Ingestion в Raw является важным шагом в архитектуре Data Vault и должно выполняться правильно для обеспечения согласованности.
Business Vault
Business Vault — это дополнительный уровень в Data Vault, где компания может определять общие бизнес-объекты, вычисления и логику. Это могут быть такие вещи, как Master Data или создание бизнес-логики, которая используется во всем бизнесе на различных Information Marts. Эти вещи не должны реализовываться в каждом information mart по-разному, это должно быть реализовано один раз в Business Vault и многократно использоваться через Information Marts.
Metrics Vault
Metrics Vault (Хранилище метрик) — это дополнительный уровень, используемый для хранения данных операционных метрик для процессов Data Vault Ingestion. Эта информация может быть бесценной при диагностике потенциальных проблем с data ingestion process. Metrics Vault может также использоваться как контрольный журнал для всех процессов, взаимодействующих с Data Vault.
Information Delivery
Information Marts
Информационные витрины — это то место, где бизнес-пользователи, наконец, получат доступ к данным. Все бизнес-правила и логика теперь применяются в этих витринах.
Для реализации бизнес-правил и логики методология Data Vault также в значительной степени опирается на использование SQL Views вместо создания конвейеров. Views позволяют разработчикам очень быстро реализовывать и согласовывать с бизнесом требования при внедрении информационных витрин. Наличие слишком большого количества конвейеров — это просто еще одна проблема, которую нужно поддерживать и беспокоиться о повторном запуске. Бизнес-пользователи могут отправлять запросы ко Views, зная, что они всегда получают доступ к последним данным.
Error Marts
Error Marts — это дополнительный уровень в Data Vault, который может быть полезен для выявления проблем с данными для бизнес-пользователей. Помните, что все данные, правильные или нет, должны оставаться в качестве исторических данных в Data Vault для аудита и отслеживания.
Metrics Marts
Metrics Mart — это дополнительный уровень, используемый для отображения операционных показателей для аналитических целей или отчетов.
Data Vault Rules v1.0.8 Cheat Sheet
Data Vault Rules v1.0.8 Cheat Sheet.pdf
Базовые правила построения модели Data Vault
При создании модели Data Vault необходимо сначала создать сущности и описать их атрибуты, а затем установить связи между ними. Сущности должны создаваться в следующем порядке.
- Сущности-Hub должны содержать бизнес-ключи предметной области.
- Сущности-Link для поддержки взаимосвязей между бизнес-ключами, т.е. информация о деятельности организации в контексте бизнес-ключей.
- Сущности-Satellite для описания полной картины деятельности организации с точки зрения бизнес-процедур.
- Сущности Point In Time (PIT) для обеспечения поиска моментов времени изменения описательной информации.
При создании связей в структуре модели Data Vault следует соблюдать правила поддержки ссылочной целостности (referential integrity).
- Ключи Hub не могут мигрировать в другие концентраторы, т.е. не поддерживается отношение «родитель-потомок» для Hub.
- Hub взаимодействуют между собой через Link таблицы.
- Сущность-Link может быть использована для связи более двух Hub.
- Сущности-Link могут быть связаны друг с другом.
- Сущности-Link должны связывать минимально два Hub.
- Суррогатные ключи могут использоваться для Hub и Link.
- Бизнес-ключи Hub никогда не изменяются, так же, как и их первичные ключи.
- Satellite могут связываться с Hub и Link.
- Могут быть использованы стандартные таблицы временных меток (standalone table), такие как календарь, время, код и описание.
- Satellite всегда содержат либо временную метку загрузки, либо числовой указатель на временную метку загрузки (на стандартные таблицы временных меток).
- Сущности-Link могут иметь суррогатные ключи.
- Если Hub имеет более двух Satellite, то может быть создана сущность Point In Time.
- В Satellite не должно быть строк-дубликатов.
- Данные в Satellite разделяются по типу информации или по скорости изменения.
