Обнаружение уязвимостей в теории и на практике
https://t.me/it_ha
Сегодня разработку качественного программного обеспечения трудно представить без использования методов статического анализа кода. Статический анализ программного кода может быть встроен в среду разработки (стандартными методами или с помощью подключаемых модулей), может выполняться специализированным программным обеспечением перед запуском кода в промышленную эксплуатацию либо «вручную» штатным или внешним экспертом.
Часто встречается рассуждение, что динамический анализ кода или тесты на проникновение могут заменить статический анализ, так как эти методы проверки выявят реальные проблемы и ложных срабатываний не будет. Однако это спорный вопрос, потому что динамический анализ, в отличие от статического, не проверяет весь код, а проверяет только устойчивость программного обеспечения к набору атак, которые имитируют действия злоумышленника. Злоумышленник может оказаться изобретательнее проверяющего вне зависимости от того, кто выполняет проверку: человек или машина.
Динамический анализ будет полным только в том случае, если выполняется на полном тестовом покрытии, что в применении к реальным приложениям — трудновыполнимая задача. Доказательство полноты тестового покрытия — алгоритмически неразрешимая задача.
Обязательный статический анализ программного кода — один из необходимых шагов при вводе в эксплуатацию программного обеспечения с повышенными требованиями к информационной безопасности.
В настоящий момент на рынке представлено множество различных статических анализаторов кода, и постоянно появляются все новые и новые. На практике бывают случаи, когда для повышения качества проверки используют несколько статических анализаторов совместно, так как разные анализаторы ищут разные дефекты.
Почему нет универсального статического анализатора, который полностью проверял бы любой код и находил бы все дефекты в нем без ложных срабатываний и при этом работал бы быстро и не требовал много ресурсов (процессорного времени и памяти)?

Немного об архитектуре статических анализаторов
Ответ на этот вопрос кроется в архитектуре статических анализаторов. Почти все статические анализаторы так или иначе построены по принципу компиляторов, то есть в их работе присутствуют этапы преобразования исходного кода — такие же, какие выполняет компилятор.
Все начинается с лексического анализа, который получает на вход текст программы на языке высокого уровня, а на выход подает поток лексем. Дальше полученный поток лексем передается на вход синтаксическому анализатору, который разбирает языковые конструкции и передает результат разбора семантическому анализатору, который в результате своей работы выполняет подготовку для построения внутреннего представления. Это внутреннее представление является особенностью каждого статического анализатора. От того, насколько оно удачно, зависит эффективность работы анализатора.
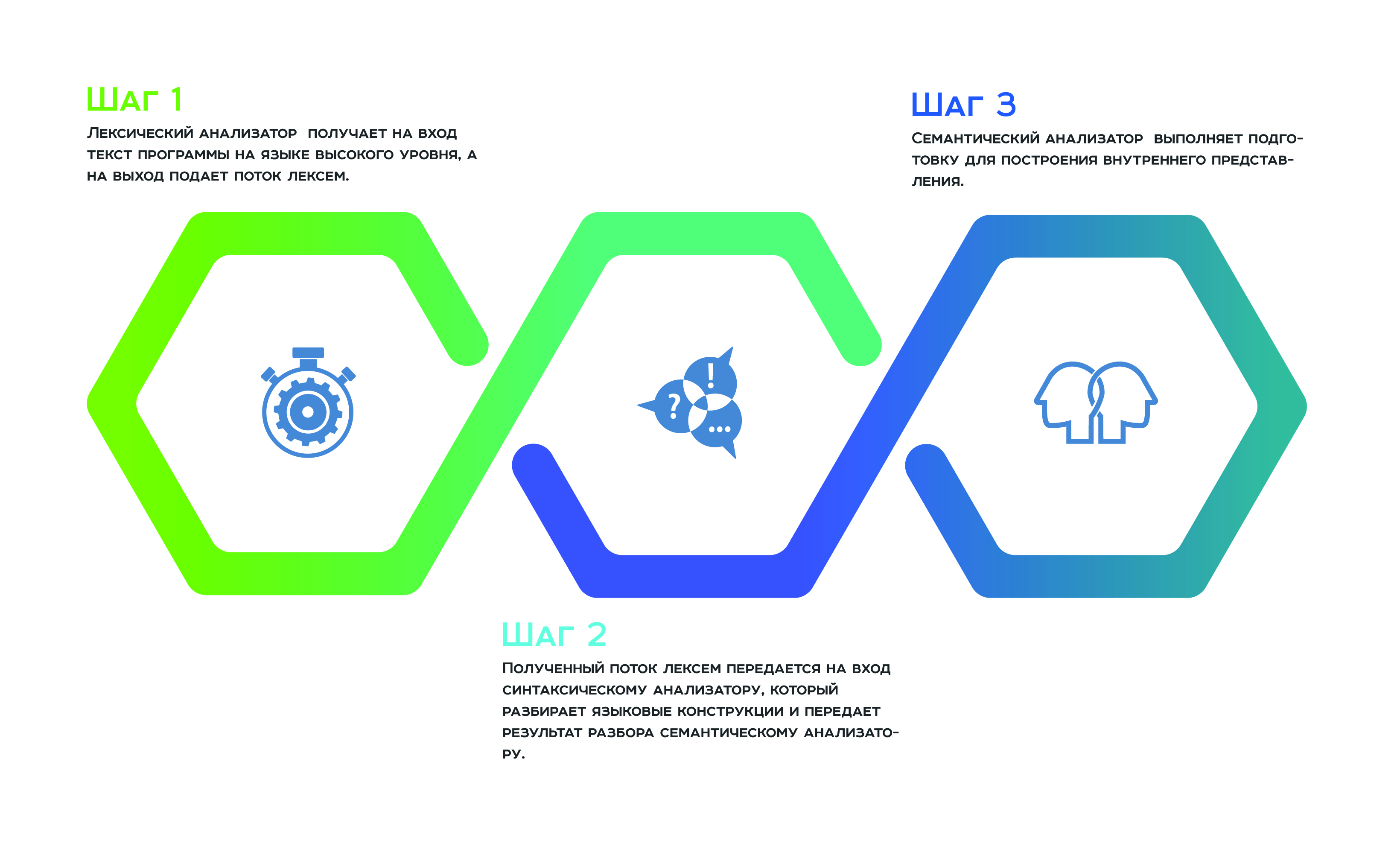
