Новые функции в Google Sheets (2023-02-02)
Michael SmirnovПравильный канал о Таблицах (Google Sheets): @google_sheets
Чат канала: @google_spreadsheets_chat
Здравствуйте, товарищи!
2-го февраля запостили тут добрые люди список новых функций (ставьте лайки, подписывайтесь на канал и всё такое). Для них уже есть документация, но пока они не доехали до всех пользователей, но скоро доедут, и можно будет пользоваться.

В основном функции очень полезные. Полезность тут в том, что большие формулы станут короче и понятнее - и это очень хорошо.
Пока новые функции не доехали, для общего развития расскажем, как те же результаты можно получить с помощью старых функций, которые уже есть. А так - все новые функции нормально описаны в документации, примеры там тоже есть.
Кому не охото читать - вот сразу таблица с примерами. Зелёным отмечены ячейки с новыми формулами, жёлтым - со старыми.
EPOCHTODATE()
Преобразует отметку времени в секундах, миллисекундах или микросекундах в дату и время в формате UTC.
https://support.google.com/docs/answer/13193461
UTC - это, вроде бы, не формат, а стандарт, ну, да ладно.
Функция EPOCHTODATE() преобразует unix epoch в привычные год, месяц, день, часы, минуты, секунды.
Unix epoch (unix time, POSIX time) - это время, представленное в виде, количества секунд (или миллисекунд, или микросекунд - для этих случаев у функции есть второй параметр), прошедших с 01.01.1970 00:00:00.
Где время в таком виде может встретиться? (Если не знаете, то скорее всего и не встретится. :)) Например, если в таблицах анализируете логи какого-нибудь сервера, где время указано в таком виде.
Что делает? Например, из числа 1655906710 делает датувремя 22.06.2022 14:05:10:
=EPOCHTODATE(1655906710)
Как сделать то же самое имеющимися функциями?
=1655906710 / (24 * 60 * 60) + DATE(1970; 1; 1)
Это потому что:
- в сутках
24 * 60 * 60секунд - датавремя в таблицах представляется на самом деле тоже числом (не раз об этом уже писали все, кому не лень)
- отсчёт в таблицах начинается с другой даты (в таблицах
0- это30.12.1899 00:00:00) - отсюда поправка+ DATE(1970; 1; 1)
Как в обратную сторону преобразовать? Из 22.06.2022 14:02:49 получим unix time, в этот раз в миллисекундах - 1655906569000:
=(DATE(2022; 6; 22) + TIME(14; 2; 49) - DATE(1970; 1; 1)) * 24 * 60 * 60 * 1000
MARGINOFERROR()
Вычисляет величину ошибки случайной выборки с учетом диапазона значений и уровня достоверности.
https://support.google.com/docs/answer/12487850
В двух словах раскидать не получится. Про эту как-нибудь потом напишем.
TOROW()
Преобразует массив или диапазон ячеек в одну строку.
https://support.google.com/docs/answer/13187459
Умеет проходиться по строкам (слева направо, сверху вниз) или по колонкам (сверху вниз, слева направо). Умеет отфильтровывать пустые ячейки и/или ошибки.
Раньше мы это делали так, проходимся по строкам:
=TRANSPOSE(FLATTEN(A1:C3))
Проходимся по колонкам:
=TRANSPOSE(FLATTEN(TRANSPOSE(A1:C3)))
С фильтрацией пустых (по строкам):
=TRANSPOSE(LAMBDA(range; FILTER(range; range <> ""))(FLATTEN(A1:C3)))
С фильтрацией ошибок (по строкам):
=TRANSPOSE(LAMBDA(range; FILTER(range; NOT(ISERROR(range))))(FLATTEN(A1:C3)))
С фильтрацией пустых и ошибок (по строкам):
=TRANSPOSE(LAMBDA(range; FILTER(range; IFERROR(range) <> ""))(FLATTEN(A1:C3)))
TOCOL()
Преобразует массив или диапазон ячеек в один столбец.
https://support.google.com/docs/answer/13187258
Делает то же самое, но на выходе колонка, а не строка.