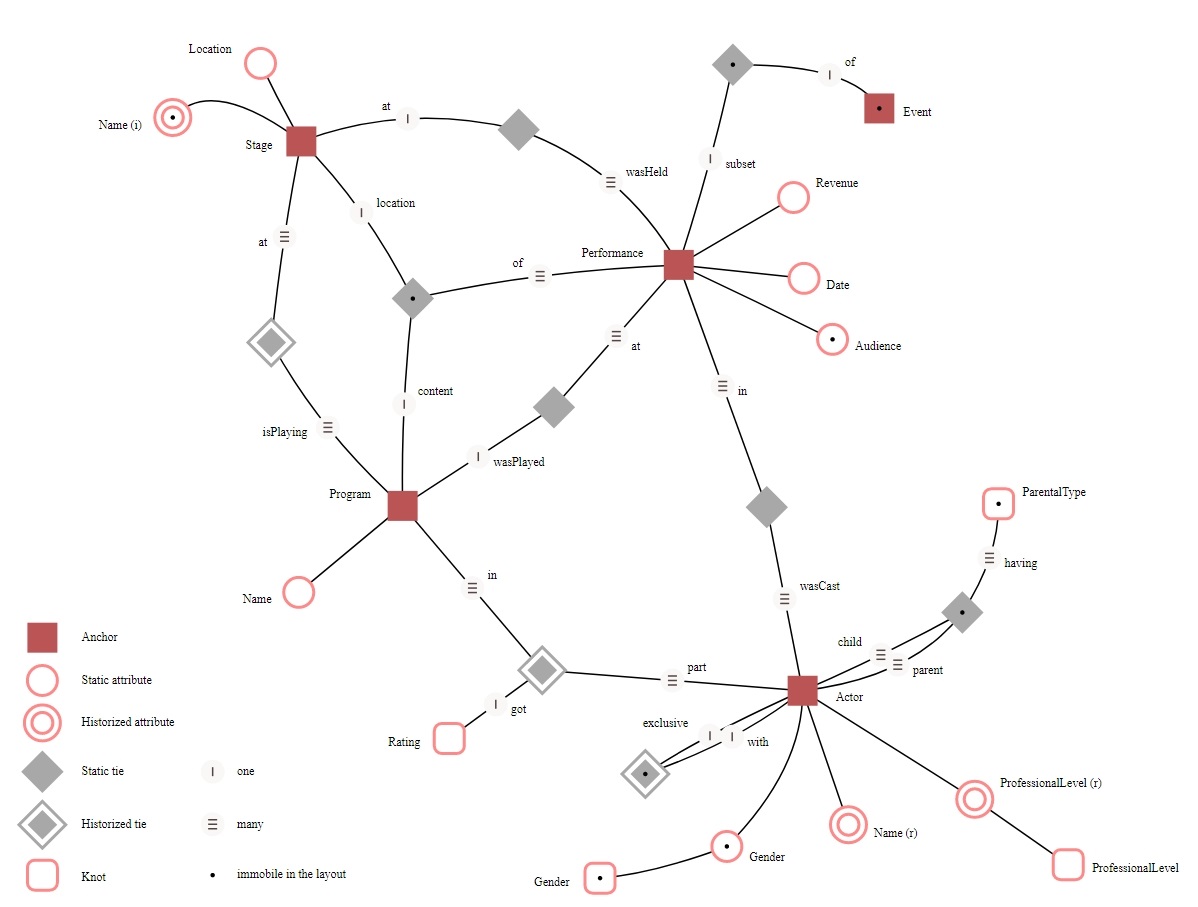
Подход Anchor
Anchor modeling (Якорное моделирование или модель привязки) — это гибкий метод моделирования хранилищ данных, подходящий для информации, которая со временем изменяется как по структуре, так и по содержанию. Он предоставляет графическую нотацию, используемую для концептуального моделирования, аналогичную моделированию сущностей-отношений, с расширениями для работы с временными данными. Техника моделирования включает четыре конструкции моделирования: якорь (привязку), атрибут, связь и узел, каждая из которых отражает различные аспекты моделируемой области. Полученные модели можно преобразовать в проекты физических баз данных с использованием формализованных правил. Когда такой перевод будет выполнен, таблицы в реляционной базе данных будут в основном в шестой нормальной форме.
Эта модель позволяет гибко реагировать на изменения сохраненных данных или добавление новых данных. Это также позволяет более эффективно сжимать данные и быстрее работать с ними.
Например, чтобы добавить новый атрибут к существующей сущности, вы можете просто создать другую таблицу и сообщить аналитикам о необходимости создания для нее соединений.
Пример якорной модели
Подборки видео
https://t.me/itchannels_telegram