Многие производители статических анализаторов заявляют, что используют универсальное внутреннее представление для всех поддерживаемых анализатором языков программирования. Таким образом они могут анализировать программный код, разработанный на нескольких языках, как единое целое, а не как отдельные компоненты. «Целостный подход» к анализу позволяет избежать пропуска дефектов, которые возникают на границе взаимодействия отдельных составляющих программного продукта.
В теории это действительно так, но на практике универсальное внутреннее представление для всех языков программирования сложно и неэффективно. Каждый язык программирования особенный. Внутреннее представление — это обычно дерево, вершины которого хранят атрибуты. Выполняя обход такого дерева, анализатор собирает и преобразовывает информацию. Следовательно, каждая вершина дерева должна содержать однородный набор атрибутов. Так как каждый язык уникален, однородность атрибутов можно поддерживать только избыточностью составляющих. Чем более разнородны языки программирования, тем больше разнородных составляющих в характеристике каждой вершины, а значит, внутреннее представление неэффективно по памяти. Большое количество разнородных характеристик также влияет на сложность обходчиков дерева, а значит, влечет за собой неэффективность по производительности.
Оптимизационные преобразования для статических анализаторов
Чтобы статический анализатор работал эффективно по памяти и времени, надо иметь компактное универсальное внутреннее представление, а этого можно достичь тем, что внутреннее представления разбито на несколько деревьев, каждое из которых разработано для родственных языков программирования.
Разделением внутреннего представления по родственным языкам программирования оптимизационные работы не ограничиваются. Дальше производители используют различные оптимизационные предобразования — такие же, как в компиляторных технологиях, в частности, оптимизационные преобразования циклов. Дело в том, что цель статического анализа в идеале — выполнить продвижение данных по программе для того, чтобы оценить их трансформацию во время выполнения программ. Поэтому данные должны быть «продвинуты» через каждый виток цикла. А значит, если сэкономить на этих самых витках и сделать их существенно меньше, то мы получим существенную выгоду как по памяти, так и по производительности. Именно для этого активно используют такие преобразования, которые с некоторой вероятностью выполняют экстраполяцию преобразования данных на все витки цикла по минимальному числу проходов.
Также можно сэкономить на ветвлениях, рассчитав вероятность того, что выполнение программы пойдет по той или иной ветке. Если вероятность прохода по ветке ниже заданной, то эта ветка программы не рассматривается.
Очевидно, что каждое из таких преобразований «теряет» дефекты, которые должен обнаруживать анализатор, но это «плата» за эффективность по памяти и производительности.
Что ищет статический анализатор кода?