И мы сейчас так же всё делаем, только без внешней TRANSPOSE(). Например, с фильтрацией пустых и ошибок (по строкам):
=LAMBDA(range; FILTER(range; IFERROR(range) <> ""))(FLATTEN(A1:C3))
CHOOSEROWS()
Создает новый массив из выбранных строк в существующем диапазоне.
https://support.google.com/docs/answer/13196659
Строки указываются с помощью индексов: 1, 2, 10 - первая, вторая и 10-я, остальные не нужны.
Удобно, что можно использовать отрицательные индексы: -1, -2, -10 - первая с конца, вторая с конца и т.д.
В документации не описано, но можно нужные строки указать не в виде кучи параметров, а в виде одного параметра - диапазона с номерами нужных строк:
=CHOOSEROWS(A1:C10; {1; 2; 10})
Как мы раньше это делали? Через адский VLOOKUP():
=ARRAYFORMULA(VLOOKUP({1; 2; 10}; {SEQUENCE(ROWS(A1:C10))\ A1:C10}; SEQUENCE(1; COLUMNS(A1:C10); 2);))
Если скучно, можно то же самое через HLOOKUP() повторить.
Через MAP() и INDEX():
=MAP({1; 2; 10}; LAMBDA(i; INDEX(A1:C10; i)))
Ждём, когда добавят нормальный слайсинг, где можно указать начало, конец и шаг, как у белых людей в питоне.
CHOOSECOLS()
Создает новый массив из выбранных столбцов в существующем диапазоне.
https://support.google.com/docs/answer/13197914
То же самое, только выбираются колонки.
Старые метод через HLOOKUP():
=ARRAYFORMULA(HLOOKUP({1\ 2\ 1}; {SEQUENCE(1; COLUMNS(A1:C10)); A1:C10}; SEQUENCE(ROWS(A1:C10); 1; 2);))
Через MAP() и INDEX():
=MAP({1\ 2\ 1}; LAMBDA(i; INDEX(A1:C10;; i)))
WRAPROWS()
Оборачивает предоставленную строку или столбец ячеек строками после указанного количества элементов, чтобы сформировать новый массив.
https://support.google.com/docs/answer/13184285
Полезная штука, ибо альтернативное решение значительно больше, и сложнее воспринимается:
=ARRAYFORMULA(VLOOKUP(SEQUENCE(ROUNDUP(ROWS(A1:A7) / 2); 2); {SEQUENCE(ROWS(A1:A7))\ A1:A7}; 2;))
Или через MAP():
=MAP(SEQUENCE(ROUNDUP(ROWS(A1:A7) / 2); 2); LAMBDA(i; INDEX(A1:A7; i)))
Если надо убрать #N/A (в новой функции для этого третий параметр), то VLOOKUP() надо обернуть в IFNA(), а INDEX() - в IFERROR().
WRAPCOLS()
Оборачивает предоставленную строку или столбец ячеек столбцами после указанного количества элементов, чтобы сформировать новый массив.
https://support.google.com/docs/answer/13184284
Тоже самое, только ограничение выставляется на высоту колонки, а не на ширину строки, и проходится функция по колонкам, а не по строкам, то есть сверху вниз, слева направо.
Аналоги, как обычно, почти такие же: достаточно обернуть SEQUENCE() или всю формулу целиком в TRANSPOSE():
=ARRAYFORMULA(VLOOKUP(TRANSPOSE(SEQUENCE(ROUNDUP(ROWS(A1:A7) / 2); 2)); {SEQUENCE(ROWS(A1:A7))\ A1:A7}; 2;))
Через MAP():
=TRANSPOSE(MAP(SEQUENCE(ROUNDUP(ROWS(A1:A7) / 2); 2); LAMBDA(i; INDEX(A1:A7; i))))
VSTACK()
Добавляет диапазоны вертикально и последовательно, чтобы вернуть больший массив.
https://support.google.com/docs/answer/13191461
Складывает (не в смысле суммы, а в смысле кладёт) строки диапазонов вертикально. Казалось бы, зачем нужна, если можно сделать так:
={A1:C10; D1:F10}
Нужна на случай, если количество колонок в диапазонах разное. Сложит вместе, ругаться не будет, только вместо недостающих колонок будут #N/A.