Условно дефекты, которые так или иначе интересуют злоумышленников, а следовательно, и аудиторов, можно разделить на следующие группы:
- ошибки валидирования,
- ошибки утечки информации,
- ошибки аутентификации.
Ошибки валидирования возникают в результате того, что входные данные недостаточно полно проверяются на корректность. Злоумышленник может подсунуть в качестве входных данных совсем не то, чего ожидает программа, и тем самым получить несанкционированный доступ к управлению. Наиболее известные ошибки валидирования данных — это injections и XSS. Вместо валидных данных злоумышленник подает на вход программе специальным образом подготовленные данные, которые несут в себе небольшую программу. Это программа, попадая на обработку, выполняется. Результатом ее выполнения может быть передача управления другой программе, порча данных и многое, многое другое. Также в результате ошибок валидирования может выполняться подмена сайта, с которым работает пользователь. Ошибки валидирования качественно можно обнаруживать статическими методами анализа кода.
Ошибки утечки информации — это ошибки, связанные с тем, что чувствительная информация от пользователя в результате обработки была перехвачена и передана злоумышленнику. Может быть и наоборот: чувствительная информация, которая хранится в системе, в процессе ее движения к пользователю перехватывается и передается злоумышленнику.
Такие уязвимости так же сложно обнаруживать, как и ошибки валидирования. Обнаружения такого рода ошибок требует отслеживания в статике продвижения и преобразования данных по всему коду программы. Для этого необходима реализация таких методов, как taint analysis и межпроцедурный анализ данных. От того, насколько качественно эти методы разработаны, во многом зависит точность выполнения анализа, а именно, минимизация ложных срабатываний и пропущенных ошибок.
Также немалую роль в точности работы статического анализатора играет библиотека правил обнаружения дефектов, в частности, формат описания этих правил. Все это является конкурентным преимуществом каждого анализатора и тщательно оберегается от конкурентов.
Ошибки аутентификации — это самые интересные для злоумышленника ошибки, так как их трудно обнаруживать, потому что они возникают на стыке компонент и трудно формализуются. Злоумышленники эксплуатируют такого рода ошибки для эскалации прав доступа. Автоматически ошибки аутентификации не обнаруживаются, так как не понятно, что искать, — это ошибки логики построения программы.
Ошибки работы с памятью
Их сложно обнаружить, потому что для точной идентификации требуется решить громоздкую систему уравнений, а это затратно как по памяти, так и по производительности. Следовательно, система уравнений редуцируется, а значит, теряется точность.
К типичным ошибкам работы с памятью можно отнести use-after-free, double-free, null-pointer-dereference и их разновидности, например, out-of-bounds-Read и out-of-bounds-Write.
Когда очередной анализатор не справился с обнаружением утечки памяти, можно услышать, что такие дефекты сложно эксплуатировать. Злоумышленник должен обладать высокой квалификацией и применить немало сноровки, чтобы, во-первых, узнать о наличии такого дефекта в коде, а, во-вторых, сделать эксплоит. Ну, и дальше аргументация такая: «Вы уверены, что ваш программный продукт интересен гуру такого уровня?»… Однако история знает случаи, когда ошибки работы с памятью успешно эксплуатировались и наносили немалый ущерб. В качестве примеров можно привести такие известные ситуации, как:
- CVE-2014-0160 — ошибка в библиотеке openssl — потенциальная компрометация приватных ключей потребовала перевыпуска всех сертификатов и перегенерации паролей.
- CVE-2015-2712 — ошибка в реализации js в mozilla firefox — bounds check.
- CVE-2010-1117 — use after free в internet explorer — remotely exploitable.
- CVE-2018-4913 — use after free in Acrobat Reader — code execution.
Еще злоумышленники любят эксплуатировать дефекты, связанные с неправильной синхронизацией работы нитей или процессов. Такие дефекты сложно идентифицировать в статике, потому что промоделировать состояние машины без понятия «время» — непростая задача. Здесь имеются ввиду ошибки типа race-condition. А сегодня параллелизм используется везде, даже в совсем небольших приложениях.
Подводя итог вышесказанному, надо отметить, что статический анализатор полезен в процессе разработки, если он правильно используется. В процессе эксплуатации необходимо понимать, чего от него ждать и как быть с теми дефектами, которые статический анализатор в принципе не может идентифицировать. Если говорят, что статический анализатор не нужен в процессе разработки, значит, его просто не умеют эксплуатировать.

Как правильно эксплуатировать статический анализатор, правильно и эффективно работать с информацией, которую он выдает, читайте дальше в нашем блоге.