Пример (в первом диапазоне 3 колонки, во втором 2):
=VSTACK(A1:C5; A8:B11)
Тут вредный совет от разработчиков, так не надо:
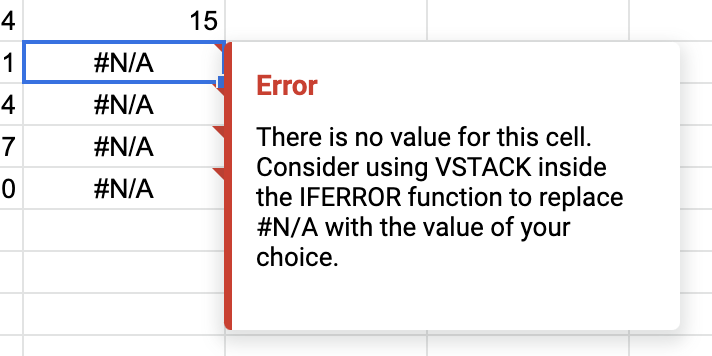
Исправляется так:
=IFNA(VSTACK(A1:C5; A8:B11))
Тут простого универсального аналога нет. Диапазоны, где не хватает колонок перед сложением надо было добивать пустыми, например, так:
={A1:C5; {A8:B11\ ARRAYFORMULA(IF(SEQUENCE(ROWS(A8:B11); COLUMNS(A1:C5) - COLUMNS(A8:B11));))}}
HSTACK()
Добавляет диапазоны горизонтально и последовательно, чтобы вернуть больший массив.
https://support.google.com/docs/answer/13190756
То же самое, но складываются стролбцы диапазонов.
Аналог такой (но только для диапазонов с равным количеством строк):
={A1:B10\ D1:D10}
LET()
Присваивает имя результатам выражения-значения и возвращает результат выражения-формулы. Выражение-формула может использовать имена, определенные в области действия функции LET. Выражения-значения оцениваются только один раз в функции LET, даже если следующие выражения-значения или выражения-формулы используют их несколько раз.
https://support.google.com/docs/answer/13190535
Функция позволяет в рамках одной формулы результатам промежуточных расчётам назначить имя и потом его использовать, чтоб не повторяться.
Вместо такого (пример условный):
=ROWS(A:A) + ROWS(A:A)^2 + ROWS(A:A)^3
Можно написать:
=LET(r; ROWS(A:A); r + r^2 + r^3)
Сейчас можно сделать то же самое с помощью LAMBDA():
=LAMBDA(r; r + r^2 + r^3)(ROWS(A:A))
Но тут сложности.
Во-первых, смотреть то в хвост, где значение определяется, то в середину, где используется, - утомительно. С LET() проще: определения промежуточных переменных идёт слева направо, а в конце использование.
Во-вторых, если расчётов несколько и, например, второй зависит от первого, то надо будет использовать вложенные LAMBDA(), это становится нечитаемым:
=LAMBDA(a; LAMBDA(b; как-то используем a и b)(тут считаем b через a))(тут считаем a)
С LET() это будет выглядеть так:
=LET(a; тут считаем a; b; тут считаем b через a; как-то используем a и b)
Для всего этого добра сделали таблицу с примерами. Зелёным отмечены ячейки с новыми формулами, жёлтым - со старыми.
На момент написания до нас не доехали только EPOCHTODATE() и LET(). С остальными можно поэкспериментировать (делайте копию).
На этом всё. Спасибо за внимание.
Правильный канал о Таблицах (Google Sheets): @google_sheets
Чат канала: @google_spreadsheets_chat